アーキテクチャの評価に学習は不要!? ゼロショットNAS【Zen-NAS】とは?
3つの要点
✔️ NASのためのZero-Shot指標であるZen-Scoreならびにそれを用いたZen-NASを提案
✔️ 0.5GPU日でImageNet-top-1精度83.6%を達成
✔️ 既存手法と比べて非常に高水準な探索手法を実現
Zen-NAS: A Zero-Shot NAS for High-Performance Deep Image Recognition
written by Ming Lin, Pichao Wang, Zhenhong Sun, Hesen Chen, Xiuyu Sun, Qi Qian, Hao Li, Rong Jin
(Submitted on 1 Feb 2021 (v1), last revised 23 Aug 2021 (this version, v4))
Comments: Accepted by ICCV 2021
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
最適なニューラルネットワークアーキテクチャを探索する手法であるNAS(Neural Architecture Search)において、計算コストの削減は非常に大きな課題です。例えばAmoebaNetでは、アーキテクチャの探索に約3150GPU日を要するなど、NASの登場当初は尋常ではない計算コストが必要でした。
この課題に対処するため、巨大なスーパーネットを学習させてからその内部のサブネットの性能を評価するOne-Shot NAS(例1,2)や、モデルの学習途中で最終的な性能を予測する手法など、計算量を削減するための様々な手法が提案されています。
本記事で紹介する論文では、アーキテクチャの性能を評価するためのZero-Shot指標であるZen-Scoreを提案しました。このZen-Scoreをアーキテクチャ精度評価のためのプロキシとして用いるZen-NASは、既存のNAS手法と比べて高速かつ高精度なアーキテクチャ探索に成功しました。
Zen-Score
アーキテクチャの性能評価のためのZero-Shot指標となるZen-Scoreは、大きく二つの提案を含んでいます。
- Vanilla Convolutional Neural Network (VCNN)の表現力を求める指標である$\Phi -Score$
- $\Phi -Score$を実際のアーキテクチャ精度評価のために修正した$Zen-Score$
Vanilla Convolutional Neural Network (VCNN)は、各層が1つの畳み込み演算とRELU活性化関数で構成されるシンプルなアーキテクチャです。以下、$\Phi -Score$・$Zen-Score$について順番に説明します。
$\Phi -Score$について
元論文で提示された$\Phi -Score$は、Vanilla Convolutional Neural Network (VCNN)の表現力を測定するための指標となります。
・ニューラルネットワークの表現力について
$\Phi -Score$は、ニューラルネットワークの表現力に関する既存の理論研究をベースとしています。
特に重要な知見は、(RELUなどの区分線形関数を活性化関数とする)バニラネットワークが、活性化パターンを条件とする線形関数に分解可能であることです。ここで、$t$層目の活性化パターンを$A_t(x)$とすると、任意のバニラネットワーク$f(\cdot)$は以下の式で表されます。
$f(x|\theta)=\sum_{S_i \in S}I_x(S_i) W_{S_i}x$
このとき、$S_i$は活性化パターン$\{A_1(x),A_2(x),A_L(x)\}$に対応する線形領域(凸ポリトープ)、$I_x(S_i)$は$x \in S_i$のとき1・そうでないとき0となる関数、$W_{S_i}$は係数行列にあたります。(また、詳細については省きますが、Residual接続、Batch Normalization、Self-Attention blockなど、最近のネットワークで用いられる補助的な構造は、ネットワークの表現力に大きな影響を与えません。そのため表現力の測定の際には、こうした補助的な構造は一時的に削除され、訓練・テスト段階に再度追加されます。)
・線形領域の数$|S|$について
既存の理論研究において、バニラネットワークの線形領域の数$|S|$はネットワークの表現力を示す指標として利用されています。
例えばMontúfar et al.では、深い層のNNが浅い層のNNよりも多くの線形領域を持つことを示し、深層ニューラルネットワークの理論的優位性を示しました。多くの線形領域を持つことがネットワークの表現力の指標として利用できることは、例えば同論文内の以下の図からわかります。
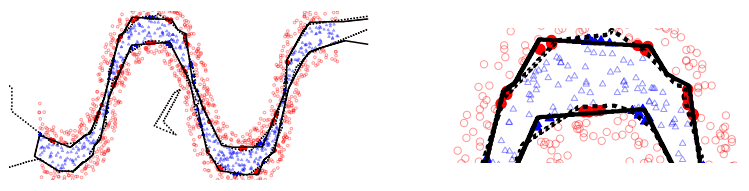
この図は、合計ユニット数が同じである1層(実線)/2層(点線)の学習済みモデルの決定境界を示しています。図の事例では、2層のモデル(点線)がより多くの線形部分を持ち、適切な境界をより正確に近似していることがわかります。
・係数行列$W_{S_i}$と関連するGaussian complexityについて
前述した式の通り、バニラネットワークは線形領域$S_i$に対応する線形関数$f(X)=W_{S_i}X$に分解されます。
このとき、実数値関数の集合$F$の複雑さの指標とみなされるGaussian complexity($G(F)=E[sup_{f \in F}\frac{1}{n}\sum^n_{i=1}f(x_i)\epsilon_i]$、$\epsilon_i~N(0,1)$)に関して、以下の関係が成り立ちます。線形関数クラス$f:f(X)=WX s.t. ||W||_F \leq G$について、$O(G)$がGaussian complexityの上界である。よって、線形領域の数$|S|$だけでなく、係数行列$W$(のフロベニウスノルム$||W||$)に関連するGaussian complexityも、バニラネットワークの表現力を示す指標として用いることができると考えられます。
・$\Phi -Score$
前述の通り、線形領域の数$|S|$または係数行列$W_{S_i}$に関連するGaussian complexityを表現力の指標として用いることが考えられます。
しかし実際には、線形領域の数$|S|$を大規模なネットワーク上で測定することは計算的に不可能であり、指標として用いることは困難です。これらの知見に基づき、$\Phi -Score$はバニラネットワーク$f(\cdot)$のGaussian complexityの期待値として定義されます。
$\Phi(f)log E_{x,\theta} \{\sum_{S_i \in S}I_x(S_i)||W_{S_i}||_F\}$
$=log E_{x,\theta} ||\nabla_x f(x|\theta)||_F$
結果として$\Phi -Score$は、入力$x$に対する$f$の勾配ノルムの期待値を計算することと同じになります。
Zen-Scoreについて
・$\Phi -Score$の計算上の課題
上述の通り、バニラネットワークの表現力の基準として定義された$\Phi -Score$ですが、実際にNASに適用するには課題があります。
具体的には、非常に深いネットワークの$\Phi-Score$を計算すると、BatchNormalization層なしでは勾配爆発によるオーバーフローが生じてしまいます。
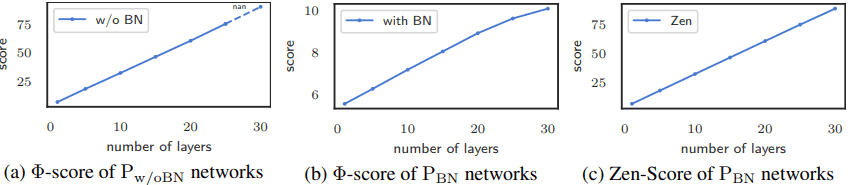
図(a)の通り、層の数が30に到達した段階でオーバーフローが生じてしまいます。一方で、BatchNormalization層ありで$\Phi-Score$を計算した場合、図(b)のように$\Phi-Score$が非常に小さくなります(縦軸の値に注意)。
この現象(BN-rescaling)に対処するため、$\Phi-Score$を修正したものがZen-Scoreとなります。
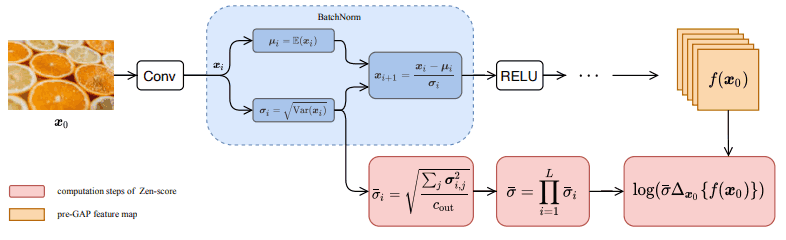
・Zen-Score
Zen-Scoreの計算方法とパイプラインは以下の通りです。

・Zen-NASについて
元論文で最終的に導かれるZero-Shot NASアルゴリズムであるZen-NASは、Zen-Scoreを最大化するアーキテクチャの探索を行う手法となります。Zen-NASは進化的アルゴリズム(Evolutionary Algorithm)を用いており、アルゴリズムは以下のようになります。

MUTATEは進化的アルゴリズムにおける突然変異を表し、具体的には以下のようになります。

突然変異における幅と層の深さは、[0.5, 2.0]の範囲で変異されます。
$T回$の反復の後、Zen-Scoreが最大となったアーキテクチャはZenNetsと名付けられ、Zen-NASの出力となります。
実験結果
実験設定
実験はCIFAR-10/CIFAR-100およびImageNet-1kにて行われました。
既存のZero-Shotプロキシとの比較
はじめに、既存のZero-Shotプロキシと同じ検索空間・検索方策・学習設定にて比較実験を行った場合の結果は以下の通りです。
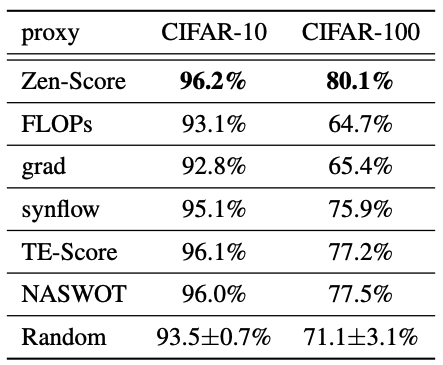
既存手法と比べて優れた結果が得られたことがわかります。また、解像度224x224におけるResNetでの計算時間は以下の通りです。
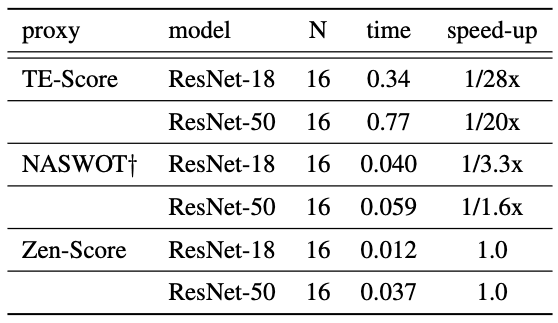
表の$N$と$time$は、$N$枚の画像を処理するのに$time$秒かかることを意味しています。既存のZero-Shotプロキシと比べ、計算効率も優れていることが示されました。
ZenNetsと既存モデルの性能比較
ImageNetデータセットにて、Zen-NASを用いて、NVIDIA V100 GPU上で、FP16、バッチサイズ64、0.5GPU日の探索を行い得られたZenNetsと既存モデルとの性能比較結果は以下の通りです。
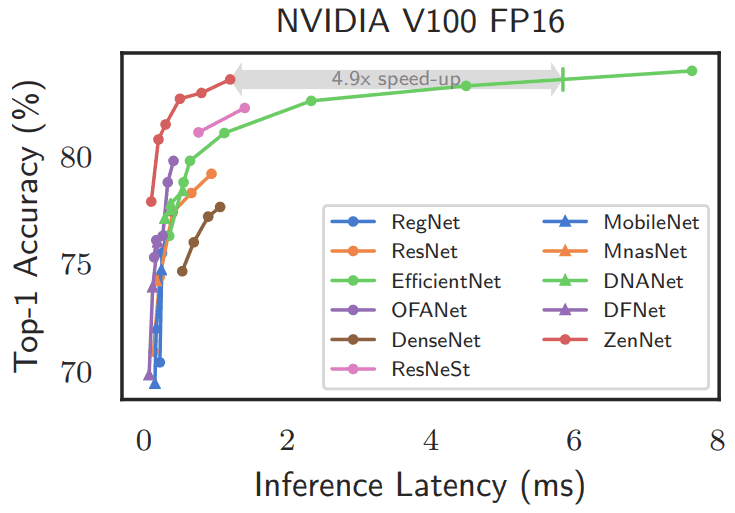
図の通り、ZenNetsはtop-1精度・推論時間ともに、既存手法と比べて大幅に優れた結果を示しました。
また、計算量を400/600/900M FLOPS以内に制限した軽量ネットワークについて探索を行った場合の結果は以下のとおりです。
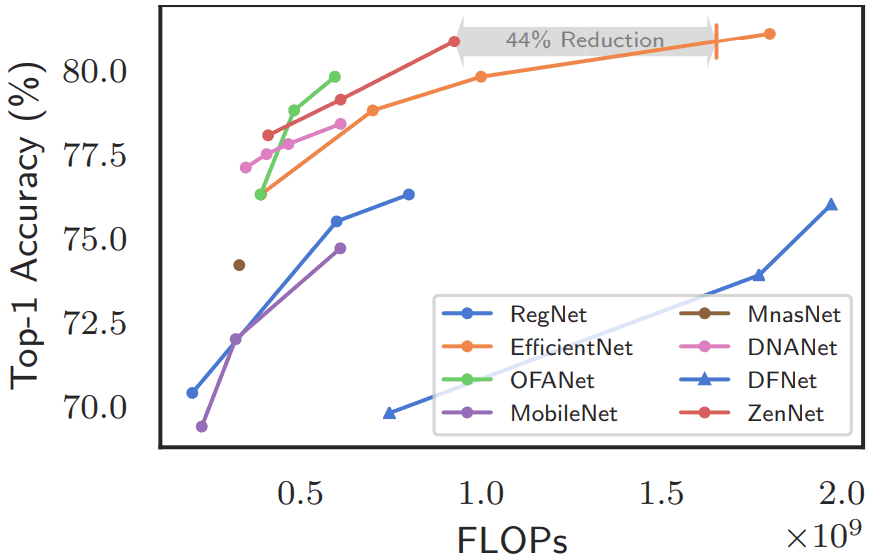
この場合についても、ZenNetsは優れた結果を示しています。
Zen-NASと既存NAS手法の比較
Zen-NASと既存NAS手法との比較結果は以下の通りです。
ただし、同条件で比較を行うことは困難なため、各手法による最良のモデルと計算コストが掲載されています。
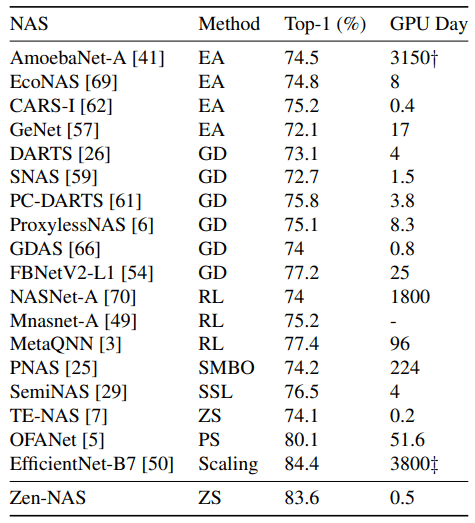
表のMethodについて、EAはEvolutionary Algorithm、GDはGradient Descent、RLはReinforcement Learning、ZSはZero-Shot、その他は固有の特殊な探索手法を示します。総じてZen-NASは、Top-1精度・探索時間どちらについても非常に高水準であることが示されました。
まとめ
本記事では、ネットワークの表現力の基準であるZen-Scoreの提案ならびにそれを最大化するZen-NASを提案した論文について紹介しました。
Zen-NASは、既存のNAS手法と比べて高速かつ高精度なアーキテクチャ探索に成功しました。記事内で紹介した通り、Zen-NASで用いられるZero-Shot指標であるZen-Scoreは、ニューラルネットワークに関する理論研究(Montufar et al.、Xiong et al.など。その他詳細は元論文参照)をもとに提案されています。
ニューラルネットワークに関する理論研究が効率的なネットワーク設計の理解に役立つことを示した事例でもあり、今後の理論研究の活発化につながることが期待される非常に興味深い研究であると言えるでしょう。



この記事に関するカテゴリー






