源氏物語を解読するAI、また一つ人間の仕事を代替か
論文:https://arxiv.org/abs/1812.01718://arxiv.org/abs/1812.01718
(1)『日本人は150年前の文書が読めない』
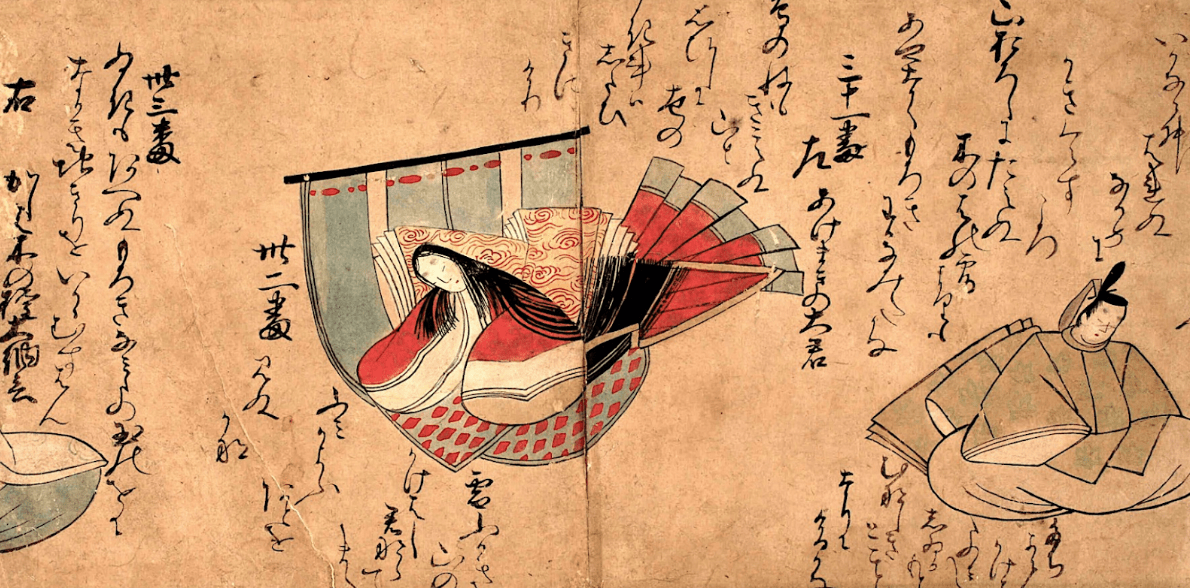
この写真は『源氏歌合絵巻』の一部ですが、現代のほとんどの日本人にとって読めるものではないでしょう。一部ひらがなだと推測できる文字もありますが、それがどのひらがななのか当てるのはかなり困難です。
国書総目録によると、日本には古代から大政奉還が行われた1867年までで170万の本が発行されており、登録されていない文書等を含めると古文書の数は数億に登ると推測されています。現在古文書は国が管理しているものもあれば各地方で保管されているものも多く、地方では古文書が見つかっても読める専門家がいない、といった事態も起こっています。
この現状に着目したのがGoogle BrainのDavid Haさんです。彼は以前から落書きデータセットを使って『落書きができるAI』、漢字データセットを使って『漢字が書けるAI』などの開発、公開をしてくるなど手書きAIのパイオニア的存在ですが、今回日本の国文学研究資料館と共同で古文書解読AIに必要な「くずし字データセット」を用意し、公開しました。
さらに「くずし字ひらがな」認識AIと「くずし字漢字」を「現代漢字」に書き起こすAIを開発しています。
今回紹介するこの論文は、実はAI技術としての新規性はほぼないのですが、AI技術の応用例として面白い内容になっています。
(2) 文字認識AI
文字認識の一般的なアプローチは技術的に次の2つのステップに分けられます。一つは画像から文字の場所を推論すること、もう一つはその文字が何かを推論すること、です。
これらをまとめて行ってくれるのがOCR(光学式文字認識)と呼ばれる技術で、Google(Cloud Vision)やMicrosoft(Computer Vision), Amazon(Amazon Rekognition)などが誰でも簡単に使えるようなサービスを公開しています。

これらの既存技術は、文字の大きさや太さが揃っていることや、数字認識であれば10種類、英語アルファベット認識であれば26種類などと分類対象の文字の種類がある程度限られていることが多いです。
しかし日本の「くずし字」の難しさは段違いです。文字の大きさや太さはバラバラで、また同じひらがなでも元となった漢字が違うために少し異なった形になっていることもあるなどと、文字認識をするにしても『その文字がどの文字か』を推論する部分がかなり難しいものとなっています。

(同じひらがな「か」でも元となった漢字が違うために様々な形が発見されている例)
しかし、日本は長く西洋の文化から孤立していたこともあって日本の古文書は世界的に見ても高い価値があると考えられており、AIを使った「くずし字」認識に期待が高まっています。
(3) くずし字データセット
今回の論文の主な貢献は、「くずし字データセット」というものを作って公開したところになります。実際にこちらで公開されています。データセットが用意されることで、古文書解析の研究を古文書の専門家ではなくてもはじめられるようになりました。
公開されたデータセットは「Kuzushiji-MNIST」, 「Kuzushiji-49」, 「Kuzushiji-Kanji」の3つに分けられます。

(Kuzushiji-MNIST)

(Kuzushiji-Kanji)
Kuzushiji-MNISTは、10種類のひらがなだけを集めたデータセットです。こちらはMNISTという手書き数字データセットで最も有名なものをリスペクトしたデータセットとなります。
Kuzushiji-49はひらがな49種類を集めたもので、Kuzushiji-MNISTを拡張したような内容になっています。各文字につき約7000字のデータが収録されています。
Kuzushiji-Kanjiは3832種類の漢字が全部で140,426字分収録されています。収録されている画像の量が漢字の種類によってかなりばらつきがあるので注意が必要です。
(4) 実験
まず「Kuzushiji-MNIST」, 「Kuzushiji-49」を使った文字認識の実験を紹介します。論文では特に新しいAIモデルは提案しておらず、数字やアルファベットの認識に使われる一般的な画像認識AI(CNN)で実験しています。
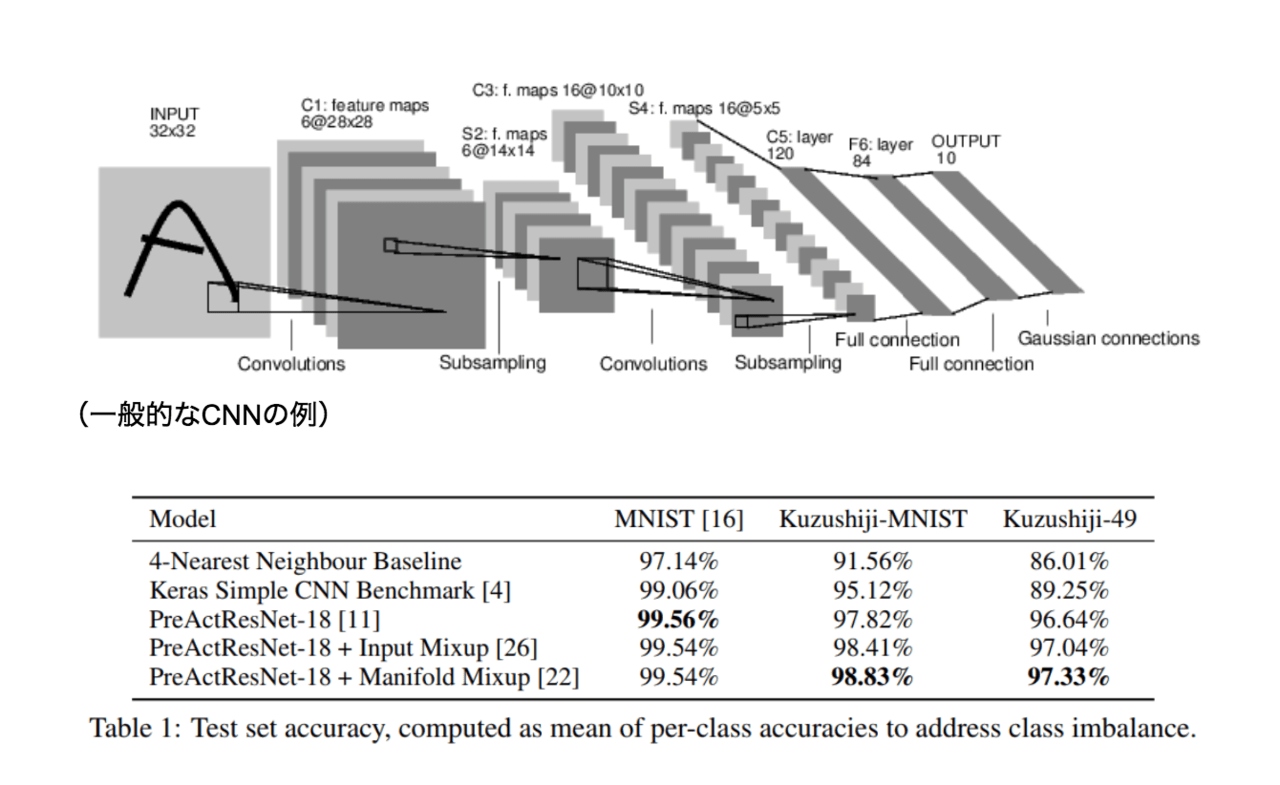
論文では5種類の認識モデルを使っており、1つ目が機械学習を使わないモデル、2つ目が一般的なCNNの例として上にあげた図のようなシンプルな機械学習モデル、3~5つ目が、デファクトスタンダードといえる画像認識モデル「ResNet」を使ったモデルになっています。
「くずし字」は一見とても複雑ですが、実は他の文字認識で使われている手法を転用するだけでかなり高い精度での認識ができてしまうことがわかります。
しかし論文では「Kuzushiji-Kanji」の認識実験だけなかったので、漢字は難しすぎて既存の文字認識モデルではうまくいかないことが伺えます。
次に、「Kuzushiji-Kanji」を使った、くずし字漢字の画像データを現代漢字に書き起こす実験を紹介します。

「書き起こす」というのは、実際に一画ずつペンで書くように文字を生成することを指しており、「書き起こしAI」を「ペンを持ったロボット」に適用すれば実際に文字を書くことができるようなものとなっています。
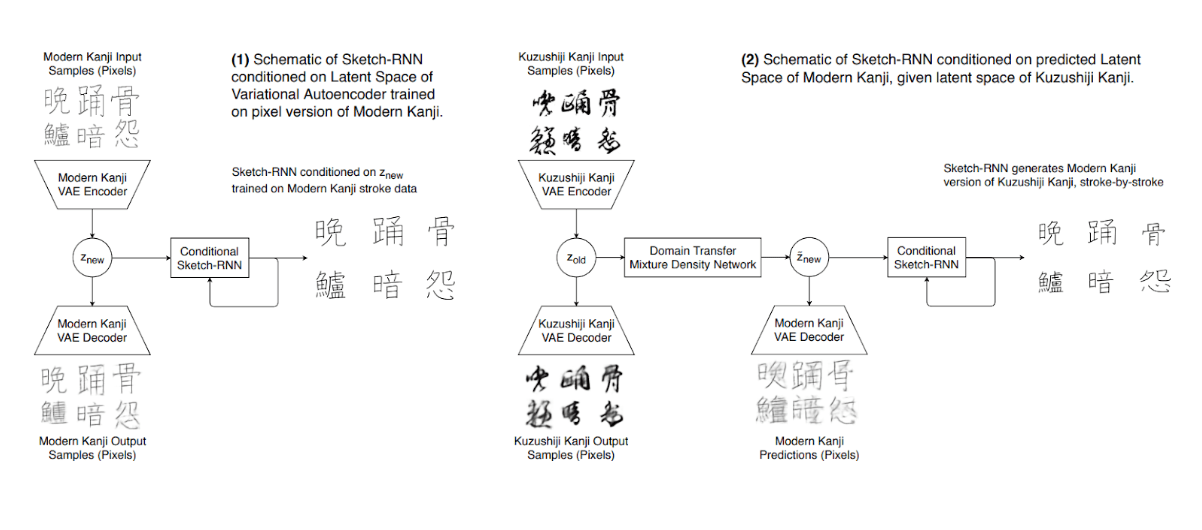
こちらの実験では「ドメイン適応」と呼ばれるAI技術を用いています。
一見複雑ですが既存手法の組み合わせで実現しています。
大きく分けて5ステップの学習で書き起こしAIを作ることができます。
まず第一ステップでは、図中に蝶ネクタイを縦向きにしたようなものが2つありますが、そのうち左側で「現代漢字」自体がどんなものか学習します。この学習は、文字の画像を効率よく圧縮して正しく復元する方法を自動的に獲得するような学習をさせることによってなされます。これによって、現代文字の画像から効率よく圧縮された、つまり特徴量が詰まったデータ(図のz_new)を得ることができます。これはVAE(Variational Auto Encoder)と呼ばれ、生成系のAIを中心に幅広く使われている技術です。
第二ステップでは、z_newを使って現代文字を書き起こすSketch_RNNというAIを学習させます。書き順データも含まれている現代漢字データセットを使って、漢字画像の特徴z_newを教えられると、ペンを書き進める(実際にはペンを紙に接地するか、離すか、ペンをどの方向に少しずらすかを適切に判断しています)ことができるよう、書き順を真似るようなAIを作ります。
第三ステップでは第一ステップと同様に、図中の蝶ネクタイのような部分のうち中央にある部分で「くずし字漢字」自体がどんなものかを、第一ステップと同じ機能を持つ別のモデルを用意して学習させます。これによってくずし字漢字からその特徴量が詰まったデータ(z_old)を得ることができます。
第四ステップで、z_oldをz_newに変換するAIを用意します。これには混合ガウスモデルという古典的機械学習手法を拡張したMDN(Mixture Density Network)を用いています。z_oldを、同じ漢字に対応するz_newに正しく変換できるように学習を行います。
ここまでで、ほとんど書き起こしAIは完成です。察しがよい方はわかったかもしれませんが、まず「くずし字漢字画像」を真ん中のVAE(蝶ネクタイ)でz_oldに圧縮し、MDNでz_newに変換、それを現代漢字のSketch_RNNの入力として与えると、書き起こしが実現します。
さらに仕上げとして第五ステップで、「くずし字漢字画像」から書き起こしまでを通して精度良く行えるようにSketch_RNNを再学習させます。(Sketch_RNNは現代漢字の特徴データz_newを受け取って文字を書きますが、もともとくずし字漢字を圧縮したものをさらに変換して作られたz_newを使うと、書き起こしの精度がどうしても悪くなってしまうためです。)
以下が結果になります。

見事に昔の潰れているようにも見える漢字画像から鮮明な現代漢字を生成することができています。しかしよく見ると生成される漢字にブレがあることがわかります(例えば右から2番目の生成漢字を見ると、「体」と「休」が含まれています)。くずし字漢字はくずし過ぎているせいもあってか完全に漢字を一意に推論することはAIにとっても難しいことが伺えます。
しかしそれは人間にとっても同じことであって、今回のAIを使って、くずし字を現代文字に変換し、データ化や現代語訳する際のサポート役として大いに活躍できることは間違いないでしょう。
(5) まとめ
「くずし字データセット」とその利用例について紹介しました。データセットの公開によってこれから古文書の解析技術が加速度的に発達していくでしょう。例えば源氏物語のような絵巻物を渡せば、文章が書いてある部分を認識しデータ化してくれるようなAIはまもなく登場すると思われます。
開発されたAIは国の機関が管理する古文書の解析などに投入されていくことは恐らく間違いないですが、民間で管理されている古文書の解析には民間のAI企業があたっていくのかなと個人的に想像しています。
しかし考えなければならないのは、AI技術の開発によって歴史的価値のあるものの研究が進むことは嬉しいことですが、もともと古文書を読むことを生業としていた専門家にとっては危機的な状況が迫っているかもしれないということです。今回紹介したようなAIが結局何ができて何ができないのか、AIを過大評価することなくしっかりと見極める必要がありそうです。
ライター:東京大学 学生



この記事に関するカテゴリー






