経済・金融市場予測でAIはどう使われる?ネットワークトポロジーベースの企業パフォーマンス予測を紹介!
3つの要点
✔️ 企業の倒産リスク、パフォーマンス予測に関する論文
✔️ 製品類似度に基づくネットワークのトポロジカルな特徴を使用
✔️ 財務情報に組み合わせて使用することで精度向上
Topology of products similarity network for market forecasting
written by Jingfang Fan, Keren Cohen, Louis M. Shekhtman, Sibo LiuJun MengYoram LouzounShlomo Havlin
(Submitted on 28 Aug 2019)
Comments: Applied Network Science volume 4, Article number: 69 (2019)
Subjects: Machine Learning (cs.LG); Machine Learning (stat.ML)
はじめに
経済予測の主要な課題の一つである、金融市場におけるリスクの検出と予測に関する論文の紹介になります。
2019年投稿と、少し古い論文であり、技術自体に新しさはありませんが、AI-Scholarであまり取り上げてきていない分野であったので今回紹介してみようと思います。
AIをやっている人で株や経済予測に興味がある人は多いんじゃないかと思いますが、金融・経済予測の分野でAIがどのように用いられているのか、どのようなデータが用いられているかなどの雰囲気がわかるかと思います。
ネットワーク科学について
ネットワーク科学は、伝染病の流行の予測や、都市開発の予測、気候の異常現象の予測、科学者の影響力の変化など、多くの自然現象や技術現象の予測に利用されてきており、多くの実世界システムの研究において有用なツールであることが実証されています。
また、金融の分野においても、ネットワーク科学のアプローチが適用されています(金融システムの不安定性の記述、金融ネットワーク構造とリスクの伝染による障害との関係の研究等)。
構築されたネットワークについて、以下のような様々な指標を調べることで分析を行います。
- 局所的な特徴
- 基本的にサブグラフの頻度をカウントするものである
- 例:次数、小規模モチーフ、クラスタ係数など
- 階層性指標
- 基本的にネットワークが何らかの階層的なメカニズムに従って順序付けられていた場合のネットワーク内のノードの位置を測定する
- 中心性指標
- 各ネットワークの特徴は異なる企業の製品の類似性の間の異なるタイプの対応関係を反映している
- 例:近接中心性、K-cores、K-shellなど
また、ここ数年ではネットワークと機械学習を組み合わせて、ノードやネットワーク全体のクラスを予測するような取り組みも行われています。ネットワークからの特徴量生成の方法としては、node2vecなどの面白いアイデアも出ています(以下例:詳細は省略します)。
- ネットワークの隣接行列の固有ベクトル
- DeepWalk
- スペクトルベース畳み込み
- node2vec
- 等々
ここで、特徴量生成で重要な観点として、グラフを単に類似性の尺度として用いるのではなく、トポロジーのより複雑な特徴を用いることが重要です。既存の多くのアプローチでグラフのトポロジカルな特徴が無視されてきていますが、最近ではグラフから得られるトポロジカルな特徴がノードとエッジの特性を非常に良く表しており、クラス分類問題に有用であることがわかっています。著者らもトポロジーに基づく手法を用いた企業のパフォーマンス予測を提案しています。
提案手法
それでは提案手法の説明に入っていきます。著者らはテキスト分析、ネットワーク理論、トポロジーベースの機械学習を組み合わせた手法を提案しています。
具体的な流れとしては、まず「SEC Form 10-K」に記載されている企業の製品説明書をテキストベースで分析し、企業間の製品類似性のネットワークを構築します。企業をネットワークのノードとみなし、企業の製品間の類似度はネットワークのリンク(強度)で表します。次に、構築されたネットワークのトポロジカルな特徴を用いて、機械学習による企業のパフォーマンスおよび倒産リスクの予測を行います。
まずはどのようなデータを使用しているのかについて説明します。
データ:Product similarity data
データとしては、米国証券取引委員会(SEC)が取りまとめているForm 10-Kと呼ばれる企業の年次報告書が有用です。本論文では、その中でも企業の出している製品説明書を使用し、テキストベースの分析を行うことで製品類似性を算出しています。
具体的には、まずForm 10-Kから各年で製品説明に使用されたユニークな単語のリストを取り、各年のデータベースを構築します。次に、各企業の製品説明からテキストを取り出し、その単語の使用状況を要約(単語が使われている場合に1, そうでない場合に0)した2値のN次元ベクトルを構築します。企業ごとにBowを作っているようなイメージです。こうして得られたベクトルを正規化し、企業間でコサイン類似度を取ることで類似度を算出しています。なお、本研究では18年間(1996年から2013年まで)のデータを使用してます。
従来ではSICコードのような伝統的な産業分類が参考にされてきていましたが、これは時間が経っても変わらない上、実際には企業は異なるセクターに属する様々な製品セグメントを持つことができるため、割り当ては正確とは言えません。そういった点から著者らは提案した類似性指標が優れているとも主張しています。
データ:External financial data
製品の類似性とは別に、金融変数を構築するためのデータについても紹介されています。
例えば、CRSP(Center for Research in Security Prices)からS&P500指数の毎日の終値をダウンロードすることで、市場全体のダイナミクスを測定するのに利用できます。また、観測された企業特性の範囲をコントロールするために、いくつかの企業固有の変数を用いて企業規模を求めています。具体的には、FamaやFrenchらの研究で提案されているように、企業規模は以下の指標の時価総額の合計であると仮定しています。
- 時価純資産倍率(Book-to-Market Ratio)
- 時価純資産に対する簿価の割合であり、企業の成長機会を評価できる
- レバレッジ
- 長期債務とその他の債務(流動負債)の、長期債務、流動負債中の債務、および株主資本の合計に対する比率で定義される資本構造の指標
- 収益性
- 遅延した総資産に対する特別項目前の利益として定義
- 前年のリターン
- 過去1年間の株式のリターン
- 投資
- 総資産の対前年比成長率
- 流動性
- 企業の流動性の指標
- Altman Z-score
- デフォルトリスクの指標
それぞれの指標の求め方の詳細は論文の参考文献に記載があります。また、データはCompustat databaseからダウンロードできます(http:/www.compustat.com)。
Product similarity network の構築
それでは実際のネットワーク構築の説明に入ります。各年について、前述の製品類似性に基づいて重み付きの無向ネットワークを構築します。ノードに各企業、リンクにノード間の類似度が対応し、その類似度$w$を持ちます。ここで、リンクは閾値(ここでは$10^{-4}$)よりも大きな類似度の場合に張られるようにします。
下図は、このようにして2012年版の製品の類似性ネットワークを示しています。ノード数は3925、平均次数は94.78になりました。なお、色は特定のシェルを表しています。
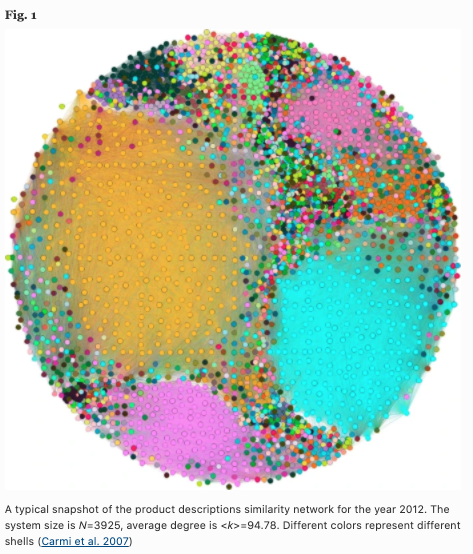
ネットワークのトポロジカルな特徴量の作成
ネットワークのトポロジカル測定は、企業の将来の利益や倒産の確率を予測するために使われてきています。著者らはRosenらやNaamanらの手法に基づき、一連のトポロジカルな特徴を表すベクトルを各ノードについて計算し、トポロジカルネットワーク属性ベクトル(NAV)を生成します。NAVには以下の特徴が用いられています。
- 次数
- 中間中心性
- ノードの中心性の尺度となるもので、他の多くのノード間にブリッジを形成するものを重要とみなす
- 近接中心性
- こちらもノードの中心性の尺度で、自分以外の全てのノードから自分までの最短経路長の合計値が小さいほど大きくなる
- 距離分布モーメント
- ダイクストラのアルゴリズムを使用して、各ノードから他の全てのノードまでの距離の分布を計算し、この分布の1次のモーメントと2次のモーメントをとる
- フロー
- このノードと他のすべてのノード間の有向距離と無向距離の比率として定義
- ネットワークモチーフ
- 接続された小さなサブグラフのパターンで、Itzchackアルゴリズムの拡張(無向グラフへの拡張)を使用して算出する
- 各ノードについて、このノードが参加するモチーフの頻度を計算する
- K-core
- 次数k以上の頂点のみを含む最大部分グラフ
ネットワークの分析
それでは、提案手法で得られたネットワークの特性を確認するために、著者らによって行われたいくつかの分析結果を紹介していきます。
企業間のリンクの強さの傾向について
各年のネットワークのリンクの強さwの確率密度関数$p(w)$を考えます。以下の図は6つの年の結果を示していますが、各年で同じ傾向であり、近似的に指数分布に従っていることがわかります。
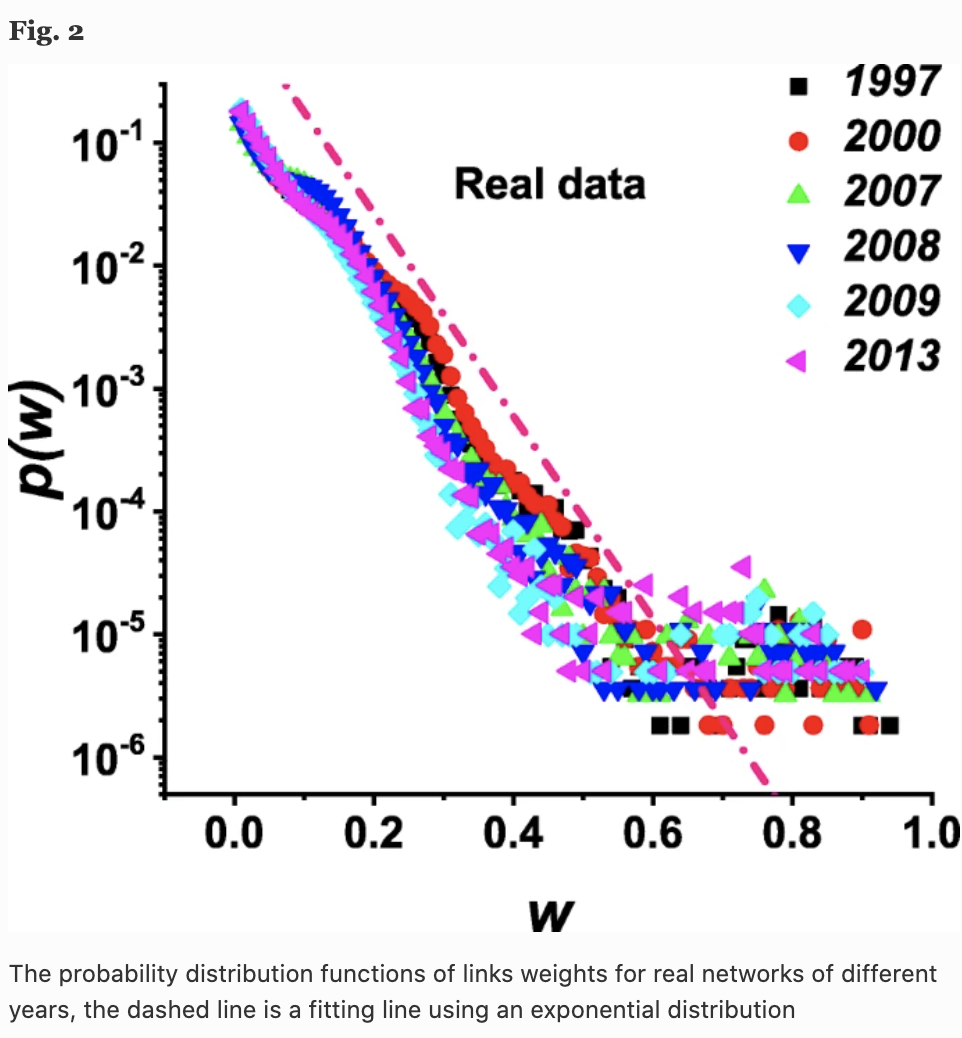
なお、製品の類似性の値は、製品市場のシナジー効果やM&Aの競争を反映している可能性があり、$w$が高いほど、2つの企業が高い競争関係にあるか、協力的な関係にあることを意味している可能性があります。
ノードの加重次数
以下のように定義される加重次数を算出する。
$$s_i = \sum_{j = 1}^N a_{ij}w_{ij}$$
ここで、$a_{ij}$は隣接行列、$s_i$はノード$i$の強さをその接続の総重量で定量化したものです。製品類似性ネットワークの場合、これはネットワークにおける企業$i$の重要性や影響力を反映するものとしています。下図をみると、次数$k$のノードの強さ$s(k)$は、$k$の値に応じて$s \sim k^{\beta}$に従って増加することがわかります。
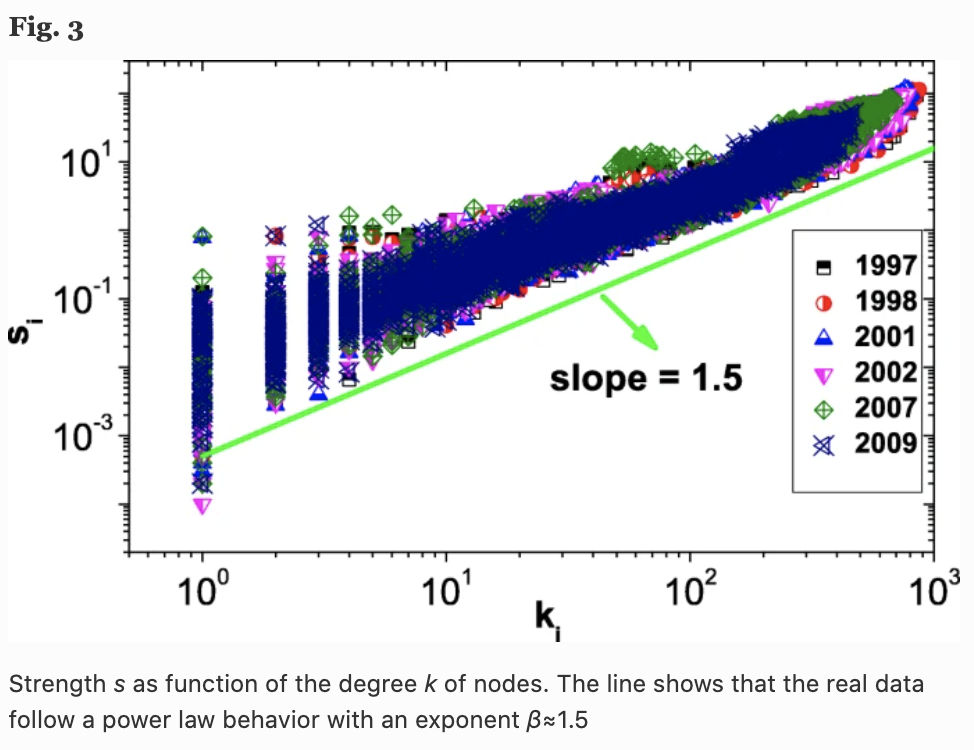
実際にはこの冪乗則$\beta$の値は約1.5になることもわかり、これはノードの強さがその次数よりも早く成長することを意味しています。つまり、接続度の高いノード(企業)のエッジの重みはより高い値を持つ傾向があるということを示しています。
クラスタ係数
重み付きネットワークの場合、ノード$i$のクラスタ係数は、サブグラフのエッジの重みの幾何平均として以下のように定義されます。各ノードについてクラスタ係数を算出し、さらに各年のネットワークごとに平均クラスタ係数を求めて分析を行います。
$$c_i = \frac{1}{k_i(k_i - 1)} \sum_{j,k} (\hat{w_{i,j}}\hat{w_{i,k}}\hat{w_{j,k}})^{\frac{1}{3}}$$
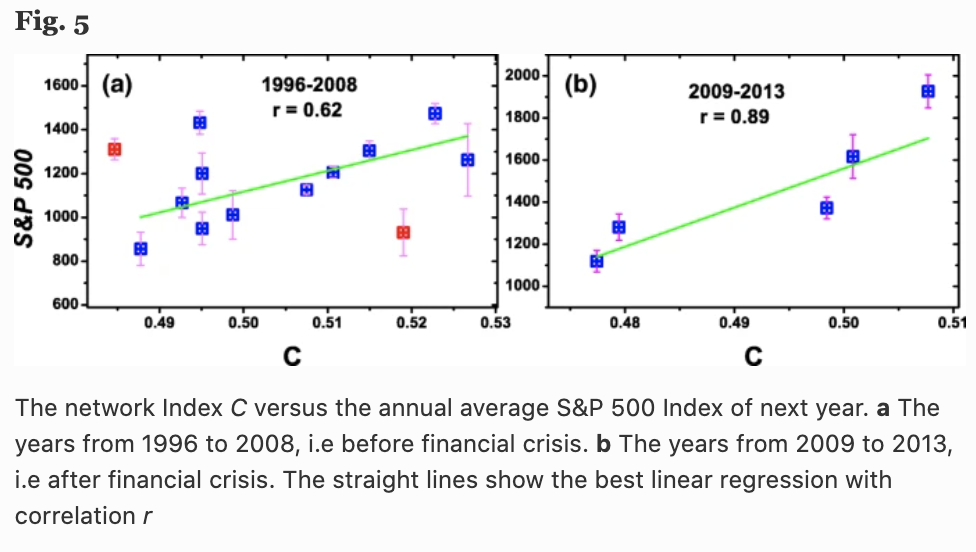
下図の(a)は、平均クラスタ係数$C=\frac{1}{N} \sum_{i=1}^N c_i$の時間(年)経過に伴う変化を、(b)はS&P500指数を示しています。面白いことに、平均クラスタ係数$C$(1年先)とS&P 500 Indexの挙動には高い相関関係があることがわかります(Fig.5)。
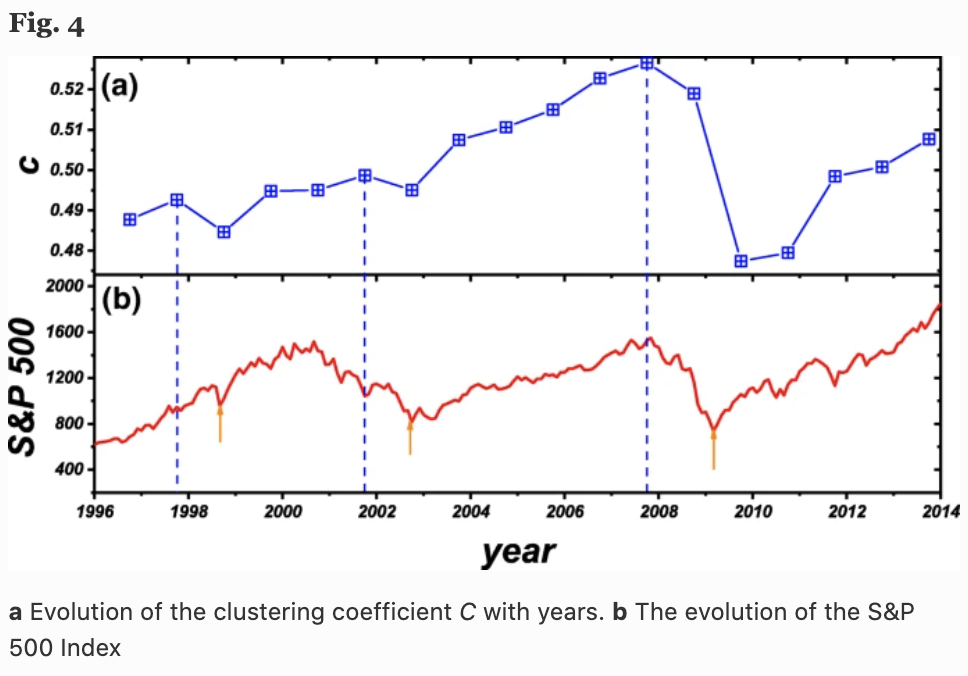
ここで、Fig4では3つの局所的な$C$の最大値(青の破線)と3つの局所的なS&P 500の最小値(赤の矢印線)がみられますが、これは3つの金融危機(アジア金融危機、ドットコムバブル、リーマンショック等)を表しています。$C$の局所的最大値は常にS&P 500の最小値の1年前となっています。このことから、ネットワークの平均クラスタ係数$C$は翌年の株式市場のリターンを予測するのに役立つ可能性があります。
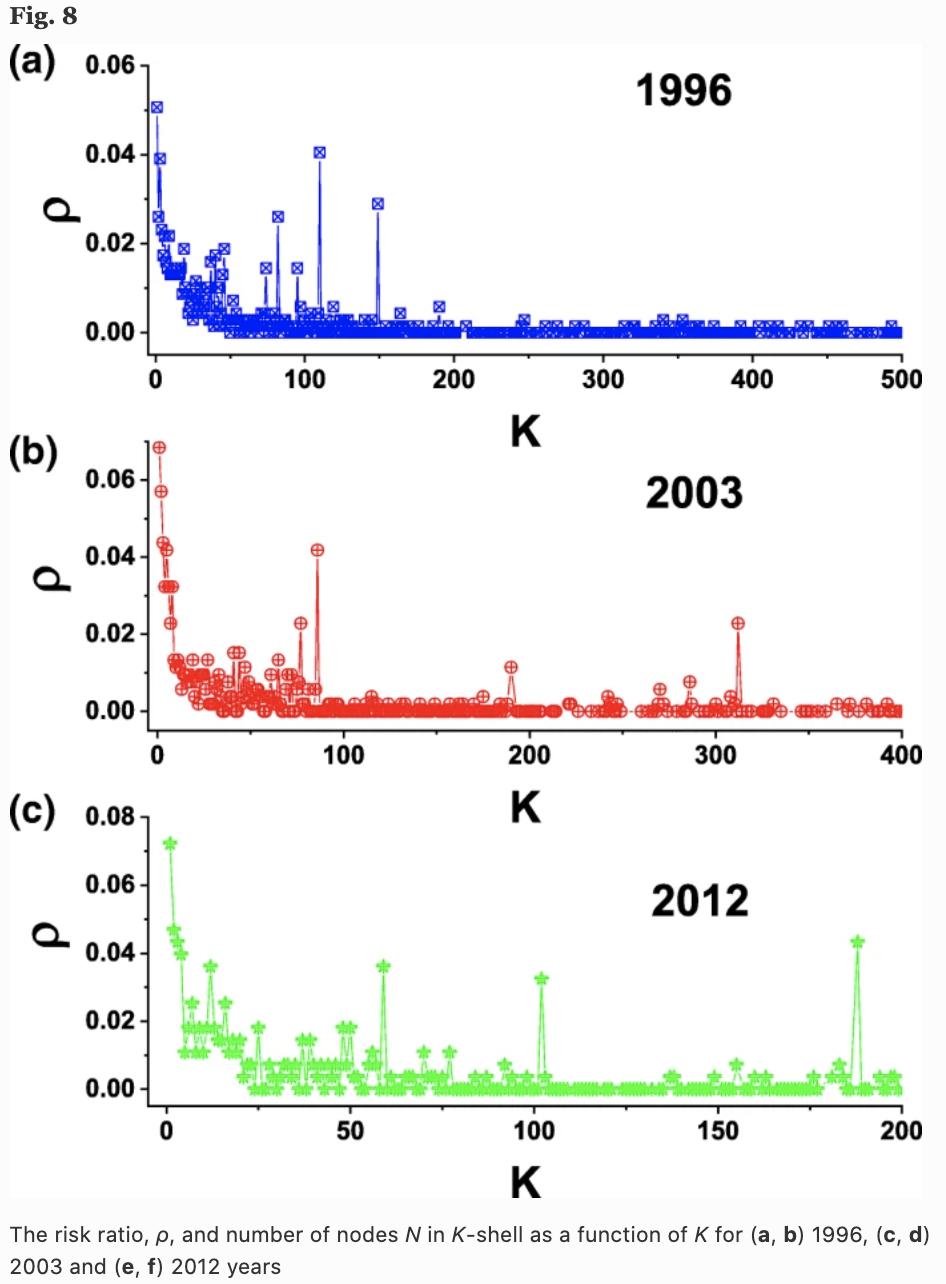
k-shell構造の分析
ネットワークのトポロジカルな特徴が重要であることを示すために、k-shell構造の分析も行っています。下図は1996、2003、2013年の3つの年について、各次数のシェルで翌年に消失した企業の比率$p$を表しています。より外側に属する企業ほど倒産等のリスクが高いことがわかります(良く売れる製品は多くの企業で生産されるという意味では当たり前かもしれませんが)。
実験
ここまででネットワークの特性の紹介が終わりました。次に、構築したネットワークのトポロジカルな特徴を使用して、実際にトレーニングを行って性能の検証を行っています。
実験設定
ある年のネットワークのうち、70%のノードをトレーニングデータセット、残りの30%をテストセットに分割する。各ノードについてNAVが算出されており、さらにその企業が翌年に倒産(および合併や民営化)したかどうか、翌年のリターンが上位5%以内(Top)であったかどうかのラベルが付与されます。これらのラベルをランダムフォレストで学習し、ランダムの場合(AUC:0.5)と比較して良くなるかを検証します。
実験結果
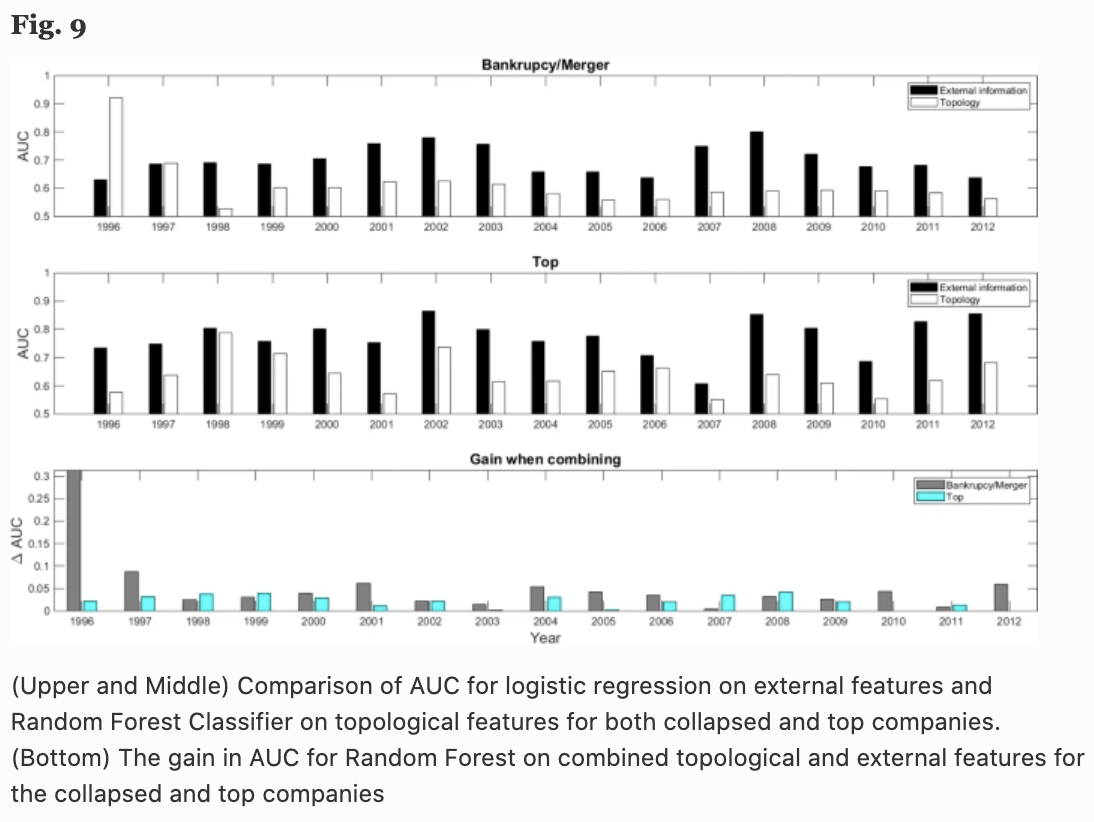
Fig.9の上段は倒産および合併のAUC、中段は翌年リターンが上位5%以内かどうかを予測したAUCを表しています。提案したネットワークのトポロジー情報は、計測した17年間全てにおいて、ランダム予測の場合(AUC: 0.5)より優れていることがわかります。
また、比較のためネットワークを使わずに、標準的な財務指標である企業規模、収益性、前年リターン、投資額、流動性、レバレッジ、book-to-market ratio、Altman Z-scoreに基づくロジスティック回帰による予測した際のAUCも載せています(黒い棒グラフ)。
これらを見るとダメな結果に思えてしまうかもしれませんが、製品類似度ネットワークだけでは流石に上述の財務指標による予測には劣ってしまいます。ただし、Fig.9の下段は前述の財務指標に製品類似度ネットワークのトポロジカルな特徴を組み合わせた場合のAUCの増加量を示していますが、ほぼ全ての年、カテゴリーで有意に精度向上が見られます。つまり、著者らの提案したネットワークのトポロジー情報が、将来の倒産やリターンの予測に重要な役割を果たし、従来のロジスティック回帰による方法を補完できることを示唆しています。
また、Fig.9では倒産と合併および民営化を同一のラベルで扱っていますが、同じノード(企業)の消失でもこれらは異なる意味を持つため、倒産と合併を別のカテゴリとして分類する実験も行っています(Fig.10)。
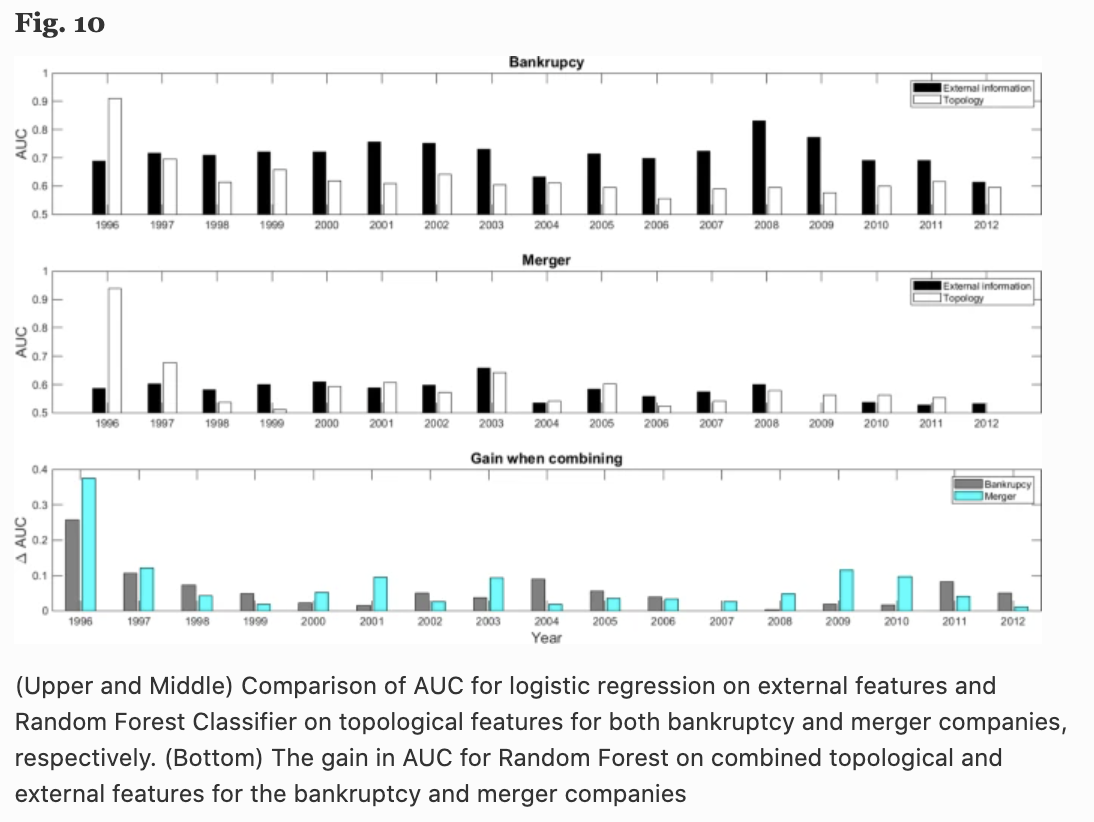 この結果から、倒産の場合は財務情報などの企業の内部情報が重要で、合併の場合はトポロジーも財務情報もどちらも重要であることがわかります。ただ、どちらの場合でもトポロジー情報を組み合わせた方が結果が良くなることがわかります。
この結果から、倒産の場合は財務情報などの企業の内部情報が重要で、合併の場合はトポロジーも財務情報もどちらも重要であることがわかります。ただ、どちらの場合でもトポロジー情報を組み合わせた方が結果が良くなることがわかります。
以上の結果から、製品類似度から構築したネットワークのトポロジカルな特徴は、企業の将来のパフォーマンス予測において有用であることがわかります。
まとめ
経済・株価予測の分野で行われている面白い手法を紹介してみました。今回はテキスト解析とネットワーク科学、機械学習を組み合わせた手法でしたが、これ以外にもこの分野はあらゆるデータや手法を扱う総合格闘技のような感じになっていて、NLPやCV、ディープラーニング、強化学習などのより先進的な手法を組み合わせることでもっと面白いアイデアも出てくるんじゃないかと思います。アイデア次第では色々とやりようがあり、非常に面白いテーマだなと感じました。
面白いアプローチがあればまた紹介してみたいと思います。
レシピ
Axrossレシピに株価周りに関する実践レシピが公開されています。




この記事に関するカテゴリー






