
【Brain2Music】脳の情報をもとに音楽を自動生成
3つの要点
✔️ 人間の脳活動をもとに音楽を自動生成
✔️ 音楽を聴いている人間の脳活動をfMRIで計測
✔️ MusicLMのアーキテクチャを利用
Brain2Music: Reconstructing Music from Human Brain Activity
written by Timo I. Denk, Yu Takagi, Takuya Matsuyama, Andrea Agostinelli, Tomoya Nakai, Christian Frank, Shinji Nishimoto
(Submitted on 20 Jul 2023)
Comments: Preprint; 21 pages; supplementary material: this https URL
Subjects: Neurons and Cognition (q-bio.NC); Machine Learning (cs.LG); Sound (cs.SD); Audio and Speech Processing (eess.AS)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
Googleや大阪大学などの共同研究である本研究では、「脳の活動をもとに音楽を生成するモデル」であるBrain2Musicが開発されました。生成された音楽は、以下のGitHubページで聴くことができます。
https://google-research.github.io/seanet/brain2music/
具体的には、fMRI(機能的磁気共鳴画像法)を用いて「音楽を聴いている被験者の脳活動」を計測し、その脳活動データを音楽生成に利用するという手法です。この研究は、脳がどのように音楽を解釈しているかだけでなく、将来的に想像したメロディを出力できるモデルの開発の足掛かりになりそうです。

ちなみに、本研究のBrain2Musicには、GoogleのText-to-Musicモデル「MusicLM」が利用されています。まずは、簡単にMusicLMについておさらいしましょう。
MusicLMの概要
MusicLMは、このようなテキストを入力として受け取り、そのテキストに沿った音楽を生成するText-to-Musicモデルです。例えば、以下の図のように「Hip hop song with violin solo」というプロンプトを入力すると、「ソロのバイオリンパートがあるヒップホップ」の音楽を生成してくれます。

https://arxiv.org/abs/2301.11325
MusicLMによる音楽生成の過程は、以下の手順の通りです。
- MuLanの音楽エンコーダによってMTを生成
- MTを条件として、デコーダのみのTransformerでSを生成
- MTとSを条件として、デコーダのみのTransformerでAを生成
- AをSoundStream(ニューラルボコーダー)のデコーダに通す
また、上記に含まれる記号の意味を、以下に記載します。
- MA: MuLanの音楽エンコーダによって得られたトークン
- MT: MuLanのテキストエンコーダによって得られたトークン
- S: w2v-BERTによって得られた「音楽の意味」を表すトークン
- A: SoundStreamによって得られた「音声」を表すトークン
ここで肝になってくるのが「MuLan」と呼ばれるモジュール。これは、テキストと音楽の対照学習モデルのことです。このMuLanを利用することで、対になる音楽-テキストペアデータにおいて、テキスト埋め込み表現と音楽埋め込み表現を近づけるように、学習することができます。MuLanのアーキテクチャは、以下の図の通り。
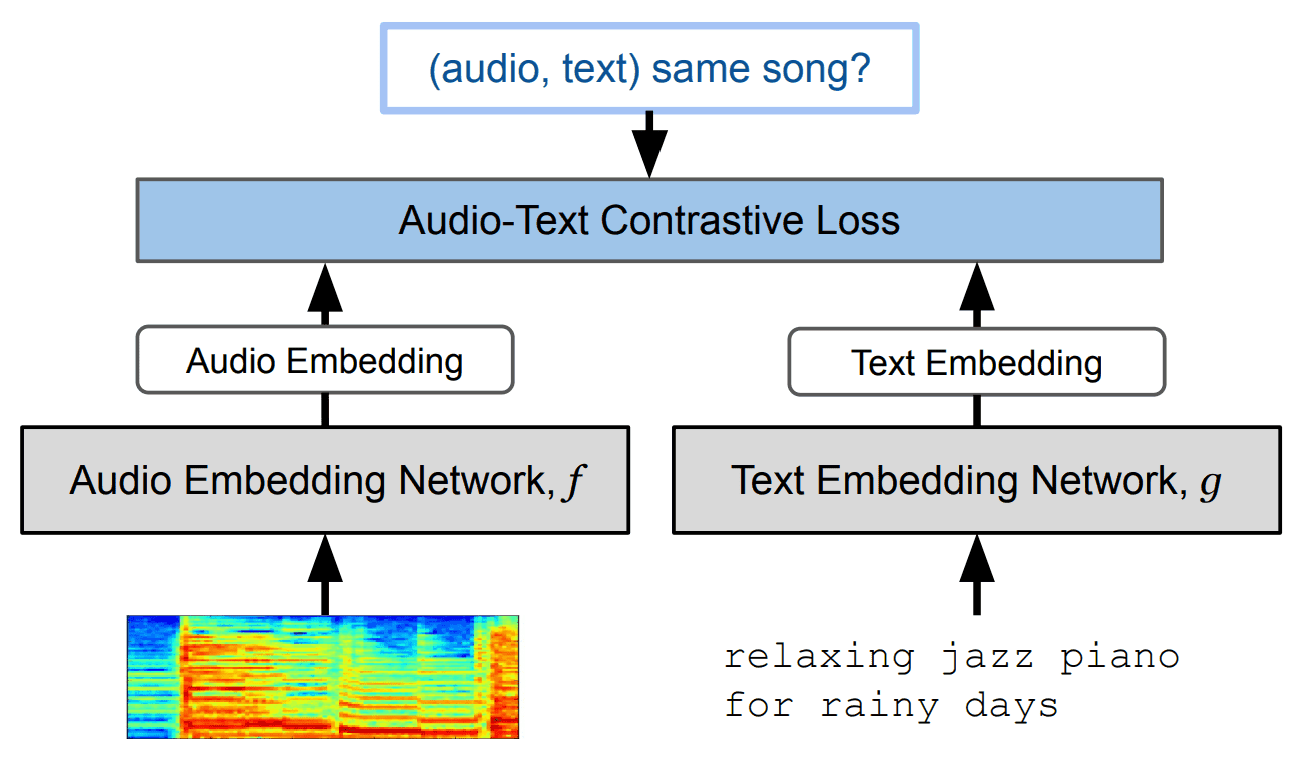
https://arxiv.org/abs/2208.12415
このモデルを利用することで、テキストを入力した際に、「そのテキストの内容に最も近い音楽の表現」を生成することができます。ここで、本研究では、MuLanのテキストエンコーダには「BERT」が利用され、オーディオエンコーダには「ResNet-50」が利用されています。
オーディオエンコーダに、画像用のモデルを利用する理由は、スペクトルグラム画像データを音楽データとして利用するため、画像処理が必要となるからです。
脳情報から音楽を作り出す手法
Brain2Musicのアーキテクチャは、ほとんどMusicLMと同じです。MusicLMと異なるのは、入力にfMRIにより取得した脳情報を利用しているという点。
まずは、fMRIについて見ておきましょう。
fMRI(機能的磁気共鳴画像法)とは
fMRIは、脳内の血流の変化を検出することによって、脳の活動を非侵襲的に観察する技術です。血中の酸素レベルに依存する信号(BOLD信号)を使用して、脳活動の空間的な分布を視覚化します。

fMRIは、人間の感情や認知機能に関連する、脳の領域の活動を研究するために広く使用されています。
音楽に対する反応を研究する上で、fMRIは特に重要な役割を果たしてきました。音楽は脳内で多様な処理を引き起こし、情緒的反応や記憶、注意力など多岐にわたる分野での研究に利用されています。これにより、脳活動と音楽知覚の関連を探究し、音楽に対する脳の反応をより深く理解することが可能になっているのです。
データセット
本研究で使用されたデータセットは、Nakai et al. (2022)の研究から前処理された「音楽ジャンルの神経画像データセット」です。このデータセットには、10の異なるジャンル(ブルース、クラシック、カントリー、ディスコ、ヒップホップ、ジャズ、メタル、ポップ、レゲエ、ロック)からランダムにサンプリングされた音楽を流した時の、脳活動のデータが含まれています。
最終的に、 トレーニング用に480例、テスト用に60例が含まれています。
Brain2Musicのアーキテクチャ
Brain2Musicのアーキテクチャは、以下の図の通りです。
fMRI技術を用いて被験者が音楽を聞いている間の脳活動を捉え、そのデータを基に音楽の埋め込みを予測し、さらに音楽を再構築するという新しいアプローチを採用しています。
音楽生成の流れは、以下の通りです。
- fMRI反応Rを入力として受け取る
- Rを説明変数としてMuLanのMusic embeddingを予測
- Music embeddingをもとに、音楽検索or音楽生成
まず、fMRI反応Rを入力として受け取り、MuLanのmusic embeddingを予測します。この時、music embeddingをTとすると、T=RW (Wは学習パラメータ)のL2正則化付き回帰により、Tを予測します。
上記のTを用いて、音楽検索or音楽生成をすることで、脳情報から音楽を作り出しています。
・音楽検索
音楽検索では、あらかじめ音楽データベース内の106,574曲分の(冒頭15秒間の)music embeddingを計算しておきます。そして、先ほど予測したTと、音楽データベース内のmusic embeddingの類似度を予測し、最も類似度の大きい曲をデータベースから抽出します。
・音楽生成
音楽生成では、Tを用いて、以下のMusicLMベースのアーキテクチャによって音楽を生成します。

こちらは、従来のMusicLMとほとんど同じです。違いとしては、MuLan埋め込みT(図中の「High-level(MuLan)」)を、fMRI反応を利用して求めている点にあります。
評価実験
Music embedding予測の精度比較
手法のセクションで見た通り、fMRIデータから音楽を生成するには、中間段階として音楽埋め込みを予測する必要があります。その際に、以下の4つのうち、どのembeddingを用いると性能が良くなるのか比較実験が行われました。
- SoundStream-avg
- w2v-BERT-avg
- MuLantext
- MuLanmusic
この実験では、fMRIから上記の各埋め込みをT=RWの回帰式において予測し、それぞれの性能を比較しています。結果は以下の通りです。

この結果より、MuLanmusicの場合に、最も性能が高いことが分かります。そのため、Brain2Musicでは、fMRIを「MuLanmusicの予測」のために使用することになります。
音楽検索 vs 音楽生成
以下の図は、被験者に聴かせるための本物の音楽と、検索or生成された音楽の、スペクトルグラム画像です。要するに、本物の音楽と、検索or生成された音楽のスペクトルグラムが、似ていれば良いという解釈ができます。

以下の図は、fMRIデータを使って音楽をどれだけ正確に再現できたかを、定量的に比較している図です。ランダムな予測(Chance)と理想的な予測(Oracle)の間で、実際の予測の成果を評価しています。

a~cが表しているのは、それぞれ以下の通りです。
- a: 異なるmusic embeddingにおける精度
- b: オリジナルの音楽と再構築された音楽の類似度
- c: 各ジャンルにおける精度
上記の図より言えることは、以下の通りです。
- エンコーダにMuLanを用いた方が精度が良い
- MusicLMによる音楽生成の方が精度が良い
- Brain2Musicでは、どのジャンルも同程度の精度で生成できる
音楽埋め込みからのfMRI信号予測タスク
これは、MusicLM内で発生する異なる音楽埋め込みを使用して、fMRI信号を予測し、その精度を比較するタスクです。ここでは、L2正則化付の回帰モデルが使用されます。
・MuLanmusic vs w2v-BERT-avg
最初に、音楽由来の埋め込み(MuLanmusicとw2v-BERT-avg)からボクセル活動(脳活動)を予測するエンコーディングモデルを構築し、人間の脳内でこれらがどのように異なって表現されるかを比較します。
MuLanmusicとw2v-BERT-avgは、どちらも音声を入力とし、音楽の意味を表す埋め込みを出力するモデルです。
上記の結果より、両モデルとも、同じ脳の領域の活動を予測したことが分かりました。活動が示されている領域は、聴覚皮質にあたります。
そのため、両方の埋め込みが聴覚皮質で、ある程度の相関があることが示されています。
・MuLanmusic vs MuLantext
次に、音楽由来のMuLanmusicとテキスト由来のMuLantext埋め込みを使用して、fMRI信号を予測するエンコーディングモデルを構築します。この時、MuLanのテキスト埋め込みを得るために、データセット内の各楽曲に対応するテキストキャプションを、MuLanのテキストエンコーダに入力します。

上記の結果より、ここでも両モデルにおいて、聴覚皮質での反応が予測されています。
他ジャンルへの汎化
ここでは、モデルが「トレーニング中に使用されなかった音楽ジャンル」に対し、どの程度一般化できるか検証しています。以下の図では、全データを使用して学習したモデルの精度(full」)と、学習データに含まれていないジャンルで学習したモデルの精度を表しています。

この比較により、モデルが学習中に使用されていない音楽ジャンルに対しても、一定の汎化性能を持つことが示されています。
まとめ
本研究における課題として、以下の3点が指摘されています。
- fMRIデータから線形回帰を用いて抽出できる情報量の限界
- 音楽埋め込み(MuLan)が捉えることができる内容の限界
- 音楽検索または生成能力の限界
本研究では、音楽の音響的特徴が、人間の脳のどこで、どの程度表現されるかを評価しました。
将来的には、純粋な想像力から音楽を生成することが可能になるかもしれないですね。そのような技術が、もしも実現されれば、例えば以下のようなことが可能になるでしょう。
- 想像上のメロディを具現化する新時代の音楽プラットフォーム
- 個人の音楽感性を捉え、音楽のより感覚的な理解をサポートするサービス
生物学的観点を交えた音楽生成の分野に、今後も目が離せません。






この記事に関するカテゴリー





