
畳み込み vs Transformer!次のステージへ!新たな画像認識モデルVision Transformer
3つの要点
✔️ Transformerを使った新たな画像分類モデル
✔️ 入力には元の入力画像を分割し、パッチを作ることが特徴
✔️ 最先端のCNNモデルと同等もしくは上回る結果を記録
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
written by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby
(Submitted on 22 Oct 2020)
Comments: Accepted at arXiv
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)


はじめに
これまで存在していた画像分類モデルの多くは、畳み込みニューラルネット(CNN)が用いられていました。しかし、今回発表されたモデルは一切CNNを使わず、Transformerのみを使って構成されたモデルです。モデルの名前はVision Transformer (以下 ViT)と言います。
Transformerは、2017年に発表されてから、いまでは自然言語処理の分野においてファクトスタンダードとなっていましたが、画像処理の分野への応用は限られたものでした。どのようにして、Transformerを画像分類タスクに適応させることに成功したのか、そして注目のその精度はいかなるものなのかをまとめてみました。
Transformer
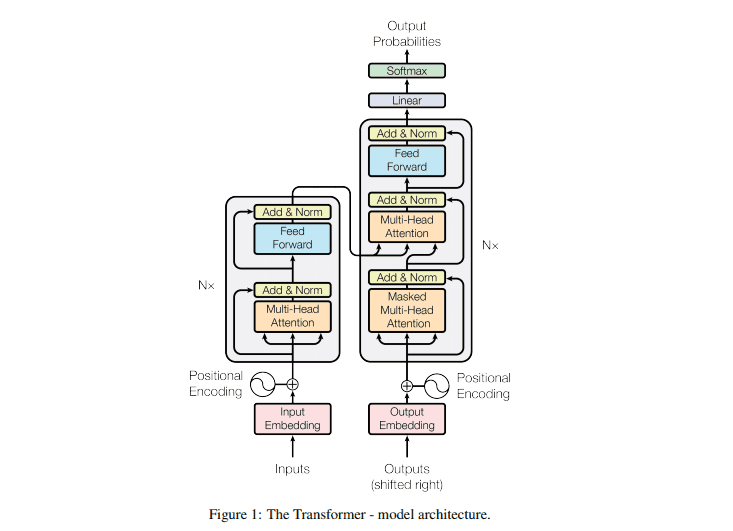
Transformerは、もともとそれ自体が持つスケーラビリティが注目されていました。通常、モデルを大きくしたとしても学習が進まなくなることがありますが、Transformerはモデルが大きくなっても学習ができるという特徴があります。また、Transformerの計算能力を向上させるさまざまな研究も行われてきました。
ですが、Transformerが得意とするのは文章などのシーケンスデータ、すなわち連続性のあるデータです。さらにTrasformerは入力シーケンスの要素同士の類似度を計算するため、画像のピクセル単位で利用すると計算要素が膨大なものになってしまうのが欠点でした。(例えば224×224画素の画像を使うと、(224×224)2 = 2,517,630,976 分の計算が必要になります)これにより、Transformerが画像処理のタスクに適用されてきませんでした。
続きを読むには
(6764文字画像25枚)AI-SCHOLARに
登録いただく必要があります。



この記事に関するカテゴリー





