3次元モーション推定!画像内の人間の動きを3次元で再現!
3つの要点
✔️静止画像内の人物の3次元モーションを復元
✔️オンライン上に存在する大量のラベル無しデータを使用して半教師あり学習を実施
✔️3DPWというデータセットを使用して実験を行い、state of the artを獲得
近年、人の動作を3次元で復元するというタスクが様々な業界で行われています。例えばスポーツ業界では、選手のフォームチェックや試合のリプレイ再生などで既に導入されています。しかし、人の動作を3次元で復元するためには様々な機材や優秀なエンジニアが必要であり、多くのコストがかかるため、「気軽に行うことができない」という課題を抱えています。今回はこの課題を将来的に解決する可能性を秘めた研究を紹介していきたいと思います。
今回の研究の目的は一言で表すと「静止画像内の人物の3次元モーションを復元すること」です。具体的には、図1のようにビデオ中のある時点におけるフレームから過去と現在そして未来の一連の動作を復元します。著者らはこのチャレンジングな目的を達成するためにResNetを元にしたモデルを構築し、提案しました。
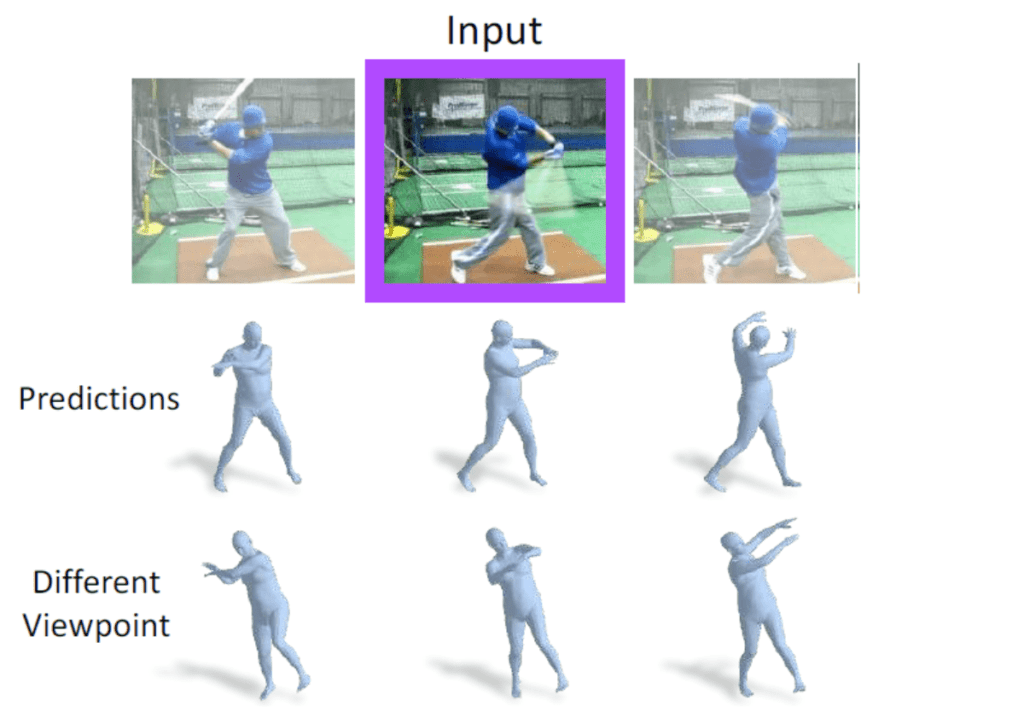
図1 3次元モーション復元の様子
また、今回のような画像やビデオをデータセットとして用いる研究には往々にして「ラベル付きデータセットの不足」という問題がつきまといます。特に、今回使用するデータセットはビデオのフレーム1枚1枚に3次元の姿勢や形状に関するラベルを付与する必要があり、アノテーションコストは膨大なものとなります。そこで、著者らはインスタグラムへの投稿を始めとしたオンライン上の大量のラベル無しデータセットを使用して半教師あり学習を行うという解決策を提案しました。
それでは、これから具体的な研究内容についてご紹介していきたいと思います。
提案手法
データ
まず、入力データですが、これは「ビデオ中のある時点におけるフレーム(2次元静止画像)」となります。また、入力データのラベルについては、3次元ラベル付きデータ、2次元ラベル付きデータ、ラベルなしデータの3つが存在し、それぞれ以下のようになってます。
- 3次元ラベル付きデータ
- 形状情報に関するラベル
- 3次元姿勢情報に関するラベル
- 2次元姿勢情報に関するラベル
- カメラの位置に関するラベル
- 2次元ラベル付きデータ
- 形状情報に関するラベル
- 2次元姿勢情報に関するラベル
- カメラの位置に関するラベル
- ラベルなしデータ
- 2次元姿勢情報に関する疑似ラベル(OpenPoseを用いて付与)
モデル
次に、モデルの説明に移ります。図2が著者らが提案したモデルです。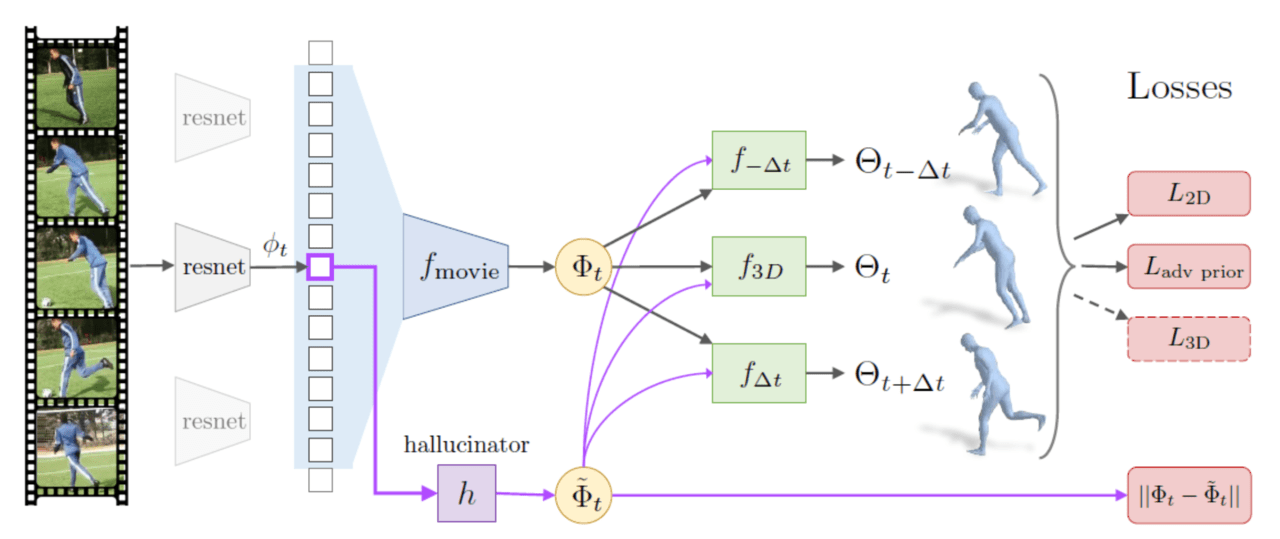
図2 提案モデル
まず、入力データはResNetによって学習が行われ、特徴量φを出力します。次に、特徴量φをfmovieに入力すると、人の実際の動きを表現する特徴量であるΦを出力します。最後に、特徴量Φをft-Δt、f3D、ft+Δtに入力すると、過去、現在、未来の一連の3次元メッシュの構成に必要なパラメータであるΘt-Δt、Θt、Θt+Δtを出力します。また、hallucinatorによって人の動きを表現する特徴量を生成し、実際の特徴量であるΦと比較します。
半教師あり学習
半教師あり学習とは、ラベル付きデータとラベルなしデータの両方を用いた学習手法です。今回の研究では以下のような手順で学習を行います。
- インターネット上からラベルなしデータ(インスタグラムへの投稿など)を取得
- OpenPoseを用いてラベルなしデータに2次元姿勢情報に関する疑似ラベルを付与
- 疑似ラベルが付与されたラベルなしデータとラベル付きデータを用いてモデルを学習
OpenPoseとは、二次元静止画像内の人間の姿勢情報(関節点)を高精度で検出できるモデルです。このような手順で学習を行うことで、数に限りのあるラベル付きデータだけでなく、インターネット上に大量に存在するラベルなしデータも有効に活用することができます。
実験
データセット
まず、今回の実験で使用するデータセットについて紹介していきます。
Human3.6M(H36M)
3次元ラベル付きデータセット。約6時間半のビデオ。今回の実験では、モデルの学習及び精度評価で用いる。
3DPW
3次元ラベル付きデータセット。今回の実験では、モデルの精度評価のみに用いる。
Penn Action(Penn)
2次元ラベル付きデータセット。分量は約1時間弱。15のスポーツのプレイシーンが収められている。今回の実験では、モデルの学習及び精度評価に用いる。
NBA
2次元ラベル付きデータセット。分量は約30分弱。NBAでの16試合分の3ポイントシュートのシーンが収められている。著者らが作成した。今回の実験では、モデルの学習及び精度評価に用いる。
VLOG people
ラベルなしデータセット。分量は約4時間。VLOG(VideoとBlogから成る造語) lifestyle datasetの一部。今回の実験では、モデルの学習のみに用いる。
Insta Variety
ラベルなしデータセット。分量は約1日。インスタグラムの投稿のうち、#instructionや#swimming、#dancingなどのハッシュタグ(84種類)が付けられた投稿を収集した。著者らが作成した。今回の実験では、モデルの学習のみに用いる。
以上の6種類のデータセットを今回の実験では用います。
実験
今回の研究では以下のような2種類の実験を行っています。
- 静止画像内の人物の3次元メッシュモデルの復元
- 静止画像内の人物の3次元モーションの復元
それでは、上記の2つの実験の詳細をそれぞれまとめていきます。
静止画像内の人物の3次元メッシュモデルの復元
静止画像に写っている人物の3次元メッシュモデルの復元を行います。実際の入力と出力を図3に示します。

図3 静止画像内の人物の3次元メッシュモデルの復元の様子
1行目の画像が入力であり、2行目の3次元メッシュモデルがそれぞれの入力に対応した出力となります。また、3行目のメッシュモデルは2行目のメッシュモデルを別視点から見たものとなります。
また、表1が実験結果になります。
表1 既存手法との比較
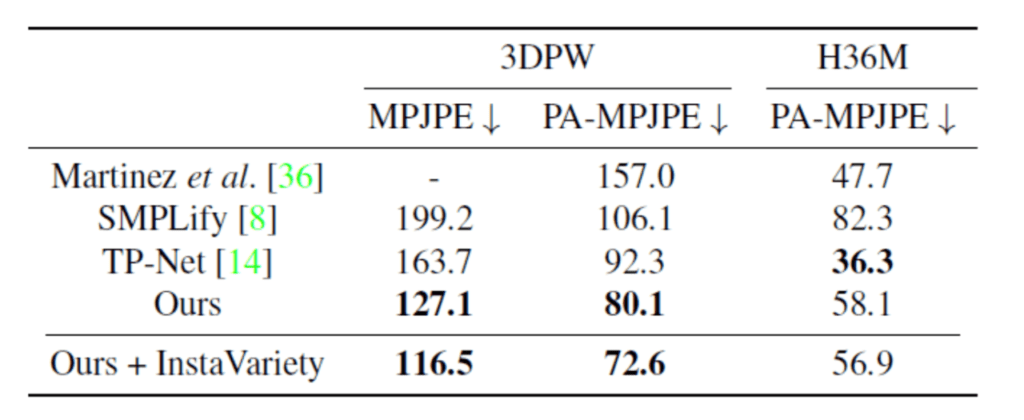
MPJPEというのは、各関節点での誤差(単位:mm)の平均を表しており、これが小さいほど精度が良いと言えます。PA-MPJPEは物体の大きさや位置、回転といった要素を考慮して各接点での誤差(単位:mm)を計測し、それを平均したものであり、これもまた小さいほど精度が良いと言えます。また、Oursはラベル付きデータセットのみを使用した教師あり学習であり、Ours+InstaVarietyはラベル付きデータセットに加えてラベル無しデータセットであるInsta Varietyを使用した半教師あり学習です。表1を見てみると、3DPWというデータセットにおいてこれまでstate of the artを獲得していたTP-Netの精度を提案手法が上回っていることが分かります。
静止画像内の人物の3次元モーションの復元
静止画像に写っている人物の3次元モーションの復元を行います。実際の入力と出力を図4に示します。

図4 静止画像内の人物の3次元モーションの復元の様子
1行目の画像が入力であり、2行目の3次元メッシュモデルがそれぞれの入力に対応した出力となります。また、3行目のメッシュモデルは2行目のメッシュモデルを別視点から見たものとなります。
また、表2が実験結果になります。
表2 ベースラインとの比較
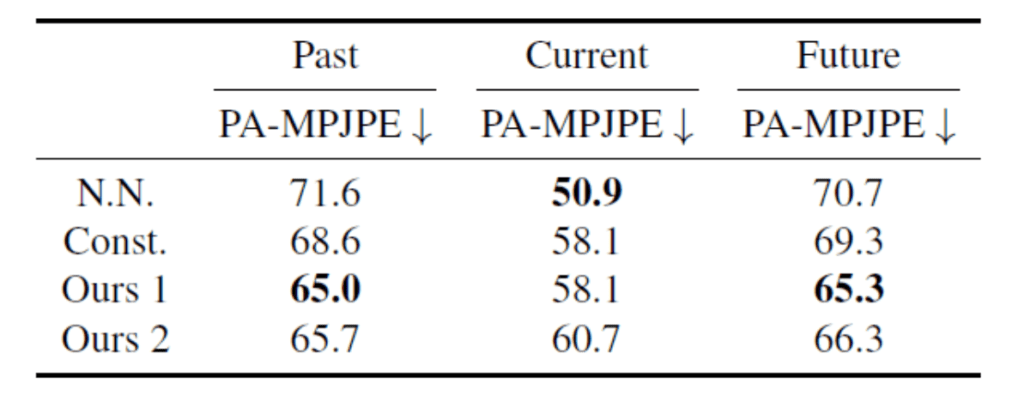
静止画像内の人物の3次元モーションの復元を試みたのは今回の研究が初めてであり、既存研究が存在しないため、比較するベースラインが存在しません。そこで、現在のフレームワークから過去と未来のフレームワークを予測した時の予測性能(Const.)と最近傍法による予測結果(N.N.)をベースラインとして設定しました。また、Ours 1はhallucinatorによって生成された人の動きを表現する特徴量と実際の特徴量であるΦとの誤差を提案モデルの誤差関数に含めたモデルであり、Ours 2は含めなかったモデルになります。表2を見てみると提案手法が過去と未来のフレームワークの予測精度において優れた結果を残していることが分かります。
まとめ
本記事では、「静止画像内の人物の3次元モーションの復元」を試みた研究を紹介しました。今回の研究には以下の2つの貢献があります。
- 静止画像内の人物の3次元モーションの復元に初めて試みる
- 3次元姿勢情報推定のタスクにおいて、2次元姿勢情報の疑似ラベルを付与したデータを用いた半教師あり学習によって精度を向上させることが可能なことを示した
まず1つ目の貢献についてですが、「静止画像内の人物の3次元モーションの復元」に初めて試みたことは非常に大きな貢献でした。この研究はスポーツ業界だけでなく様々な業界で応用することが可能です。例えば、防犯カメラが取得した画像に適用することで、犯罪者の3次元モーションを復元することが可能となり、犯罪発生時に捜査をサポートすることができます。また、職人の動きを録画したビデオに適用することで、職人の動きを3次元で観察することが可能となり、技術継承をサポートする事もできます。この他にも様々な応用先を考えることができます。
次に2つ目の貢献についてですが、半教師あり学習が3次元姿勢推定に効果があることを示したことも非常に大きな貢献でした。特に今回の研究では、3次元姿勢を推定するタスクにおいて、ラベル無しデータセットに3次元姿勢情報ではなく2次元姿勢情報をラベル付けし、精度の向上を図りました。ラベル無しデータに付与するラベルが他のラベル付きデータのラベルよりも情報量が小さくても精度の向上に繋がることは重要な知見であり、他のタスクにも応用が利きます。3次元姿勢推定のようにラベルの情報量が大きく、かつ付与しづらい同様のタスクにも応用できる可能性はあるので是非試してみる価値があるかもしれません。
本記事を読んで今回の研究に興味が湧いた方は是非、論文の方も読んでみてください。また、今回使用したデータセットやモデルのソースコードは以下のサイトで公開されています。合わせて確認してみてください。
https://github.com/akanazawa/human_dynamics/tree/master
Learning 3D Human Dynamics from Video
written by Angjoo Kanazawa, Jason Y.Zhang, Panna Felsen, Jitedra Malik
(Submitted on 20 Aug 2019)Accepted to CVPR2019
Subjects: Computer Vision





この記事に関するカテゴリー






