ロボットが未知の複雑な挿入タスクを過去に集めたデータを用いて素早く適応するoffline Meta-RL Framework!
3つの要点
✔️ 複雑なinsertion taskを解くことが出来るOffline meta-RL frameworkの提案
✔️ Demonstrationとoffline dataを利用することにより、未知のタスクにおいて素早い適応が可能
✔️ 学習時のタスクとテスト時のタスクが大きく異なってもfinetuningにより、12タスク全てにおいて30分以内で100%の成功率を達成
Offline Meta-Reinforcement Learning for Industrial Insertion
written by Tony Z. Zhao, Jianlan Luo, Oleg Sushkov, Rugile Pevceviciute, Nicolas Heess, Jon Scholz, Stefan Schaal, Sergey Levine
(Submitted on 21 Mar 2021 (v1), last revised 31 Jul 2021 (this version, v4))
Comments: RSS 2021
Subjects: Artificial Intelligence (cs.AI); Robotics (cs.RO)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
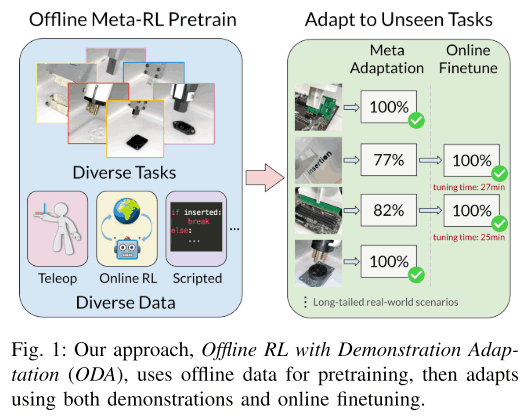
近年、実機のロボットによる部品の挿入タスクにおいて、強化学習によるpolicyの学習によって高い成功率を様々な研究で示しています。特に、こちらの記事で紹介した手法では、少量のデモンストレーションと強化学習、そしていくつかの工夫により非常に複雑な挿入タスクを高い成功率で解くことが出来ることを示しました。しかし、現状異なる部品の挿入タスクを解きたい場合、一から学習し直さなければならないという問題があります。そこで、本記事では、そのような問題点を解決したOffline Meta-Reinforcement Learning for Industrial Insertionという論文を紹介します。
近年、未知のデータに対して瞬時に適応することが出来るような強化学習の手法としてmeta-RLが注目されています。しかしmeta-RLにはとても時間がかかるonline meta-RL trainingが必要であり、これを実世界で行うには難しいという問題があります。よって、本論文では下図のようにあらかじめ集めた多様なoffline datasetを用いてoffline meta-RLを行い、そのうえでonline finetuningを行うことで瞬時に未知の部品に対しても適応できる手法を提案しました。では、この論文の詳細を説明していきます。
手法
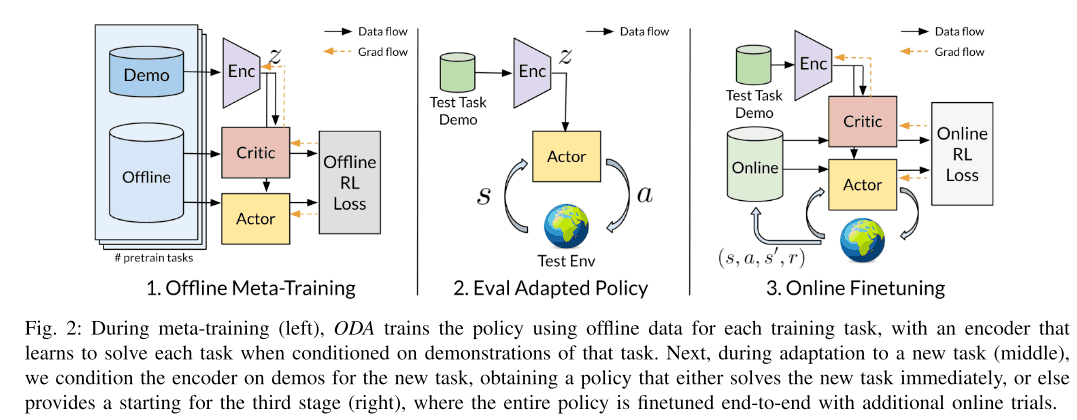
本章では提案手法を詳しく説明してきます。手法の全体像としては以下の図のようになっており、まずはじめに、adaptive policyをoffline RLを用いたmeta-trainingにより学習します。この際、データセットは予め集めた様々な部品を使ったタスクのdemonstrationとoffline data(過去に学習した際のreplay bufferに格納されたデータなど)によって成り立っています。そして、このadaptive policyが未知のタスクに対して利用されるのですが、その際に少量のdemonstrationと更にonline RL finetuningによって最終的なpolicyを得ることが出来ます。このような方法により、過去に学習したpolicyをそのままonline RLによって未知のタスクに適応させるなどをするより安全で簡単に未知のタスクに対してpolicyを適応させることが出来ます。
本手法で用いられるpolicyはpolicy network $\pi(a|s, z)$とエンコーダー$q_{\phi}(z|c)$で成り立っており、$s$は現在のstate、$z$はタスクを表す潜在コードを表しています。よって、エンコーダーはタスクのdemonstrationからどのようにタスクを実行するかに必要な重要な情報を抽出し潜在コードに落とし込みます。これはPEARLやMELDという手法と似ていますが、潜在コードを得る部分において、それらの手法はonline experienceを用いて潜在コードを得ているのに対して、本手法ではdemonstrationから得ます。
そして、未知のタスクに対して適応する際は、少量のdemonstrationがそのタスクのcontextとして与えられ、それを元に潜在コード$z\sim q(z|c)$を推論しpolicyを未知のタスクに対して利用することが出来ます。しかし、未知のタスクがmeta-trainingで利用されたタスクとは大きく異なる場合、policyが未知のタスクを解くことが出来るような$z$を推定することが困難となります。そのような場合は、online RLを用いてpolicyのfinetuningを行います。本論文で行われた実験ではこのfinetuningは約5~10分で終わることを示しています。
では、それぞれのステップに関してもう少し詳しい説明をしていきます。
Contextual Meta-LearningとDemonstrations
上で説明したように、本論文の提案手法では、PEARLやMELDなどの過去の手法とは異なり、タスクのcontextとしてdemonstrationを用いてエンコーダー$q_{\phi}(z|c)$を学習します。そして出力される潜在コード$z$はpolicy $\pi_{\theta}(a|s, z)$に渡されます。このdemonstrationを受け取る場合の利点として、train-test distribution shiftと呼ばれる、学習時とテスト時の分布の違いからパフォーマンスが低下することを抑えられるという点です。これは、テスト時の未知のタスクに関する集められたデータと学習時に利用されるoffline dataが異なるpolicyから集められることになるので、それによりdistribution shiftが起きやすくなりますが、demonstrationを利用することでその問題点が解消されます。
学習時は、エンコーダー $q_{\phi}(z|c)$とpolicy $\pi_{\theta}(a|s, z)$が同時にmeta-trainingタスクのパフォーマンスを最大化するように学習されます。また学習時には2つの種類のデータが用いられ、一つはdemonstrationで、もう一つはactor-criticを更新するために利用されるoffline dataで成り立っています。このoffline dataは過去に学習したタスクにおいて、replay bufferに格納されたデータなどに該当します。また、エンコーダーは、潜在コード$z$に不要な情報をなるべく含まないように、KL divergence lossを追加します。これらの詳細なアルゴリズムは下のアルゴリズムの図が示しています。

Offline & Online Reinforcement Learning
本手法では、offline dataを用いてmeta-trainingを行う必要があるため、それに適したoffline RLのアルゴリズムが必要になります。またその後fine-tuningも必要になるため、本手法ではAdvantage-Weighted Actor-Critic (AWAC)と呼ばれる手法を用いました。AWACは、以下の式のように、報酬を最大化するとともに、dataの分布 $\pi_{\beta}$から離れないようにpolicyを学習します。
$$\theta^{\star}=\arg \max \mathbb{E}_{\mathbf{s} \sim \mathcal{D}} \mathbb{E}_{\pi_{\theta}(\mathbf{a} \mid \mathbf{s})}\left[Q_{\phi}(\mathbf{s}, \mathbf{a})\right] \text { s.t. } D_{K L}\left(\pi_{\theta} \| \pi_{\beta}\right) \leq \epsilon$$
これはラグランジアンを用いて、以下のように重み付けありのmaxlmum likelihoodによって近似されます。
$$\theta^{\star}=\underset{\theta}{\arg \max } \mathbb{E}_{\mathbf{s}, \mathbf{a} \sim \beta}\left[\log \pi_{\theta}(\mathbf{a} \mid \mathbf{s}) \exp \left(A^{\pi}(\mathbf{s}, \mathbf{a})\right)\right]$$
ここで$A^{\pi}(\mathbf{s}, \mathbf{a})=Q_{\phi}(\mathbf{s}, \mathbf{a})-E_{\mathbf{a} \sim \pi_{\theta}(\mathbf{a} \mid \mathbf{s})}\left[Q_{\phi}(\mathbf{s}, \mathbf{a})\right]$としています。
この手法を用いてmeta-training後に、必要な場合fine-tuningを行い、未知のタスクのパフォーマンスの最大化を行います。具体的なアルゴリズムは以下の通りになります。

実験
本論文では、12の未知のタスクに対して提案手法を評価するとともに、以下の4つの質問に対して答えました。
1. 通常のoffline RLと比較して良いかどうか
2. 学習に用いたタスクとはとても異なる未知のタスクに対しても、finetuningを行うことで素早く適応することが出来るかどうか
3. 以下の図のようなより難しいタスクに対しても適応することができるかどうか
4. より多くのデータを利用することにより、meta-adaptationが向上するかどうか
実験には、KUKA iiwa7 robotを用いられ、observationとしてTCPのポーズ、速度、tool tipに作用するforce-torque (wrench)が与えられます。ロボットには、各エピソードの初めに、ノイズが一様分布 $U$[-1mm, 1mm]からサンプリングされ与えられます。
Offline datasetとして、下図の11の異なるプラグとソケットのペアからなるデータを集めました。これらのデータはDDPGfDを利用した過去の論文にて学習をした際にreplay bufferに格納したデータをoffline dataとして利用しました。また同様に学習に利用したdemonstrationも本手法の学習に利用しました。

学習済みエンコーダーを用いた未知のタスクに対する適応
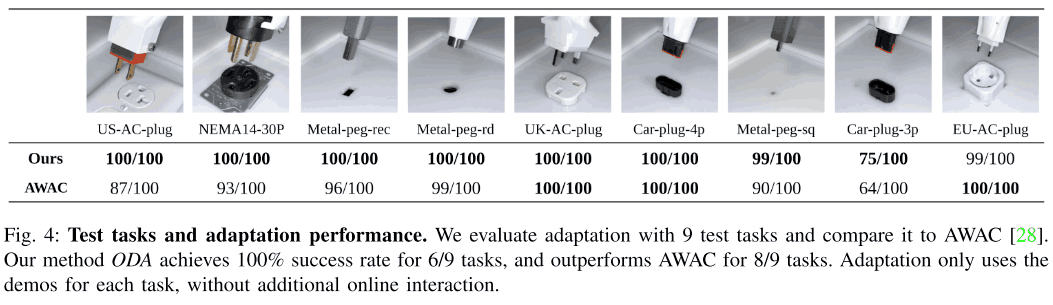
この実験では、学習されたエンコーダーがdemonstrationを利用して未知のタスクに対してどの程度適応することが出来るかを評価しました。この実験では、下図にある9つのテストタスクに関して評価し、各タスクごとに20のdemonstrationを集めました。この実験では、提案手法と通常のoffline RL (AWAC)を学習した際のパフォーマンスの比較を行い、その結果が下図のひょうに示されています。下図から全体的に提案手法が高い成功率を達成することが出来ていることが分かります。
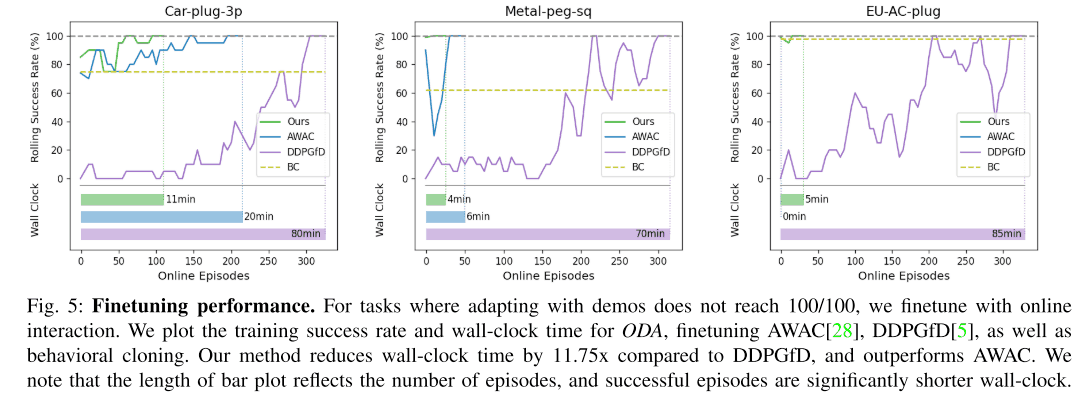
FinetuningによるOut-of-Distribution Taskの適応
この実験では、test時のタスクが、学習に用いられたタスクとは大きく異なる場合にfinetuningを行うことによって素早くそのような未知のタスクに適応することが出来るかどうかを評価しました。比較対象としては、予めpre-trainingを行ったAWAC、DDPGfD、Behavior Cloningの3つになります。下のグラフは結果を表しており、3つのうち2つのタスクにおいて、提案手法がより素早く未知のタスクに適応することが出来ており、成功率100%を達成することが出来ています。また、3つ目のタスクに関しても、提案手法に対して5分のfinetuningを行うだけで成功率100%を達成することが出来ています。また、DDPGfDに関しては、成功率を100%を達成するために一からpolicyを学習するのにかかる時間とほぼ変わらない時間がかかっていることから、提案手法においてoffline RL手法を用いることの重要性が示されています。
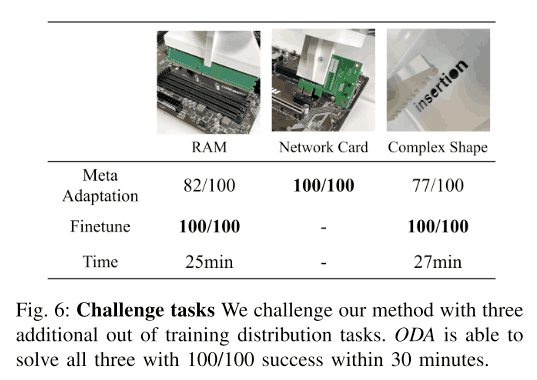
より困難なOut-of-Distributionのタスクに関して
では、より複雑なタスクに関してはどうでしょうか。本論文では下図のような3つのタスクに関して実験をしました。下図の結果の通り、fine-tuningをせずともNetwork Cardでは100%の成功率を、それほかのタスクでは70~80%程度の成功率を達成し、これらのタスクも約25分間のfine-tuningにより、成功率100%を達成することが出来ました。また特に重要なのが、このfine-tuningの間も、motherboardにダメージがないということです。
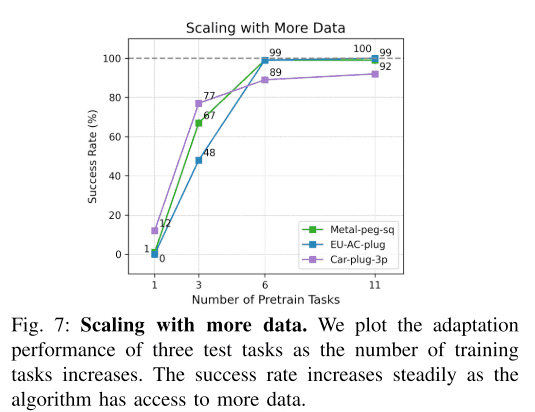
タスクの数と適応後の成功率の関係
最後にタスクのと適応後の未知のタスクの成功率との関係を調べました。この実験ではfine-tuningを行わず、demonstrationのみでの適応を行いました。下図のグラフがその結果になります。下図が示すように、タスクの数が6つの時に成功率がが最大に近づき、それより少ない場合は成功率が大きく下がることが示されています。よって、このことから多くのタスクの学習データを集めることがパフォーマンスに大きく影響することが分かりました。
まとめ
こちらの記事で紹介した論文では、一つのタスクについてのみ解くことに集中し、他のinsertion taskを解く際には一から学習をし直さなければなりませんが、本論文ではその問題点を解決した手法となり、特に実機で新しいタスクごとに長時間のonline trainingをしなくて済むという点からとても有用な手法だと思われます。本手法では、policyのobservationとして低次元のstateを用いたものとなりましたが、今後画像を入力として解くことが出来るかどうかが鍵となるのではないかと考えられます。






この記事に関するカテゴリー






