CNNアンサンブルはいつどのように用いるべきか?
3つの要点
✔️ パラメータ数が同一のとき、単一モデルとアンサンブルモデルのどちらが優れているか検証
✔️ CNNによる画像分類タスクについて、様々な設定で実験・検証
✔️ アンサンブルモデルが全体として優れた性能を示すことを実証
More or Less: When and How to Build Convolutional Neural Network Ensembles
written by Abdul Wasay, Stratos Idreos
(Submitted on 29 Sept 2020 (modified: 26 Jan 2021))
Comments: Accepted to ICLR2021.
Subjects: ensemble learning, empirical study, machine learning systems, computer vision
はじめに
深層学習モデルの性能を向上させようと思ったとき、最もシンプルな方法はモデルサイズを大きくすることです。
ですがこのとき、多くのパラメータを持つ一つのモデルを利用するべきか、それとも比較的少ないパラメータを持つ複数のモデルのアンサンブルにするべきか、どちらがより優れているでしょうか?本記事で紹介する論文では、特にCNNについて、学習時間・推論時間・メモリ使用量などの様々な観点から、アンサンブルと単一モデルのどちらを利用すべきかという問題に取り組んでいます。
手法
アンサンブルと単一モデルの比較は、以下に説明する方針・手法からなされます。
公平・公正な順位付けのための根拠
アンサンブル/単一モデルの比較として、同じ数のパラメータを持つアーキテクチャの比較を行います。ここでパラメータ数ではなく、その他の指標(学習時間、推論時間、メモリ使用量等)を用いなかった理由は二つ挙げられます。
- ネットワーク内のパラメータ数は、その他の指標と正比例関係にあるため。
- パラメータ数は、使用するハードウェア等に依存せず、ネットワークの仕様から正確に計算できるため。
次に、単一/アンサンブルネットワークアーキテクチャをどのように設計し比較実験を行うかについて説明します。
単一/アンサンブルアーキテクチャについて
はじめに、単一CNNアーキテクチャは$S^{(w,d)}$で表されます。このとき、$w$はネットワークの幅を、$d$は深さを、$|S|$はパラメータ数を表します。
また、$S^{(w,d)}$はニューラルネットワークアーキテクチャのクラス$C$に属するとします。ここで、アンサンブルネットワークは$E=\{E_1,...,E_k\}$で表されます。このとき、$E_1,...,E_k \in C$かつ$|E_1|+...+|E_k|=|S|$となります。つまり、アーキテクチャのクラスは単一ネットワークのそれと同一であり、パラメータ数の合計は同じです。
また実験では、全てのアンサンブルネットワークアーキテクチャは同一($E_1=...=R_k$)であり、パラメータ数も等しく($=|S|/k$)設定されています。このような設定のもと、単一ネットワークとアンサンブルネットワークの比較を行います。
深さ/幅等価アンサンブル
CNNアンサンブルネットワークアーキテクチャは、深さ等価/幅等価の二種類の方針から決定されます。これは以下の図で示されます。
簡潔に言えば、深さ等価アンサンブル設定では、アンサンブルネットワークの深さは単一ネットワークのそれと同じ深さ$d$となります。幅等価アンサンブル設定では、アンサンブルネットワークの幅が単一ネットワークのそれと同じ幅$w$となります。
このとき、深さ等価設定での幅$W^{\prime}$は、パラメータ総数が$|S|$を超えない範囲内での最大値に設定されます。幅等価設定での深さ$d^{\prime}$も同様に、パラメータ総数が$|S|$を超えない範囲内での最大値に設定されます。これは数式としては以下のように表されます。
$w^{\prime}: k \cdot |E^{(w^{\prime},d)}_i| \leq |S^{(w,d)}| \leq k \cdot |E^{(w^{\prime}+1,d)_i}|$
$d^{\prime}: k \cdot |E^{(w,d^{\prime})}_i| \leq |S^{(w,d)}| \leq k \cdot |E^{(w,d^{\prime}+1)_i}|$
全体として、同一のネットワークアーキテクチャのクラス$C$に属する(i)単一ネットワーク$S^{(w,d)}$、(ii)$k$個の幅等価アンサンブル$S^{(w,d^{\prime})}$、(iii)$k$個の深さ等価アンサンブル$S^{(w^{\prime},d)}$について比較実験を行います。
実験
実験設定
・データセット
実験に用いるデータセットは以下の通りです。
- SVHN
- CIFAR-10
- CIFAR-100
- Tiny ImageNet
- ダウンサンプリングされたImageNet-1k
・アーキテクチャ
実験に用いるCNNアーキテクチャは以下の通りです。
- VGGNet
- ResNet
- DenseNet
- Wide ResNet
・評価指標
単一ネットワークとアンサンブルネットワークの比較のため、以下の五つの観点から評価を行います。
- 汎化精度(generalization accuracy)
- エポックあたりの学習時間(training time per epoch)
- 指定された精度に到達するための時間(time to accuracy)
- 推論時間(inference time)
- メモリ使用量(memory usage)
・詳細な設定
アーキテクチャのハイパーパラメータ等は以下の通りです。 実験フレームワークにはPyTorchを、実行にはNvidia V100 GPUを利用しています。 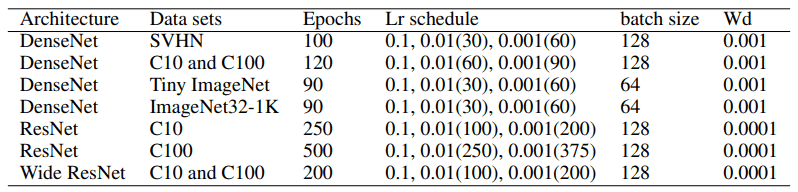
結果
精度の比較
・EST(Ensemble Switchover Threshold)の発生
実験の結果、リソースがある程度の閾値を超えると、深さ/幅等価アンサンブルの両方が単一ネットワークを上回るという現象が確認されました。
論文では、これをEST(Ensemble Switchover Threshold)と名付けています。これは以下の図の通りです。 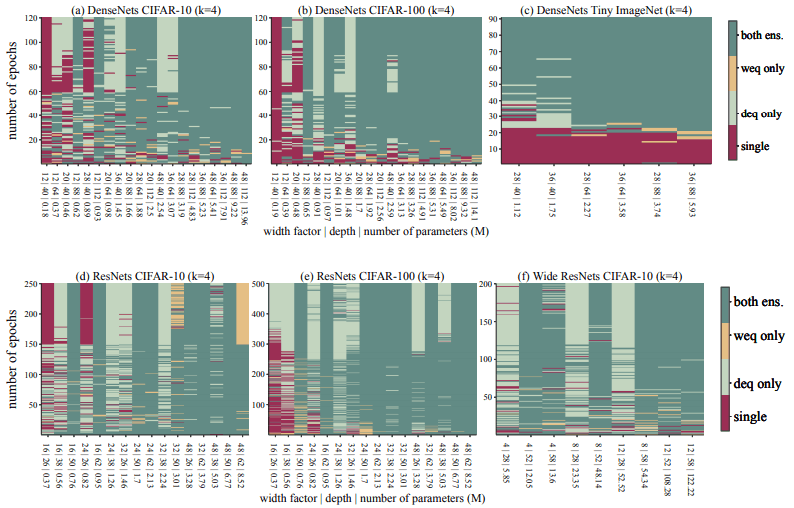
この図では、単一ネットワーク(single)、深さ等価(deq)・幅等価(weq)アンサンブルの内、どれが優勢であるかを視覚化しています。パラメータ数がある程度増大する(右方向)と、アンサンブル手法が優勢になることがわかります。
また、DenseNetモデルにおけるテストエラー率は以下のようになります。
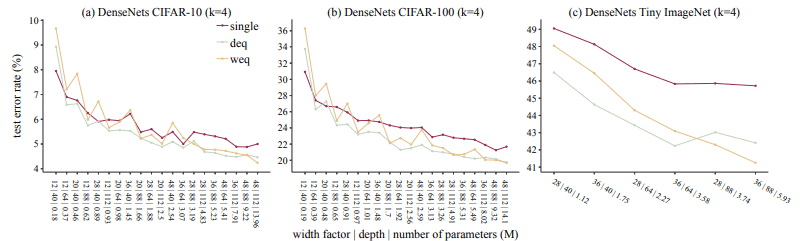
こちらでも同様に、パラメータ数がある程度大きくなると、全体としてアンサンブル手法が優勢となっています。このESTは、リソースが低~中程度(パラメータ数1M~1.5M程度、訓練エポックの半分以下の期間)で発生しています。そのため、リソースが大量に存在していなくても、アンサンブルの方が有用となる可能性が十分にあることが示されたと言えます。
総じてこれらの結果は、非常に広い範囲のユースケースにおいて、単一ネットワークをアンサンブルが上回りうることを示しています。
より効果的なアンサンブルのために
実験の結果、アンサンブルモデルを有効に用いるための知見として、以下の三つが観察されています。
1.アンサンブルは、データセットが複雑であるほど効果的となる
学習データセットが複雑であるほど、ESTは原点に近く(エポック数・パラメータ数ともに小さく)なります。
2.アンサンブルネットワーク数の増大は十分に大きいパラメータ予算のもとで有効となる
以下の図で示される通り、アンサンブルネットワークの数($k$)を大きくするほど、ESTは右(より多くのパラメータ数を必要とする)方向に移動してしまいます。
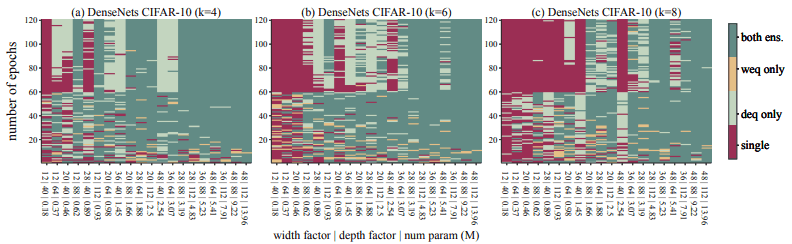
そのため、アンサンブルネットワーク数を増やしたい場合、パラメータ数も十分に確保しなければ精度の向上は見込めないと考えられます。
3.深さ等価アンサンブルは幅等価アンサンブルよりも優れた精度を示す
深さ/幅等価アンサンブルについて、全体として精度が高いのは深さ等価アンサンブルであることが分かりました。これは、最新のCNNアーキテクチャが、層の深さが増すほど精度が向上するように設計されていることに起因しているとみられます。
時間面の比較
・訓練時間の比較
単一ネットワークモデルの精度を達成するのにかかる訓練時間は以下の図の通りです。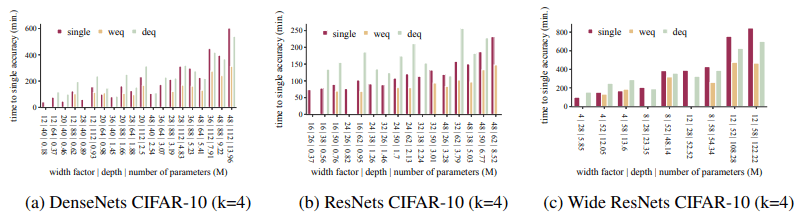
(バーが存在しない場合は、単一ネットワークモデルの精度に到達できないことを示しています。)
全体として、アンサンブルは単一ネットワークモデルの精度をより高速に達成しています(実験では1.2倍から5倍)。また、エポックあたりの訓練時間は以下の通りです。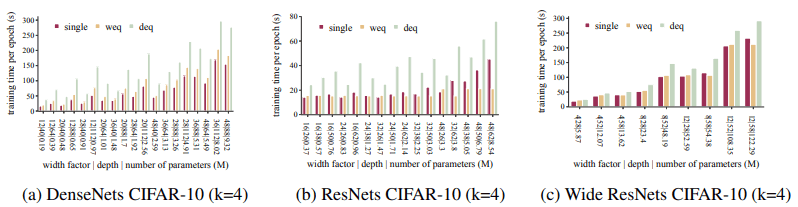
アンサンブルは深さ/幅等価のどちらの場合でも$k$個のネットワークを学習するため、エポックあたりの学習には時間がかかります。
このとき、深さ等価アンサンブルは幅等価アンサンブルと比較して、約二倍ほどにエポックあたりの学習時間が増大します。また、収束までにかかる時間について、アンサンブルは単一ネットワークよりも高速に収束する(ことが確認されました。
これは、アンサンブルの全てのネットワークが、単一ネットワークよりも小さいことに起因しているとみられます。総じて、アンサンブルは単一ネットワークと比べて訓練時間を多く要するということはなく、アンサンブルは単一ネットワークの精度をより少ない訓練時間で達成できることが示されました。
・推論時間の比較
以下の図では画像あたりの推論時間を示しています。 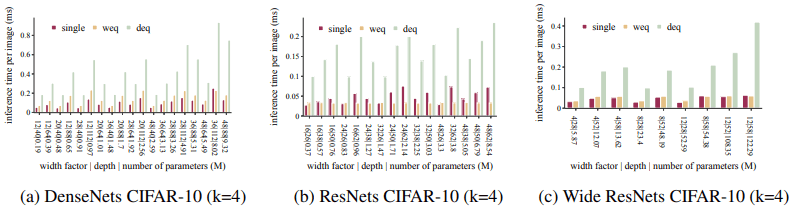
推論時間については、エポックあたりの訓練時間と同様の傾向がみられます。つまり、幅等価アンサンブルは単一ネットワークと同等の推論速度を示す一方で、深さ等価アンサンブルはかなり遅くなっています。
メモリ使用量の比較
各設定でのメモリ使用量の比較は以下の通りです。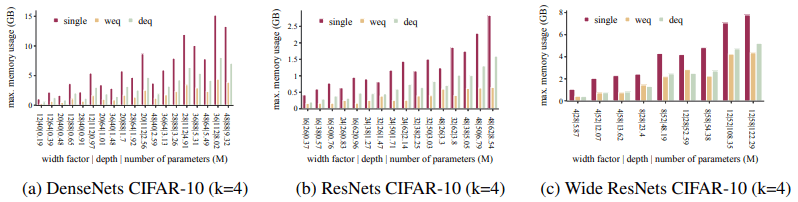
これは、先述したハイパーパラメータ設定でGPUが必要とする最小メモリ量を示します。この結果は、アンサンブルネットワークの訓練時に要するメモリ量は、$k$個のネットワークのうち一つを訓練するのに必要なメモリと同じであることに起因しています。このメモリ効率は、バッチサイズを大きくすることができること、メモリ制約の厳しい環境下での学習に有効であるなどの利点が存在します。
まとめ
本記事では、アンサンブルを利用すべきか否かという判断に関する分析について紹介しました。
総じて、パラメータ数が同一のとき、単一モデルよりもアンサンブルモデルのほうが高い精度を発揮すること、より高速に学習できること、同等の推論が可能であること、必要なメモリ量が大幅に削減できることが示されました。
実験で検証された内容にはいくつかの制限(アンサンブル内のネットワークが同一のものであること、画像分類以外の検証はされていないこと等)がありますが、非常に有意義な情報を提供してくれる研究であると言えるでしょう。





この記事に関するカテゴリー






