
注釈付きデータセットの生成に革新をもたらすGANを用いた画像生成手法
3つの要点
✔️ DatasetGANは、詳細なアノテーション付きの画像を生成するためのツールである。
✔️ 人間が行うのはごく少量の画像(16枚)に対する詳細なアノテーションを付与のみであり、これで無限のアノテーション付きデータセットを生成できる。
✔️ 生成された画像で半教師あり学習を行ったところ、完全教師あり学習と同等の性能を達成した。
DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort
written by Yuxuan Zhang, Huan Ling, Jun Gao, Kangxue Yin, Jean-Francois Lafleche, Adela Barriuso, Antonio Torralba, Sanja Fidler
(Submitted on 13 Apr 2021 (v1), last revised 20 Apr 2021 (this version, v2))
Comments: Accepted to CVPR 2021 as an Oral paper
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
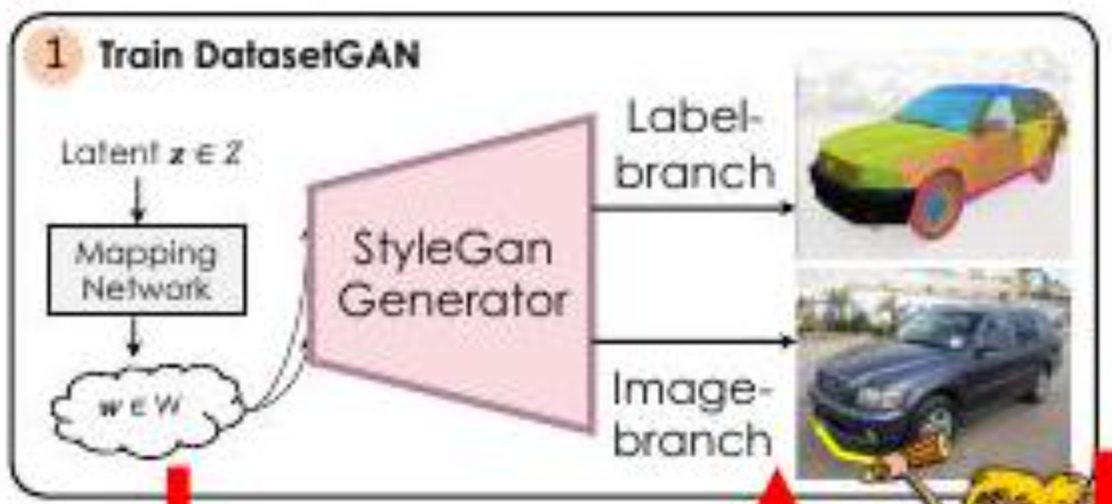
はじめに本論文の核心部を示します。上の図に示すように、StyleGANによってセグメンテーション画像と通常の画像(車)が生成されます。これにより、「アノテーション付きの画像を無限に生成でき、それらのデータセットを使って分類、識別等を行うことができる」というのが本論文の主張です。
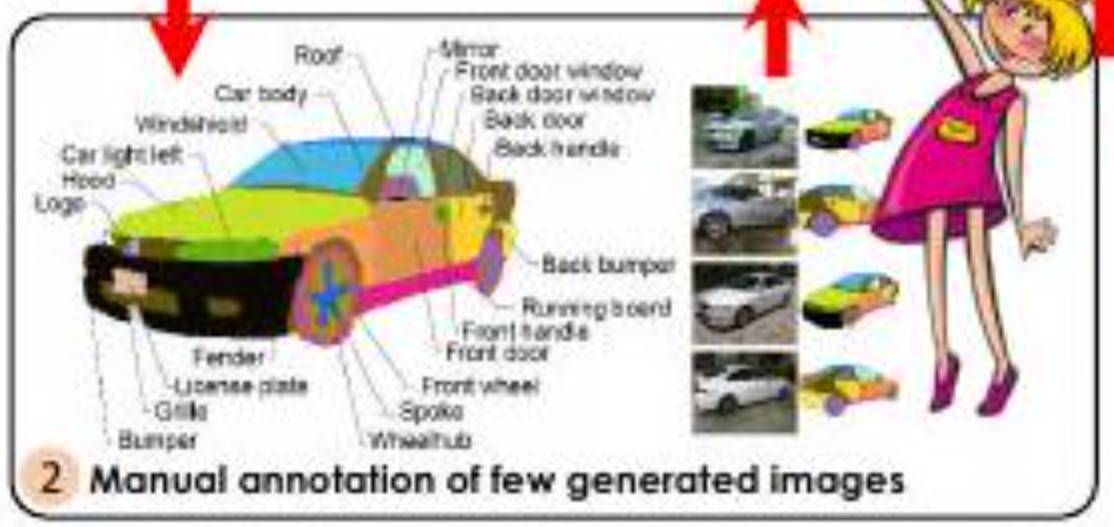
なおかつ手動のアノテーションは少量で良いことも特徴です。論文中では16枚の画像にアノテーションを行うのみで、アノテーション付き画像を生成することに成功しています。
加えて、上の図に示すようにアノテーションが詳細です。車のパーツ(フロントライト、パンパー、グリル等)ごとにアノテーションが付与されています。このように詳細な(高品質な)アノテーションを付与することは、時間も人手もかかります(つまりお金がかかります)。本論文では時間、人、金を削減できるという利点が繰り返し述べられています。
アノテーションが無い、あるいは少ない場合の一般的な解決法
データ合成を利用する方法
3DCGを利用して、アノテーション付き画像(データセット)をつくる研究や、GAN(Generative Adversarial Network)でデータセットを生成する研究が知られています。なお本研究でもGANを利用していますが、先行研究では大規模なラベル付きデータセットを前提としていました。
半教師あり学習
セグメンテーションネットワークを利用する場合、このネットワークをアノテーションの生成器と考えることができます。このネットワークは、少量の教師(手動アノテーション)でより良いセグメンテーションを学習します。これをアノテーションのついていない画像に利用することで、疑似ラベル(疑似セグメンテーション)を得ることができます。
セグメンテーション画像を生成する点では本論文と似ていますが、大きな違いは元画像です。先行研究では未ラベルの元画像を用意する必要がありますが、本研究ではその画像すらも生成してしまっています。
対照学習
対照学習は、ある画像のペアが似ているかどうかを学習する教師なし学習法です。例えば、1つの画像を2つに分割し、これをペアとします。元画像が同一であるため、このペアを同一クラスと考えます。逆に、無作為に選ばれた2つの画像からなるペアは別クラスと判断されます。対照学習では、ペア画像が同一クラスかどうかを学習することで、画像の特徴を獲得します。
さらに画像の分割(パッチ)を細かくしたり、アノテーション付き画像で微調整(fine-tuning)することで対照学習をセグメンテーションタスクに適用することが可能です。
本研究の提案手法
StyleGANとは

本論文では、StyleGANを利用して画像とそのセグメンテーション画像(= アノテーション画像)を生成しています。理解のためにまずは、StyleGANについて説明します。
GANは、2つのモデルが競合することで特定のタスクを行います(今回は画像生成)。2つのモデルはそれぞれ、画像を生成する側(生成器)とその画像が生成されたものかを見破る側(識別器)です。これら2つを競合させることで、生成器はよりリアルな画像、つまり生成画像であることが見抜かれない画像を生成するようになります。
生成器には、正規分布からつくられたランダムな数値からなるベクトル(潜在変数)が入力されます。本論文では、$z \in Z$と書かれています。このベクトルに変換を繰り返し、最終的には画像データを示すテンソルになります。
潜在変数$z$は、マッピング関数(mapping function)と呼ばれるネットワーク(CNNやMLP)に入力されることで、変換されます。この変換されたベクトルを中間潜在変数$w$と呼びます。より正確に言えば、生成器への入力は$w$であり、その後に続くアップサンプリングの過程が生成器と呼ばれています。
目的のサイズまでアップサンプリングされたベクトル(テンソル)を$S$と表します。
ここまでが生成器の概要です。StyleGANではさらに$z$から$w$への変換方法が$k$個あります。その結果生じる$k$個のベクトル$w_{1}, w_{2}, w_{3}, \dots, w_{k}$がStyleと呼ばれます。したがって、$k$個のスタイルからは$k$個のアップサンプリング後のテンソル$S_{1}, S_{2}, S_{3}, \dots, S_{k}$が生成されます。
本手法のポイント
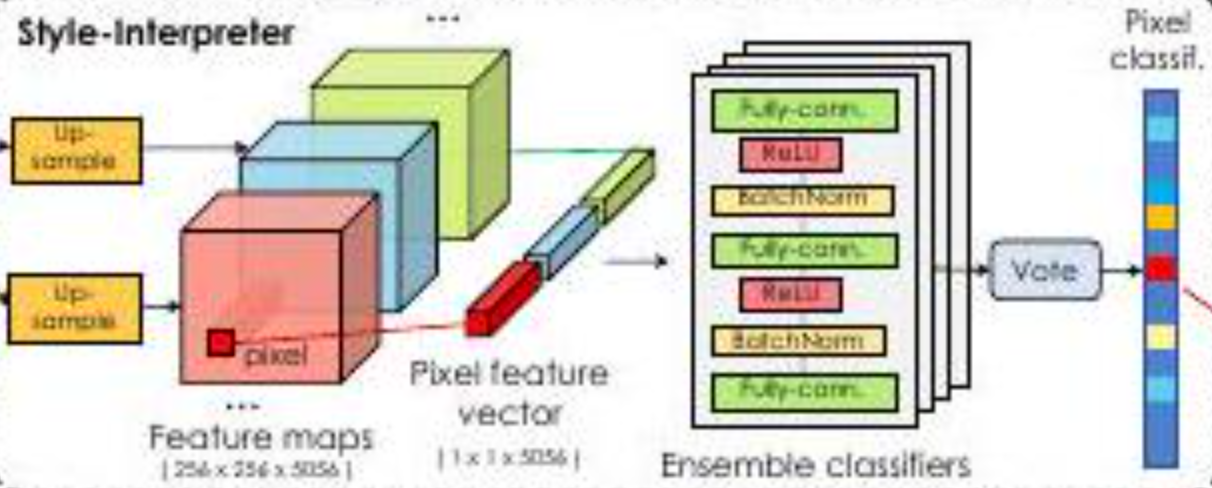
本論文には「潜在変数をグラフィック(graphics)、StyleGANをレンダリングエンジンとみなしている」と書かれています。つまり潜在変数は「どんな物体があるのか」を規定し、StyleGANは「どんな見え方になるか」を規定すると著者らは考えています。あるいは単に、潜在変数が被写体で、StyleGANはカメラと考えるとわかりやすいかもしれません。
そのため、得られた$S_{1}, S_{2}, S_{3}, \dots, S_{k}$には、物体の見え方を制御する次元がある(はず)と著者らは考えています。
そこで$S_{1}, S_{2}, S_{3}, \dots, S_{k}$を深さ方向に結合(concatenate)し、3次元のテンソルを得ます(図のFeature mapsの部分)。そして特定のピクセルに着目し、深さ方向のベクトルを得ます。これをピクセル特徴ベクトル(pixel feature vector)と呼び、$S_{i,*}$と表されます。つまり将来的に画像となる特徴マップから、各ピクセルに相当する部分(= ピクセル特徴ベクトル)をあらかじめ抜き出すということです。
その後、ピクセル特徴ベクトルは、3層からなるMLPに入力されます。そして実際に生成された画像と比較することで、どのピクセル特徴ベクトルがどの画素に対応するのかを学習します。そのようにして、どのピクセルがどのクラスに該当するかを学習し、画像全体としてセグメンテーション画像を生成します。
画像生成における損失関数
セグメンテーションの失敗は、特にノイズとして表れます(あるクラスのピクセルと別のクラスのピクセルが混ざってしまい、特定クラスからなる区画が作られない)。
このラベル付けの失敗を評価するため、Jensen-Shannon(JS)ダイバージェンス(以下、$D_{JS}$)が導入されています。
$$D_{JS}(P \| Q)=\alpha D_{K L}(P \| M)+\alpha D_{K L}(Q \| M), $$
$$M = \alpha(P+Q),$$
$$D_{KL}(P \| Q)=-\sum_{x \in X} P(x) \log \frac{Q(x)}{P(x)},$$
$$P_{(x)}=p(X=x),$$
$$Q_{(x)}=p(X=x \mid a)$$
$D_{KL}$は、Kullback-Leiblerダイバージェンス(KL情報量)と呼ばれるもので、確率分布の類似度を評価するものです。$D_{JS}$は、これを改良したものです。本論文では、JSダイバージェンスを使って合成された画像の不確実性を評価しています。
 上図は、DATASETGANが合成した画像の例です。合成画像とそのセグメンテーションの高い品質がわかります(とは言え、実は人物の額にシワがなかったり、ネコの体にセグメンテーションされていない部分があったりします。教師データはそのようにはなっていません)。
上図は、DATASETGANが合成した画像の例です。合成画像とそのセグメンテーションの高い品質がわかります(とは言え、実は人物の額にシワがなかったり、ネコの体にセグメンテーションされていない部分があったりします。教師データはそのようにはなっていません)。
人間のアノテーションとの比較
今回は、経験豊富なアノテーター1名(LabelMe使用)との比較を行いました。生成画像は、寝室、車、人間の頭部(顔)、鳥、猫などです。
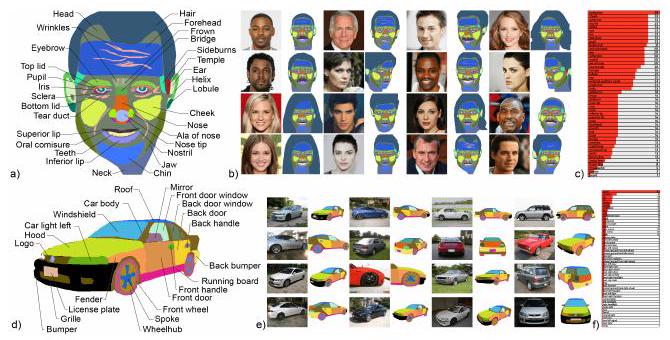
パートノミー(partonomy)とは、オブジェクトのパーツ同士の関係を示すツリー構造です。例えば人間の顔の場合、「頭部」の枝に「鼻」があり、その枝から「鼻先」や「鼻の穴」が生じます。上の図はパートノミーを可視化した例です。
パートノミーは、各クラスに対して手動で定義され、可能な限り詳細に設定されました。頭部の場合、平均で58個のパーツがアノテーションされました。これらを手動でアノテーションしようとすると、1枚あたり約20分かかります。しかしながら、本手法のDatasetGANでは1枚あたり約9秒で済みます。
手動で1万枚の画像にアノテーションを付与する場合、単純計算で約4ヶ月(134日)かかります。1日8時間アノテーションした場合、1年以上必要になります。これがDatasetGANでは25時間で済みます。
さらに驚くべきことに、実際には頭部16枚、車16枚、鳥30枚、猫30枚、寝室40枚の画像だけで、Style-Interpretorの訓練は終了しました。顔だけのアノテーションに限れば、約5時間のアノテーション作業で無限のデータセットを生成できるようになりました(逆に言えば、それだけもとにしたStyleGANの学習済みモデルが優秀ということですね)。

鳥、猫、寝室の生成画像です。人間の頭部と比較するとクラス数は少ないですが、アノテーション自体が難しく、かかった時間は頭部よりも長かったです。
生成画像の評価
使用したモデル
Deeplab-V3と呼ばれるモデルでセグメンテーションを行いました。Deeplab-V3は、ResNet151をバックボーンとするセグメンテーションのためのネットワークです。ResNet151はImageNetで学習済みであり、さらにDeeplab-V3全体をDatasetGANの生成画像で学習します。
比較対象のモデル
・転移学習の比較
比較のため、MS-COCOで学習済みのDeeplab-V3を用います。このモデルで、顔、猫、鳥等のデータで最終層の調整のみ行います(fine-tuning)。このときの訓練データのアノテーションは人間が行っています。
・半教師あり学習の比較
半教師あり学習では、文献[41](Semi-Supervised Semantic Segmentation with High- and Low-level Consistency)のモデルを比較対象としています。文献[41]もGANを利用したセグメンテーションタスクの研究報告であり、2つのGANを利用することでセグメンテーションのノイズを削減する方法を提案しています。
このモデルではImageNetでの事前学習した重みが利用されています。このモデルに対して、人間がアノテーションした教師データと、StyleGANが学習したものと同じアノテーションなしのデータを利用して学習させます(DatasetGANが合成した画像ではなく、DatasetGAN内のStyle-Interpretorが事前学習にしようした画像のことです)。
・完全教師あり学習
いくつかのデータセットで、Deeplab-V3を完全教師あり学習させます。
結果
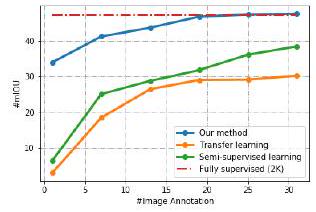
上のグラフは、ADE-Car12と呼ばれる車画像のデータセットを用いた結果です。横軸が訓練に使用した画像の枚数(千枚単位)で、縦軸が平均IOUです。
赤色の点線が完全教師あり学習で、青色が本論文の提案手法です。緑色が半教師あり学習、橙色が転移学習ですが、提案手法よりも比較対象の半教師あり学習や転移学習よりも成績が良いことがわかります。
さらに興味深いのは、2万枚以上で学習した場合には完全教師あり学習と同等の性能を発揮している点です。

この表はデータセットを変更した場合の結果です。いずれにしても提案手法がその他の手法よりも優れていることがわかります。
結論
本論文ではデータセット生成のためのDatasetGANを紹介しました。
DasetGANは、StyleGANの特徴マップを利用することで、わずかな手動アノテーションから効果的なセグメンテーションタスクを学習できることを示しました。これにより大規模なアノテーション付きデータセットを合成することができます。
DatasetGANで合成した画像で学習すると、合成画像を使用しない一般的な転移学習や半教師あり学習のモデルよりも優れた性能を発揮することが示されました。加えて、いくつかのテストデータセットでは、DatasetGANで学習データ数を増やした場合に、完全教師あり学習と同等の性能を発揮することが明らかになりました。






この記事に関するカテゴリー






