2つのTransformerが協力して1つの強いGANを作ることが可能!
3つの要点
✔️ 世界初の純粋なトランスフォーマーベースのGAN
✔️ 変形GANを学習するためのメモリフレンドリーな生成器と新しい学習技術のセット
✔️ STL-10ベンチマークにおいて、CNNベースのGANや新しいSOTAと競合する結果を獲得
TransGAN: Two Transformers Can Make One Strong GAN
written by Yifan Jiang, Shiyu Chang, Zhangyang Wang
(Submitted on 14 Feb 2021 (v1), last revised 16 Feb 2021 (this version, v2))
Comments: Accepted to arXiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
はじめに
Generative Adversarial Networks(GAN)は、その誕生以来、学習方法、損失関数、モデルのバックボーン進化により、多くの改良がなされてきました。現在の最先端のGANモデルは、基本的に畳み込みニューラルネットワーク(CNN)をバックボーンとしています。これらのモデルは、初期のGANモデルよりも安定した学習により、豊かで多様な画像を生成することができるようになっています。CNNは画像GANの中心となっており、自己認識をネットワークに統合も行われていますが、CNNが中心であることに変わりはありません。一方トランスフォーマーは、自然言語処理、コンピュータビジョン、音声処理、3D点群処理など、さまざまなタスクに導入されています。そこで、疑問に思うのは当然です。CNNを使用しないトランスフォーマーベースのGANはどのように動作するのだろうか?
この論文では、この疑問に対する答えを探ろうとしており、その結果は非常に興味深いものです。純粋にトランスフォーマーに基づいたGANモデルを見ていきましょう。
また現在のSOTA GANと同等の性能にするために、2つの新しい学習方法を使用しています:局所性を考慮した初期化とデータ増強を伴うマルチタスクの共同学習。
なぜCNNではなくTransformerなのか?
CNNは局所的なピクセル単位では非常によく機能しますが、大域的な特徴をとらえることに関しては弱いことがよく知られています。そのため、大域的な特徴を効果的に捉えるために、CNNを積み重ねて深いネットワークを形成し、対応してきました。またCNNは画像全体で同じ重みを共有するため、空間的な不変性を持っています。一方トランスフォーマーは、大域的な特徴を非常によく捉えることができます。様々なタスクで成功を収めているトランスフォーマーは、潜在的に普遍的な関数推定器であり、コンピュータビジョンにおける複雑なCNNベースのパイプラインを単純化することができます。
純粋なトランスフォーマーによるGANへの道のり
最初は生成器と識別器の両方について、シンプルなモデルから始めます。そして、そのモデルが直面する課題をもとに、適宜変更を加えていきます。
Vanilla TransGAN
TransGANは、multi-headed self-attentionからなるTransformer Encoderと、それに続くGELU非線形のMLPで構成されています。両パートの前には、残差接続とともにレイヤーの正規化が行われます。画像にトランスフォーマーを使用する際の課題として、32×32の低解像度の画像であっても、長さ1024の長いシーケンスになり、多くのメモリを消費することが挙げられます。
![]()
このような大きなシーケンスを生成器で管理するために、目標とする解像度に達するまで、入力シーケンスを徐々にアップスケールし、次元を徐々に下げていきます(上図では32x32x3)。各ステップでは、1次元のシーケンスを2次元のフィーチャーマップ(HxWxC)に変換し、そこにピクセルシャッフルを適用して形状を(2Hx2WxC/4)に変換しています。つまり、アップサンプリングのステップごとに、幅と高さは2倍になり、寸法は1/4になります。そして、目的の形状になったところで、寸法をC=3(HtxWtx3)に変換する。
識別器では、入力画像(HxWx3)を8x8の均等なパッチに変換します(図では例として9パッチのみを示しています)。これらの8x8=64個のパッチはそれぞれフラット化され、埋め込み次元'C'を持つ64個(上図の場合は9個)の "単語 "の列を形成します。[cls]トークンが先頭に付加され、シーケンス全体がトランスフォーマ・エンコーダ層を通過します。図に示すように、[cls]トークンに対応するエンコーディングのみが、分類ヘッドによって、画像が本物か偽物かを予測するために使用されます。
Improving Vanilla TransGAN
TransGANとAutoGAN(CNNベース)を比較するために、2つのモデルの識別器(D)と生成器(G)のあらゆる種類の組み合わせを試しました。下記にCIFAR-10の結果を示します。
![]()
変形器生成器とCNN判別器の組み合わせは非常によく機能しますが、純粋なGANはまだ遅れています。この結果からデータ補強で、学習データを増やすことでそれを助けることで改良します。以下は、CIFAR-10で学習したTransGANや他のSOTAモデルのデータ増強前と後の結果です。
![]()
TransGANはCNNベースのGANよりもデータ増強の恩恵を受けているように感じます。しかし、まだ十分ではありません。次のような手法でTransGANをもう少し鍛えてみましょう。
Multi-Task Co-Training(MM-CT)
![]()
上の図は、マルチタスク共同学習(MM-CT)を示しています。MM-CTは、GANの学習を安定させることができる自己教師タスクです。この方法では、学習画像をダウンサンプルして低解像度の画像(LR)を形成します。これらのLR画像は、ネットワークの中間(2nd)ステージに渡され、高解像度の画像を得るためにモデルが学習されます。標準的なGANの損失に加えて、λ ∗ LSR(LSRは平均二乗誤差損失)を加えています(λは経験的に50)。この2つのタスクは無関係ですが、生成モデルが画像表現を学習するのに役立ちます。
Locality-aware Initialization
CNNは本来、局所的な画像の特徴を捉えるのが得意で、それによって誘導的な画像バイアスにより、より滑らかな画像を生成することができます。トランスフォーマーは学習の柔軟性が高く、CNNのように画像の畳み込み構造を学習させることが課題となります。これは、学習手順を以下のように変更することで実現できる。
![]()
自己学習により、より低レベルの画像構造を学習できるようにするために、局所性を考慮した初期化を行います。上図に示すように、最初はほとんどの画素をマスクし、マスクされていないいくつかの隣接する画素だけが相互作用するようにして学習を開始します。その後、学習を続けながら、受容野を徐々に増やしていき、全くマスクされていないピクセルがなくなるまで、受容野を増やしていきます。これにより、ジェネレーターは局所的なディテールに注意を払い、より細かい画像を形成することができます。そのため、学習の初期段階では局所的な詳細を優先し、その後学習の後期段階ではより広範な非局所的相互作用を優先します。
MM-CTと局所性を考慮した初期化により、次の表に示すように、TransGANの性能が大幅に向上します。
![]()
TransGANのスケールアップと評価
最後に、上記の他の技術と一緒に学習されたバニラのTransGANは、スケールアップする準備ができています。深度(各ステップのエンコーダブロック数)と埋め込みサイズを変えたモデルの結果を以下に示す。
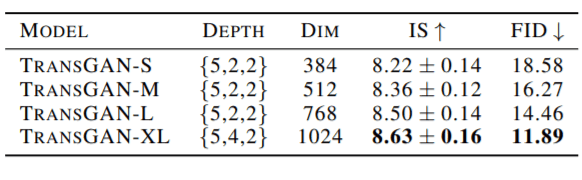
大規模なTransGANモデルの結果は、最先端のCNN GANモデルに匹敵し、さらには優れています。
![]()
TranGANは、STL-10データセットにおいても新たな境地を示すことができた。結果は以下の通りです。
![]()
因みに、生成された画像はどのようなものかというと ここでは、3種類のデータセットで学習したTransGANのサンプルをご紹介します。

結論
TransGANは非常にうまく動作し、変換器のシンプルさと普遍性を示すもう一つの例です。この研究は、純粋な変換GANに関する将来のいくつかの興味深い研究の始まりとなる可能性があります。より高解像度の画像の生成、変換器の事前学習、より強い注意形態の使用、条件付きの画像生成などは、そのうちのいくつかに過ぎません。詳細は原著論文をご覧ください。





この記事に関するカテゴリー






