
時系列トランスフォーマーレビュー
3つの要点
✔️ 近年発表され始めた時系列データ用Transformerの包括的レビュー
✔️ ネットワーク構造と、アプリケーション(予測、異状検知、分類)の両面から分類され、Transformerの強みや限界がレビューされています。
✔️ 将来の展開として、事前学習、GNN、NASとの組み合わせについて解説されています。
Transformers in Time Series: A Survey
written by Qingsong Wen, Tian Zhou, Chaoli Zhang, Weiqi Chen, Ziqing Ma, Junchi Yan, Liang Sun
(Submitted on 15 Feb 2022 (v1), last revised 7 Mar 2022 (this version, v3))
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Signal Processing (eess.SP); Machine Learning (stat.ML)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
背景
Transformerが2017年に発表されて以来、NLP, CV, 会話処理など多くの分野に適用されてきました。最近数多くの論文レビューも発表されています。(NLP1,2, CV3,4,5, 効率的Transformer、アテンション・モデル6,7)
Transformerは系列データの長期レンジ依存性と交互作用のモデル能力を示したため、時系列データモデリングに対しても魅力的です。時系列データに特有の課題に対し、Transformerを変形し対応しています。季節性や周期性と同時に長期・短期依存性を把握することが主な課題の一つです。ここまでに時系列深層学習レビューの一部にTransformerも取り上げられてはいますが、Transformerに関して包括的なレビューはまだ見られません。
この論文では、時系列Transformerの主な開発をまとめます。"バニラ"Transformerについて短く導入した後、ネットワーク改造とアプリケーションからの分類を紹介します。ネットワークについては低レベル、高レベルの両方に触れます。アプリケーションについては、一般的な時系列タスクである予測、異状検知、分類について分析します。それぞれにつき、Transformerの強み、限界について分析しました。実用的なガイドとして、時系列モデリングの多くの様相を調査する広範囲の実験的な研究を行いました。頑強性分析、モデルサイズ分析、季節性トレンド分解分析などです。最後に将来の拡張の可能性についても述べています。
Transformerの復習
"バニラ(素の)"Transformerエンコーダ-デコーダ構造を持ち、最も競争力のあるニューラル系列モデルです。エンコーダ、デコーダはそれぞれ同一の複数のブロックを持ちます。それぞれのエンコーダブロックは、マルチヘッドセルフアテンションモジュールと位置毎の順伝搬モジュールからなります。一方、デコーダはマルチヘッドセルフアテンションと位置毎の順伝搬モジュールの間にエンコーダからの入力を取り込んだクロスアテンションモデルを入れます。
入力エンコーディングと位置エンコーディング
LSTMやRNNとは異なり、Transformerには再発や畳み込みがありません。 代わりに、入力埋め込みに追加された位置エンコーディングを利用して、シーケンス情報をモデル化します。 以下にいくつかの位置エンコーディングを要約します。
・絶対位置エンコーディング
バニラTransformerでは、位置インデックスtごとに、エンコードベクトルは次のように与えられます。
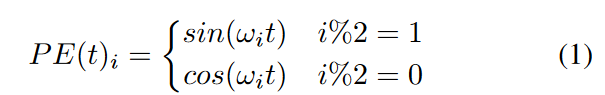
ここで、ωiは各次元に対するお手製の周波数です。 もう1つの方法は、より柔軟な各位置の位置埋め込みのセットを学習することです。
・相対位置エンコーディング
入力要素間のペアでの位置関係が要素の位置よりも有益であるという直感に続いて、相対的な位置符号化方法が提案されてきました。 たとえば、そのような方法の1つは、学習可能な相対位置埋め込みをアテンションメカニズムのキーに追加することです。 絶対位置エンコーディングと相対位置エンコーディングの他に、それらを組み合わせたハイブリッド位置エンコーディングを使用する方法があります。 一般的に、位置エンコードはトークンの埋め込みに追加され、Transformerに送られます。
マルチヘッドアテンション
Query-Key-Value(QKV)モデルでは、Transformerで使用される内積のスケーリングされたアテンションは次のように与えられます。
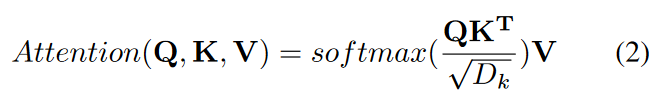
ここで、クエリQ∈RN×Dk、キーK∈RM×Dk、バリューV∈RM×DvおよびN、Mはクエリおよびキー(またはバリュー)の長さを示し、Dk、Dvはキー(またはクエリ)とバリューの次元を示します。 Transformerは、単一のアテンション関数の代わりに、学習された投影のH個の異なるセットでマルチヘッドアテンションを使用します。
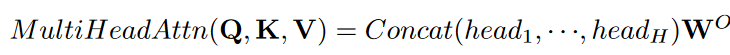
順伝搬と残差ネットワーク
位置毎のフィードフォワードネットワークは、
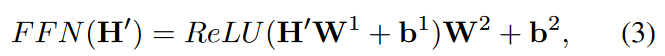
のように完全に接続されたモジュールです。ここで、H'は前の層の出力でありW1∈RDm×Df、 W2∈RDf×Dm、b1∈RDf、b2∈RDmは学習可能なパラメーターです。 より深いモジュールでは、残差接続モジュールとそれに続くレイヤー正規化モジュールが各モジュールの周囲に挿入されます。 つまり、
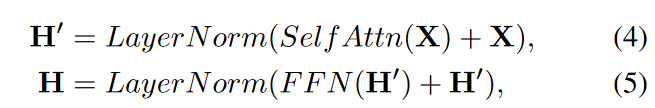
ここで、Self Attn(.)はセルフアテンションモジュールを示し、 LayerNorm(.)は、レイヤー正規化の操作を示します。
時系列Transformerの分類
現存の時系列Transformerを整理するためにFig.1に示す、ネットワーク改造とアプリケーションからみた分類を用意しました。この分類に従い、システマティックに時系列Transformerのレビューを行います。 分類法に基づいて、既存の時系列Transformerを体系的に確認します。 ネットワーク変更の観点から、時系列モデリングの特別な課題に対応するために、Transformerのモジュールレベルとアーキテクチャレベルの両方で行われた変更を要約します。 アプリケーションの観点から、予測、異常検出、分類、クラスタリングなどのアプリケーションタスクに基づいて時系列Transformerを分類します。
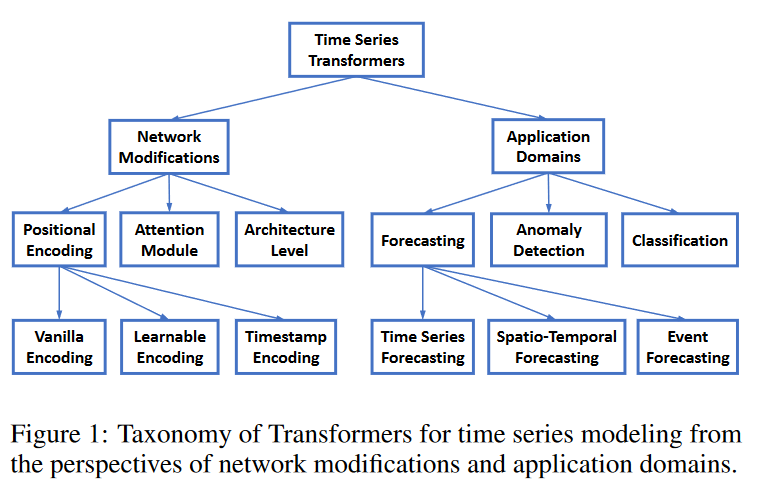
時系列のためのネットワークの改造
位置エンコードTransformerは順列と同等であり、時系列の順序が重要であるため、入力時系列の位置をTransformerにエンコードすることが非常に重要です。 一般的な設計は、最初に位置情報をベクトルとしてエンコードし、次にそれらを入力時系列とともに追加入力としてモデルに注入することです。 Transformerを使用して時系列をモデル化するときにこれらのベクトルを取得する方法は、3つの主要なカテゴリに分類できます。
位置エンコーダ
・バニラ位置エンコーディング
いくつかのワークでは、単純にバニラ位置エンコーディングを導入し、続いて入力時系列埋め込みに追加され、Transformerに供給されます。 この単純なアプリケーションは時系列からいくつかの位置情報を抽出できますが、時系列データの重要な機能を十分に活用することはできませんでした。
・学習可能位置エンコーディング
バニラ位置エンコーディングはお手製であり、表現力と適応性が低いため、いくつかの研究では、時系列データから適切な位置埋め込みを学習する方がはるかに効果的であることがわかりました。 固定バニラ位置エンコーディングと比較して、学習された埋め込みはより柔軟性があり、特定のタスクに適応できます。 Zerveasらは、Transformerに埋め込みレイヤーを導入し、他のモデルパラメーターと一緒に各位置インデックスの埋め込みベクトルを学習します。 Limらは、時系列の順次順序付け情報をより有効に活用することを目的として、LSTMネットワークを使用して位置の埋め込みをエンコードしました。
・タイムスタンプエンコーディング
実際のシナリオで時系列をモデル化する場合、一般的にカレンダーのタイムスタンプ(秒、分、時間、週、月、年など)や特別なタイムスタンプ(休日やイベントなど)などのタイムスタンプ情報にアクセスできます。 これらのタイムスタンプは、実際のアプリケーションでは非常に有益ですが、バニラTransformerではほとんど活用されていません。 この問題を軽減するために、Informerは、学習可能な埋め込みレイヤーを使用して、タイムスタンプを追加の位置エンコードとしてエンコードすることを提案しました。 同様のタイムスタンプエンコーディングスキームが、Autoformer およびFEDformer で使用されました。
アテンション・モジュール
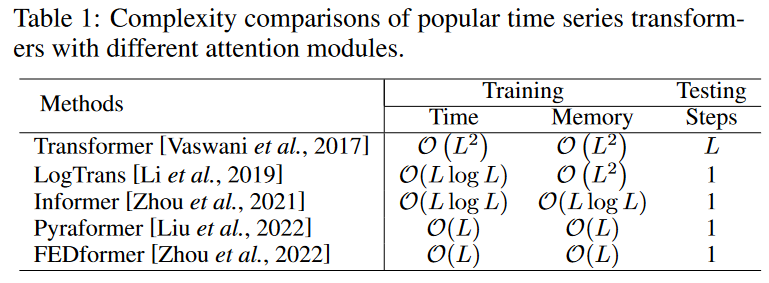
Transformerの中心は、セルフアテンションモジュールです。これは、入力パターンのペアでの類似性に基づいて動的に生成される重みを持つ完全に接続されたレイヤーと見なすことができます。その結果、完全に接続されたレイヤーと同じ最大パス長を共有しますが、パラメーターの数がはるかに少ないため、長期的な依存関係のモデリングに適しています。バニラTransformerのセルフアテンションモジュールの時間とメモリの複雑さはO(L2)(Lは入力時系列の長さ)であり、長いシーケンスを処理する際の計算上のボトルネックになります。2次の複雑さを軽減するために、多くの効率的なトランスフォーマーが提案され、 2つの主要なカテゴリに分類できます。(1)LogTrans やPyraformer のようにアテンションメカニズムにスパースバイアスを明示的に導入、 (2)Informer やFEDformer のように、計算を高速化するために、セルフアテンション行列の低ランクのプロパティを探索。 Table 1に、時系列モデリングに適用される一般的なTransformerの時間とメモリの複雑さの両方を要約します。
アーキテクチャ・レベルの革新
時系列をモデル化するためのTransformersの個々のモジュールに対応することに加えて、いくつかのワークでは、アーキテクチャレベルでTransformerを刷新しようとしています。最近のワークでは、時系列の多重解像度の側面を考慮に入れるために、Transformerに階層アーキテクチャを導入しています。 Informer は、アテンションブロックの間にストライド2の最大プーリングレイヤーを挿入します。これにより、シリーズがハーフスライスにダウンサンプリングされます。 Pyraformer は、C-aryツリーベースのアテンションメカニズムを設計します。このメカニズムでは、最も細かいスケールのノードが元の時系列に対応し、より粗いスケールのノードはより低い解像度の系列を表します。 Pyraformerは、さまざまな解像度にわたる時間的依存関係をより適切に把握するために、スケール内とスケール間の両方のアテンションを開発しました。さまざまなマルチ解像度で情報を統合する機能に加えて、階層アーキテクチャには、特に長い時系列の場合に、効率的な計算の利点もあります。
時系列Transformerの応用
予測
・時系列予測
予測は、時系列の最も一般的で重要なアプリケーションです。 LogTransは、因果的畳み込みを使用してセルフアテンション層でクエリとキーを生成することにより、畳み込みセルフアテンションを提案しました。これは、セルフアテンションモデルにスパースバイアス(Logsparseマスク)を導入し、計算の複雑さをO(L2)からO(L log L)に減らします。 Informer は、スパースバイアスを明示的に導入する代わりに、クエリとキーの類似性に基づいてO(log L)の主要なクエリを選択し、計算の複雑さにおいてLogTransと同様の改善を実現します。また、長期予測を直接生成する生成スタイルデコーダーを設計し、長期予測に1つのフォワードステップ予測を使用する際の累積エラーを回避します。
AST は、生成的敵対的エンコーダ-デコーダフレームワークを使用して、時系列予測用のスパースTransformerモデルを学習します。これは、敵対的なトレーニングが、ネットワークの出力分布を直接形成して、一歩先の推論によるエラーの蓄積を回避することにより、時系列予測を改善できることを示しています。
Autoformerは、アテンションモジュールとして機能する自己相関メカニズムを備えた単純な季節トレンド分解アーキテクチャを考案しています。自己相関ブロックは、従来のアテンションブロックではありません。これは、入力信号間の時間遅延の類似性を測定し、上位k個の類似したサブシリーズを集約して、O(L log L)の複雑さを軽減した出力を生成します。
FEDformer は、フーリエ変換とウェーブレット変換を使用して、周波数領域でアテンション操作を適用します。周波数の固定サイズのサブセットをランダムに選択することにより、線形の複雑さを実現します。 AutoformerとFEDformerの成功により、時系列モデリングの周波数領域でのセルフアテンションメカニズムを探求することがコミュニティでより注目を集めていることは特筆に値します。
TFT は、静的共変量エンコーダー、ゲーティング特徴選択、および時間的自己注意デコーダーを備えたマルチホライズン予測モデルを設計します。さまざまな共変量から有用な情報をエンコードして選択し、予測を実行します。また、グローバルな時間的依存関係とイベントを組み込んだ解釈可能性を維持します。
SSDNet およびProTran は、Transformerを状態空間モデルと組み合わせて、確率的予測を提供します。 SSDNetは、最初にTransformerを使用して時間パターンを学習し、SSMのパラメーターを推定し、次にSSMを適用して季節トレンド分解を実行し、解釈可能な能力を維持します。 ProTranは、変分推論に基づいた生成モデリングと推論手順を設計します。
Pyraformer は、線形時間とメモリの複雑さでさまざまな範囲の時間依存性を捕捉するために、パスをたどる二分木を備えた階層型ピラミッド型アテンションモジュールを設計します。
Aliformer は、知識に基づくアテンションを分岐とともに使用してアテンションマップを修正およびノイズ除去することにより、時系列データの順次予測を行います。
・時空間予測
時空間予測では、正確な予測を行うために、時間依存性と時空間依存性の両方を考慮する必要があります。 Traffic Transformer は、時間的時間的依存関係を捕捉するためのセルフアテンションモジュールと空間的依存関係を捕捉するためのグラフニューラルネットワークモジュールを使用して、エンコーダ-デコーダ構造を設計します。 交通流予測のための時空間Transformerはさらに一歩進んだものです。 時間的依存関係を捕捉するための時間的Transformerブロックを導入するだけでなく、空間空間依存性をより適切に捕捉するために、グラフ畳み込みネットワークとともに空間Transformerブロックも設計します。 時空間グラフTransformerは、歩行者の軌道予測を改善するために複雑な時空間アテンションパターンを学習できるアテンションベースのグラフ畳み込みメカニズムを設計します。
・イベント予測
不規則で非同期のタイムスタンプを持つイベントシーケンスデータは、多くの実際のアプリケーションで自然に観察されます。これは、サンプリング間隔が等しい通常の時系列データとは対照的です。イベント予想または予測は、過去のイベントの履歴を考慮して将来のイベントの時間とマークを予測することを目的としており、多くの場合、時間的点過程(TPP: Temporal Pojnt Process)によってモデル化されます。最近、いくつかのニューラルTPPモデルは、イベント予測のパフォーマンスを向上させるためにTransformerを組み込み始めています。 Self-attentive Hawkes process(SAHP)およびTransformer Hawkes process(THP)は、Transformerエンコーダアーキテクチャを採用して、履歴イベントの影響を要約し、イベント予測の強度関数を計算します。それらは、イベント間の間隔を利用できるように、時間間隔を正弦関数に変換することによって位置エンコーディングを変更します。その後、より柔軟な名前付きの注意深いニューラルデータログ(A-NDTT)が提案され、すべての可能なイベントと時間を注意深く埋め込むことによってSAHP/THPスキームを拡張します。実験によると、既存の方法よりも高度なイベント依存関係をより適切に捕捉できることが示されています。
異状検知
深層学習はまた、異常検出のための新しい開発を引き起こします。深層学習は一種の表現学習であるため、再構成モデルは異常検出タスクで重要な役割を果たします。再構成モデルは、単純な事前定義されたソース分布Qから実際の入力分布P+にベクトルをマッピングするニューラルネットワークを学習することを目的としています。 Qは通常、ガウス分布または一様分布です。異常スコアは、再構成エラーによって定義されます。直感的には、再構成エラーが高いほど、入力分布に起因する可能性が低いことを意味し、異常スコアが高くなります。異常と正常を区別するためにしきい値が設定されます。最近、Mengらは、時間依存性の他の従来のモデル(LSTMなど)よりも異常検出にTransformerを使用することの利点を明らかにしました。より高い検出品質(F1で測定)に加えて、トランスベースの異常検出は、主にTransformerアーキテクチャでの並列計算により、LSTMベースの方法よりも大幅に効率的です。 TranAD 、MT-RVAE 、およびTransAnomaly を含む複数の研究で、研究者はTransformerを異常検出におけるより良い再構成モデルのためにVAEおよびGANのようなニューラル生成モデルと組み合わせるよう提案しました。
TranADは、単純なTransformerベースのネットワークが異常のわずかな偏差を見逃す傾向があるため、再構築エラーを増幅するための敵対的なトレーニング手順を提案します。 GANスタイルの敵対的なトレーニング手順は、安定性を得るために2つのTransformerエンコーダーと2つのTransformerデコーダーによって設計されています。切り分け調査によると、Transformerベースのエンコーダデコーダを交換すると、F1スコアのパフォーマンスが11%近く低下し、異常検出に対するTransformerアーキテクチャの重要性を示します。
MT-RVAEとTransAnomalyはどちらもVAEとTransformerを組み合わせていますが、目的は異なります。 TransAnomalyは、VAEとTransformerを組み合わせて、より多くの並列化を可能にし、学習コストを約80%削減します。 MT-RVAEでは、マルチスケールTransformerは、さまざまなスケールで時系列情報を抽出して統合するように設計されています。これは、ローカル情報のみが順次分析のために抽出される従来のTransformerの欠点を克服します。いくつかの時系列Transformerは、TransformerをGTAなどのグラフベースの学習アーキテクチャと組み合わせた多変量時系列用に設計されています。 MT-RVAEも多変量時系列用ですが、次元が少ないか、グラフニューラルネットワークモデルがうまく機能しないシーケンス間の密接な関係が不十分であることに注意してください。このような課題に対処するために、MT-RVAEは位置エンコーディングモジュールを変更し、機能学習モジュールを導入します。 GTAには、影響伝播プロセスをモデル化するためのグラフ畳み込み構造が含まれています。 MT-RVAEと同様に、GTAも「グローバル」情報を考慮しますが、バニラマルチヘッドアテンションをマルチブランチアテンションメカニズム、つまりグローバル学習アテンション、バニラマルチヘッドアテンション、および近隣畳み込みの組み合わせに置き換えます。
AnomalyTrans は、TransformerとGaussian Prior-Associationを組み合わせて、まれな異常をより識別しやすくします。 TranADと動機は同じですが、AnomalyTransは非常に異なる方法でこの目標を達成します。異常がシリーズ全体との強い関連を構築するのは難しいが、正常と比較して隣接する時点では容易であると洞察できます。 AnomalyTransでは、事前関連付けとシリーズ関連付けが同時にモデル化されます。再構成の損失に加えて、異常モデルはミニマックス戦略によって最適化され、より識別可能な関連の不一致のために事前関連と系列関連を制約します。
分類
Transformerは、長期的な依存関係を捕捉する優れた機能により、さまざまな時系列分類タスクで効果的であることが証明されています。 分類Transformerは通常、セルフアテンション層が表現学習を実行し、フィードフォワード層が各クラスの確率を生成する単純なエンコーダー構造を採用しています。
GTNは、2タワーのTransformerを使用しており、各タワーはそれぞれ時間ステップごとのアテンションとチャネルごとのアテンションを実行します。 2つの塔の機能を統合するために、学習可能な加重concat(「ゲーティング」とも呼ばれます)が使用されます。 Transformerの提案された拡張は、13の多変量時系列分類でSOTAの結果を達成します。 Rußwurmらは、生の光衛星時系列分類のためのセルフアテンションベースのTransformerを研究し、RNNおよびCNNと比較して最良の結果を得ました。
事前学習Transformerも分類タスクで調査されます。 Yuanらは、生の光学衛星画像の時系列分類のためにTransformerを研究しています。 ラベル付けされたデータが限られているため、筆者は自己教師の事前学習スキーマを使用します。 Zerveas らは、教師なし事前学習フレームワークを導入し、モデルは比例的にマスクされたデータで事前学習されています。 事前学習されたモデルは、分類などの下流タスクで微調整されます。 Yangらは、下流の時系列分類問題に大規模な事前学習音声処理モデルを使用することを提案し、30の有名な時系列分類データセットで19の競合する結果を生成します。
実験
頑強性分析
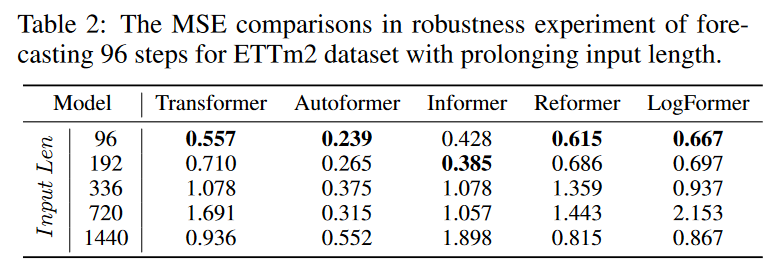
上記で説明した多くのワークでは、2次式計算とメモリの複雑さを軽減するようにアテンションモジュールを慎重に設計しますが、報告された実験で最良の結果を達成するために、実際には短い固定サイズの入力を使用します。 そのような効率的な設計の実際の使用には疑問を残します。 入力シーケンスの長さを延長して頑強な実験を実行し、長期の入力シーケンスを処理する際の予測力と頑強性を検証します。 Table 2に示すように、予測結果を入力長の延長と比較すると、さまざまなTransformerベースのモデルが急速に劣化します。 この現象により、慎重に設計された多くのTransformerは、長い入力情報を効果的に利用できないため、長期的な予測タスクでは実用的ではありません。 単に実行する以外に、長いシーケンス入力を十分に活用するには、さらに多くの作業を行う必要があります。
モデルサイズ分析
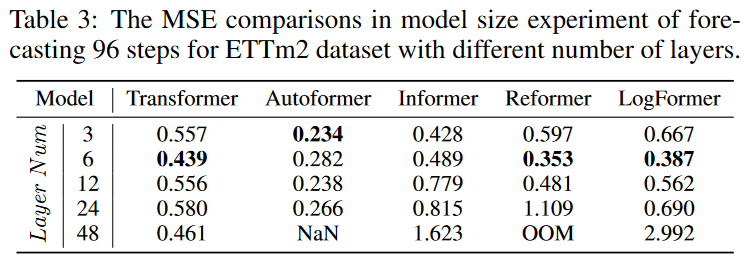
時系列予測の分野に導入される前に、TransformerはNLPおよびCVコミュニティで卓越したパフォーマンスを示しました。 Transformerがこれらの分野で持つ重要な利点の1つは、モデルサイズを大きくすることで予測力を高めることができることです。 通常、モデルの容量はTransformerのレイヤー番号によって制御されます。レイヤー番号は通常、CVとNLPで12〜128の間に設定されます。 しかし、Table 3の実験に示されているように、さまざまなレイヤー番号を持つさまざまなTransformerモデルで予測結果を比較すると、3〜6レイヤーの最も浅いTransformerが勝利します。 モデルの容量を増やし、より良い予測パフォーマンスを実現するために、深いレイヤーを備えた適切なTransformerアーキテクチャを設計する方法について疑問が生じます。
季節性トレンド分解分析
最新の研究では、研究者は、季節トレンドの分解が時系列予測におけるTransformerのパフォーマンスにとって重要な部分であることに気づき始めました。 Table 4に示す簡単な実験として、Wuらが提案した移動平均傾向分解アーキテクチャを使用して、さまざまなアテンションモジュールをテストします。 季節トレンド分解モデルは、モデルのパフォーマンスを50%から80%大幅に向上させることができます。 これは独自のブロックであり、分解によるこのようなパフォーマンスの向上は、Transformerのアプリケーションの時系列予測において一貫した現象のようであり、さらに調査する価値があります。

さらなる研究の機会
誘導バイアス
バニラTransformerは、データのパターンと特性について何も想定していません。 これは、長距離の依存関係をモデル化するための一般的で普遍的なネットワークですが、コストも伴います。つまり、データの過剰適合を回避するためにTransformerをトレーニングするには大量のデータが必要です。 時系列データの重要な特徴の1つは、その季節/周期的および傾向パターンです。 最近のいくつかの研究では、時系列Transformerに系列周期性または周波数処理を組み込むとパフォーマンスが大幅に向上することが示されています。 したがって、将来の方向性の1つは、時系列データと特定のタスクの特性の理解に基づいて、Transformerに誘導バイアスを誘導するためのより効果的な方法を検討することです。
TransformerとGNN
多変量および時空間時系列は、アプリケーションでますます一般的になり、高次元を処理するための追加の手法、特に次元間の基本的な関係を捕捉する機能が必要になります。 グラフニューラルネットワーク(GNN)の導入は、空間依存性または次元間の関係をモデル化するための自然な方法です。 最近、いくつかの研究により、GNNとTransformer/アテンションの組み合わせにより、交通予測およびマルチモーダル予測のようにパフォーマンスが大幅に向上するだけでなく、時空間ダイナミクスと潜在的な因果関係についてのより良い理解をもたらしえます。 時系列で効果的に時空間モデリングを行うために、TransformerとGNNを組み合わせることが将来の重要な方向性です。
事前学習Transformer
大規模な事前学習済みのTransformerモデルにより、NLPおよびCVのさまざまなタスクのパフォーマンスが大幅に向上しました。 ただし、時系列用に事前にトレーニングされたTransformerに関するワークは限られており、既存の研究は主に時系列分類に焦点を当てています。 したがって、時系列の異なるタスクのための適切な事前学習Transformerモデルを開発する方法は将来の研究にゆだねられています。
NAS付Transformer
埋め込み次元、ヘッド数、レイヤー数などのハイパーパラメーターは、Transformerのパフォーマンスに大きく影響する可能性があります。 これらのハイパーパラメータを手動で設定するには時間がかかり、パフォーマンスが最適化されないことがよくあります。 ニューラルアーキテクチャ検索(NAS)は、効果的な深層ニューラルアーキテクチャを発見するための一般的な手法であり、NLPおよびCVでNASを使用してTransformerの設計を自動化することは最近の研究で見つけることができます。 高次元と長い長さの両方が可能な業界規模の時系列データの場合、メモリ効率と計算効率の両方のTransformerアーキテクチャを自動的に検出することが実用上重要であり、時系列Transformerの将来の重要な方向性になります。
まとめ
この論文では、さまざまなタスクにおける時系列Transformerに関する包括的な調査を提供しています。 レビューされた手法を、ネットワークの変更とアプリケーションドメインで構成される新しい分類法にまとめました。 各カテゴリーの代表的な手法をまとめ、実験的評価によりその長所と短所を議論し、今後の研究の方向性を浮き彫りにしています。






この記事に関するカテゴリー






