【AutoFormer】画像認識のための最適なTransformerを求めて
3つの要点
✔️ 視覚タスクにおけるTransformerにOne-Shot NASを適用
✔️ サブネットの重みの大部分を共有させるWeight Entanglementを提案
✔️ 既存のTransformerベース手法と比べて優れた性能を発揮
AutoFormer: Searching Transformers for Visual Recognition
written by Minghao Chen, Houwen Peng, Jianlong Fu, Haibin Ling
(Submitted on 1 Jul 2021)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
Transformerは自然言語処理を始めとして、画像分類などの様々な視覚タスクにおいても高い性能を発揮しています。では、視覚タスクにおけるTransformerの最適なアーキテクチャはどのようなものでしょうか?
Transformerでは、埋め込み次元、層の深さ、ヘッド数などを変更することで、様々なアーキテクチャを設計することができますが、これらをどう設定すべきであるかは決して自明ではありません。そのため、Transformerの適切なアーキテクチャの設計は困難な問題となります。
本記事ではこの問題に取り組んだ研究である、視覚タスクにおけるTransformerの最適なアーキテクチャを探索することに特化したNASアルゴリズムであるAutoFormerについて紹介します。
提案手法(AutoFormer)
AutoFormerは、One-Shot NASと呼ばれる手法を視覚タスクにおけるTransformerのアーキテクチャ探索に適用する手法です。ただし、Transformerに既存のOne-Shot NASをそのまま適用することは難しいため、Weight Entanglementと呼ばれる工夫を更に施しています。
One-Shot NASについて
NAS(Neural Architecture Search)において、最適なアーキテクチャを見つけるための最も単純な方法は、様々なアーキテクチャをゼロから学習してその性能を比較することです。当然ながら、この方法ではデータセットやアーキテクチャが大規模になればなるほど、必要な計算コストが著しく増大してしまいます。
One-Shot NASは、この計算コストを削減するために考案された手法の一つとなります。
One-Shot NASは、大きく二段階に分かれています。
まず第一段階では、スーパーネット$N(A,W)$で表されるネットワークを一度学習させます($A$はアーキテクチャ探索空間、Wはスーパーネットの重み)。
第二段階では、スーパーネットの重み$W$の一部を、探索空間内のアーキテクチャ候補であるサブネット$\alpha \in A$の重みとして利用し、各アーキテクチャの性能を比較します。これらは以下の式で表されます。
- 第一段階:$W_A=\underset{W}{arg min} L_{train}(N(A,W))$
- 第二段階:$\alpha^{\ast}=\underset{\alpha \in A}{arg max} Acc_{val}(N(\alpha,w))$
第一段階の学習時には、スーパーネット内のサブネットをランダムにサンプリングし、そのサブネットに対応する箇所の重みを更新します。第二段階のアーキテクチャ探索時には、ランダム、進化的アルゴリズム、強化学習などの様々な探索手法を用いて探索を行います。
Weight Entanglementについて
既存のOne-Shot NASでは、ネットワーク内の各層で、独立した異なるブロックをサブネットの重みとして利用します。この方針をそのままTransformerに適用した場合、スーパーネットの収束が遅い・サブネットの性能が低いなどの問題が生じます。そのためAutoFormerでは、各層ごとに重みの大部分を共有することで、これらの問題に対処しています。これらの違いは以下の図で示されます。
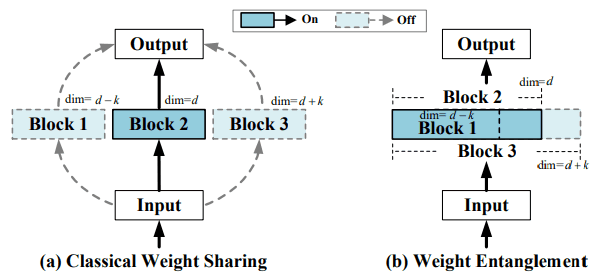
つまりAutoFormerでは、探索対象として選択され得る最大のブロックの部分集合が、サブネット内のブロックとして選択されます。
(スーパーネットは、サブネットの中で最も大きいアーキテクチャと同一になります。)
ここで、既存の方針とWeight Entanglementとの比較結果は以下の通りです。
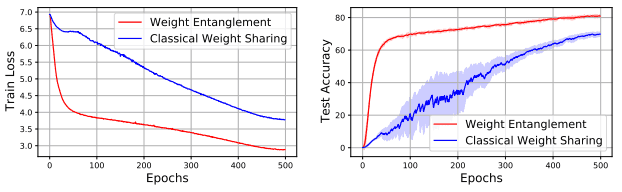
左図はスーパーネットのtrain損失を、右図はサブネットのImageNet Top-1 Accuracyを示しています。
この工夫により、(1)収束が早くなる、(2)メモリコストを削減できる、(3)サブネットの性能が向上する、などの利点が生まれます。
探索空間について
AutoFormerでは、大きく3つ(tiny/small/base)の探索空間についてアーキテクチャ探索を行います。これは以下の表の通りです。
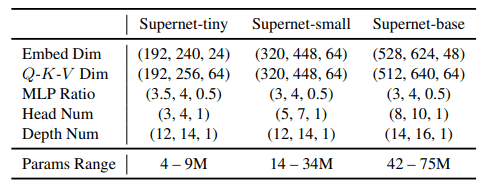
この表に示される(a,b,c)は、それぞれ(下限,上限,ステップ)を示しています。例えば(192,240,24)は、[192,216,240]の三つのパラメータ設定について探索を行うことを示します。
AutoFormerのパイプラインについて
先述したOne-Shot NASについてと同様に、AutoFormerのパイプラインは二段階に分かれています。
第一段階:スーパーネットの学習
スーパーネットの学習時には、各イテレーションごとに、定義された探索空間からサブネットをランダムにサンプリングし、スーパーネットの対応する重みを更新します(それ以外の部分は凍結されます)。
第二段階:アーキテクチャの進化探索
最適なアーキテクチャを見つけるため、進化的アルゴリズムを用いて最もvalidation精度の高いサブネットを探索します。具体的には、以下の手順に従います。
- はじめに、$N$個のランダムなアーキテクチャを種として選択します。
- 上位$k$個のアーキテクチャを親として選択し、交叉(Cross Over)・突然変異(Mutation)により次世代を生成します。
- 交叉:ランダムに選択された二つの候補をもとに新たな候補を生成します。
- 突然変異:確率$P_d$で層の深さを変異させ、確率$P_m$で各ブロックを変異させ、新たな候補を生成します。
AutoFormerはこれらのパイプラインに従い、最適なアーキテクチャの探索を行います。
実験結果
実験では、以下の設定に基づいてAutoFormerの性能を検証します。
スーパーネットの学習
スーパーネットの学習は、視覚タスクにおけるTransformerベースの手法であるDeiTと同じ方法で行います。ハイパーパラメータ等の学習設定は以下の通りです。
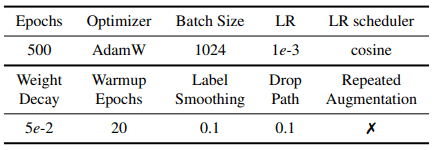
データ増強には、RandAugment、Cutmix、Mixup、Random Erasingなどの手法を、DeiTと同じ設定で利用します。画像は16x16のパッチに分割します。
進化探索について
進化探索はSOPSと同一のプロトコルに従っています。testセットにはImageNetのvalidationセットを、10,000のtrain例をvalidationセットとして利用します。集団サイズは50、世代数は20、各世代ごとに親となるアーキテクチャは10個、変異確率は$P_d=0.2$、$P_m=0.4$に設定されています。
Weight Entanglementと進化探索について
はじめに、AutoFormerにおけるWeight Entanglementと進化探索(Evolution Search)の有効性についての検証結果は以下の通りです。

この表のうちRetrainは、探索の結果として得られた最適なアーキテクチャを300エポックの間、ゼロから再学習した場合の性能を示しています(Inheritedは再学習なし)。
驚くべきことに、Weight Entanglementを利用した場合、再学習を行わなった場合と行わなかった場合とで、ほとんど性能の変化が起こらないことがわかります。この点について、より詳しい実験を行った結果は以下のようになります。
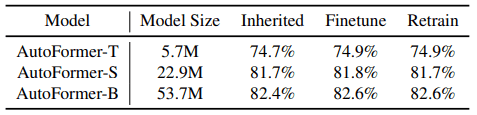
表の通り、スーパーネットから重みを引き継いだ状態(Inherited)、30エポックの微調整を行った場合(Finetune)、ゼロから300エポックの再学習を行った場合(Retrain)で、性能の変化はごくわずかしか起きていません。
また以下の図では、再学習を行わないままでも優れた性能を発揮するサブネットが多数存在することが示されています。
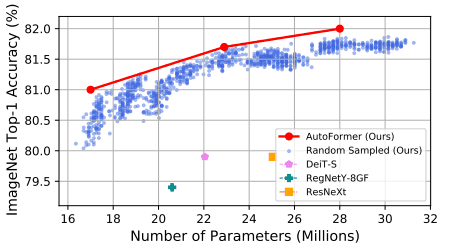
これらの結果は、スーパーネットから重みを引き継いだサブネットの性能を、アーキテクチャの優劣の比較の指標として用いることの有効性を示していると言えます。また、ランダム探索と進化探索との比較結果は以下のとおりです。
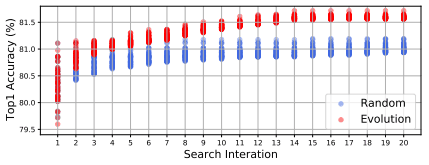
この図では、各世代ごとの上位50までの性能がプロットされており、進化探索がランダム探索と比べ優位であることがわかります。
既存手法との比較結果について
CNNベース/Transformerベースの様々な既存手法について、ImageNet上でのAutoFormerとの比較結果は以下の通りです。
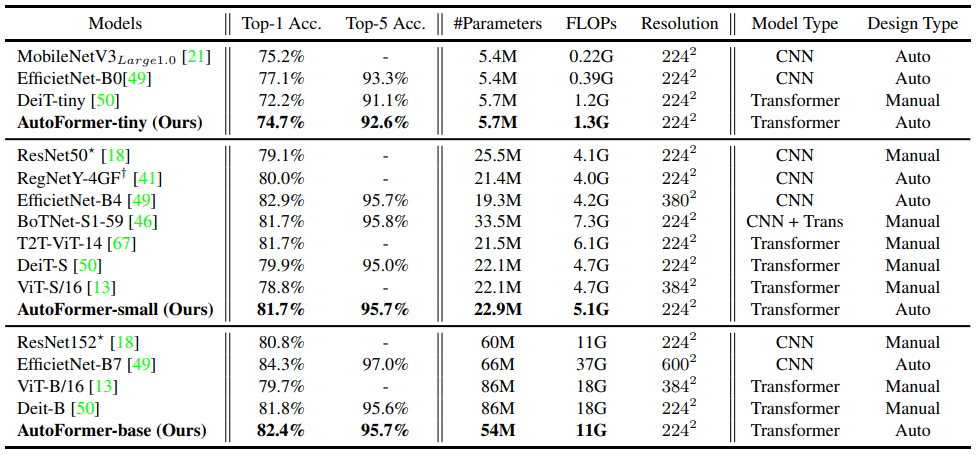
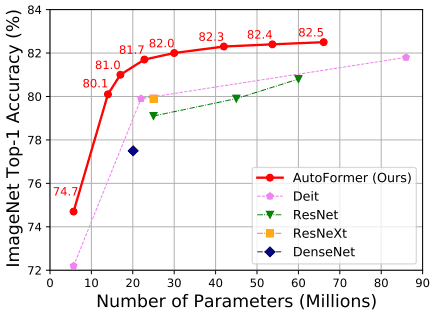
AutoFormerの結果は、再学習やfine-tuningを行わず、スーパーネットから重みを引き継いだままの結果が示されています。
表の通り、Transformerベースの手法であるViTやDeiTと比べて優れた精度を示すことがわかりました。ただし、CNNベースの手法であるMobileNetV3やEfficientNetには未だ劣っており、視覚タスクにおける既存手法全てに対し優れた結果を示したわけではない点には注意が必要です。
・転移学習について
ImageNetで学習したAutoFormerを別のデータセット上で転移学習を行った場合の結果は以下のようになります。

総じて、既存手法と比べて少ないパラメータ数でも同等の精度を発揮していることがわかります。
まとめ
本記事では、視覚タスクにおけるTransformerのOne-shotアーキテクチャ探索手法であるAutoFormerについて解説しました。
AutoFormerでは、既存のOne-shot NASと異なる方針であるWeight Entanglementを利用することで、スーパーネットの学習速度の向上・サブネットの性能向上などの優れた特性を獲得しました。また、探索空間内に畳み込み演算を含めたり、畳み込みネットワークの探索にWeight Entanglementを利用するなど、今後の発展性にも期待が持てる研究であると言えるでしょう。






この記事に関するカテゴリー






