BERTのAttentionは何を見ているのか?
3つの要点
✔️BERTのAttention機構の分析手法の提案
✔️Attentin機構は全体的には区切り文字や[CLS]、[SEP]を見ている
✔️特定のAttention機構では「動詞とその目的語」、「名詞と修飾語」、「前置詞とその目的語」などの簡単な文法関係から、照応関係などの複雑な文法関係も獲得している
前書き
現在の自然言語処理ではTransformer以降、Attention機構を用いたモデルが流行となっています。その中でも最近はBERTなどの巨大な事前学習済みのモデルが大きな成功を収めています。
それらモデルが何を学習しているのかを分析する取り組みは行われてきましたが、モデルの出力自体や隠れ層でのベクトル表現に焦点を当てた分析手法が中心でした。
この論文では、Attention機構が何を見ているのかに焦点を当てたモデルの分析手法が提案されており、BERTのAttention機構が何を見ているのか、そしてその他Attention機構を持つモデルをどのように分析すればよいかが記載されています。
BERTにおけるAttention
まずはBERTに導入されているAttention機構がどういったものかを解説していきます。
BERTではAttention Is All You Needで提案されたTransformerというモデルで提案されたAttention機構がそのまま使用されています。
Self Attention
![]()
Self Attentionは上記の式で表されるAttention機構で、式中のQuery, Key, Valueの全てに同じ値を用いることから”Self” Attentionと呼ばれています。
この式を定性的に考えると、[seq_len, embed_dim]の行列で積を計算することで系列全体の文脈を考慮し、sotfmaxによって全体の和が1になるよう重み付けがされ、その重みによって元の入力であるValueから値が文脈を考慮した形で取り出されるという計算になります。
Scaled Dot-Product Attention
![]()
Scaled Dot-Product AttentionはSelf Attentionで生じうる勾配消失問題を解消するべくスケーリングを導入したものです。
Multi-Head Attention
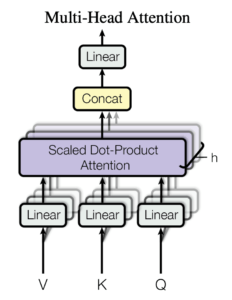
Multi-Head Attentionが実際にTransformerやBERTで用いられているAttention機構で、上記のような図で表現できます。
Scaled Dot-Product Attentionを複数並列に計算し、より多様な表現を学習するべく導入された機構です。
分析結果一覧
本論文では大まかには以下の実験を行なっています。
- BERTのAttentionが主に何を見ているかを確認する表面的なパターンの分析
- Attentionにはそれぞれ異なる役割があることがわかったため、より詳細にどのような役割を果たしてるのかを知るためのAttention Headsそれぞれの個別の分析
- Attention Headsが異なる役割を果たしていることを示すためにAttention Headsを組み合わせて作成した簡単な識別器がどのように作用するかの分析
- 同じ層のAttention Headsの類似した性質を示すためのクラスタリング分析
以下では上記のそれぞれの分析を論文の章立てを利用し、
- Attentionの表面パターン分析(Surface-Level Patterns in Attention)
- Attention Heads個々の分析(Probing Indivisual Attention Heads)
- Attention Headsの組み合わせ分析(Probing Attention Head Combinations)
- Attention Headsのクラスタリング分析(Clustering Attention Heads)
として順にまとめていきます。
Attentionの表面パターン分析(Surface-Level Patterns in Attention)
Relative Position
この分析ではBERTのAttention Headsが直前・現在・直後のうちのどのtokenに着目しているかを調べています。
その結果、以下のことが分かりました。
- 現在のtokenはほとんど見ていない(図1全体的に)
- 特に浅い層では前後のtokenへ着目しているAttention Headsが存在する(図1のHead1-1、Head3-1など)
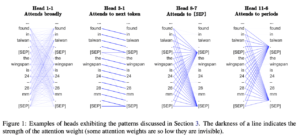
図1 Attentionの定性評価図
Attendig to Separator Tokens
ここでは区切り文字(Separator Tokens)に対する分析を行っています。
図2のとおり、[SEP]に対するAttentionの値はかなり大きくなっています。
また気になる点として、以下の2点が挙げられます。
・[SEP]と同様にかならず文中に含まれ、かつ学習中にmaskされることのない[CLS]とは明らかに異なる着目のされ方をしている。
・またカンマやピリオドのような文章中に頻出するtokenとも異なる着目のされ方をしている[SEP]は文の区切りを表すので文章の区切り毎に情報を集約するために[SEP]に大きな注意が与えられているからという説が考えられますが、その場合は[SEP]からのAttentionが文全体に対してかかっていて欲しいのですが、図2から現在のtokenが[SEP]の時に他のtokenよりも[SEP]自身に対するAttentionの値の方が大きいことから先ほどの説はあまり有力ではありません。
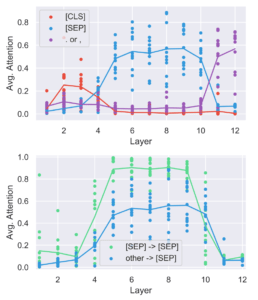
図2 層ごとのAttentionの平均値
さらに理由を追及するべく勾配ベースの特徴量重要度を計算(Axiomatic Attribution for Deep Networks)したところ、図3のような結果が得られました。
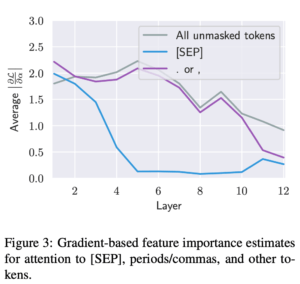
図3 各層の特徴量重要度
図3から[SEP]トークンへのAttentionはほとんど出力に影響せず、そのAttentionで特に情報が得られなかった場合にとりあえず[SEP]に注意しているだけであることが分かりました。その一方でカンマ、ピリオド、その他maskされていないtokenは特徴量重要度で大きな値を示し、モデルの出力に影響します。
Focused vs Broad Attention
ここではAttentionが「いくつかの単語だけに強く注意している」、「多くの単語にわたって広く注意している」のどちらであるのかを検証します。
Attentionの分布の平均のエントロピーを計算したところ、図4のような結果となり浅い層ではより広い範囲に着目していることが分かりました。そのようなエントロピーの大きなAttention Headsの出力は、文章のbag-of-vectors表現のようなものであると考えられます。
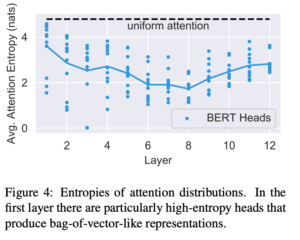
図4 各層のAttentionの情報量
またすべてのAttenstion Headsで[CLS]だけからのエントロピーを計算したところ、ほとんどの層では図中と同様な値をとっていたのですが、最終層のエントロピーだけは3.89と非常に大きな値を示しました。
これはかなり広い範囲に対するAttentionであると考えられ、事前学習での「次の文章予測(next sentence prediction)タスク」を解く際にこの[CLS]の表現を用いていることから、全文のより良い分散表現を得られているのだと考えられます。
Attention Heads個々の分析(Probing Indivisual Attention Heads)
Dependency Syntax
係り受け解析(dependency parsing)によって個々のAttenstion Headsを調べた章です。
係り受け解析は単語と単語のつながりがどういった関係であるかを解析するタスクで、この場合は各単語がどの品詞にあたるのかに着目して分析しています。
表1からすべての依存関係に対してうまく機能するようなAttention Headはないことと、特定のAttention Headはある依存関係を捕らえられていることが示されています。
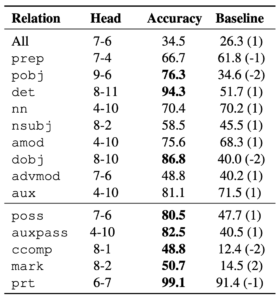
表1 Attention Headsによる依存関係解析のスコア
Coreference Resolution
先ほどの係り受け解析によってAttentionが簡単な文法規則を学習できている事が分かったため、さらに複雑な文法規則が学習できているかを把握するために照応解析(Coreference Resolution)を行なっています。照応解析とは同一のものを指す2つ以上の名詞の関係を探し出すタスクで、例えば「BERT最高。これさえあれば何もいらない。」という文章における「BERT」と「これ」のような関係を見つけるタスクです。
比較手法は以下の3つです。
-
- 最も近いものを選ぶ手法
- 同じ見出し語を持つ最も近いものを選ぶ手法
-
- ルールベースの手法(Stanford’s Multi-Pass Sieve Coreference Resolution System at the
CoNLL-2011 Shared Task) - 結果は表2の通りで、Attention Headだけで文字列マッチングの精度を大きく上回り、ルールベースの手法に近い精度を達成しています。またマッチングでは表現できないような曖昧な表現も獲得できています。これによりBERTは単純な構文関係だけでなく、より複雑な文法表現も獲得できていると考えられます。
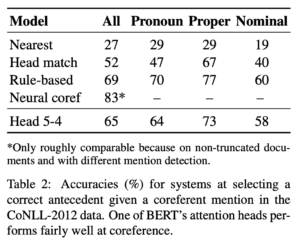
表2 照応解析のスコア
- ルールベースの手法(Stanford’s Multi-Pass Sieve Coreference Resolution System at the
Attention Headsの組み合わせ分析(Probing Attention Head Combinations)
各Attention Headsが異なる文法の解釈を行なっているのであれば、BERTはそれらを組み合わせて文法の知識を獲得していると考えられます。そのためこの実験では各Attention Headsの出力のみを用いて識別器を構築し、それだけでどの程度のスコアを出せるのかを係り受け解析によって示しています。
結果は表3にある通りで、Structual probeと大差がないことから、BERT自体のベクトル表現にはAttention以上の文法的な意味合いはほとんどないと言っても差し支えないと考えられます。
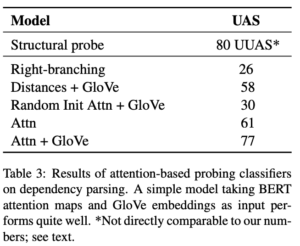
表3 Attentionを用いた構文解析結果
Attention Headsのクラスタリング分析(Clustering Attention Heads)
同じ層にあるAttention Headsの性質が似ているか否かを調べるために各Attention Headsの出力の分布間のJensen-Shannon Divergeneceでクラスタリングしています。
図6の上の画像が性質による色分けで、下の画像が層ごとに色分けした結果です。
どちらの場合も比較的きれいなクラスターを作っており、同じ層のAttention Headsの性質は類似していることがわかります。
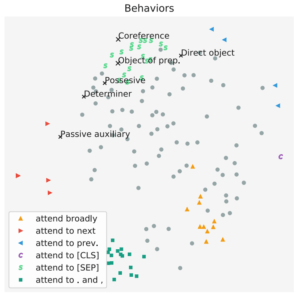
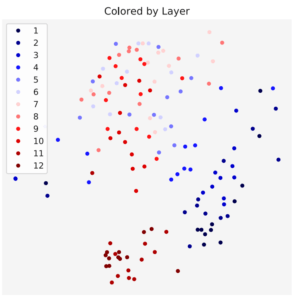
図6 振る舞いごと、層ごとのAttentionのクラスタリング結果
まとめ
ここまでBERTなどのAttention機構を持つモデルの解釈分析手法とその結果の解説を行ってきました。
その結果、
-
-
- Attentin機構は全体的には区切り文字や[CLS]、[SEP]を見ている
- 浅い層のAttentionは大きなエントロピーを持ち、それがbag-of-vectorsのような表現を示している
- 特定のAttention機構では「動詞とその目的語」、「名詞と修飾語」、「前置詞とその目的語」などの簡単な文法関係から、照応解析などの複雑な文法関係も獲得している
- BERTの文法的な知識はほとんどAttention Headsが担っている
- 各層のAttention Headsは似たような性質を持つ
-
といったことがわかりました。
こういった体形だったBERTの分析が行われることで、従来では深掘りされてこなかった部分でのさらなる効率的なモデルの開発などに繋がることが考えられます。
またこの論文はかなり体系的にBERTのAttention機構の解釈に力を入れていて、非常に読み応えがありました。
少し読むのに苦労するかもしれませんが、それだけ力の入った良い論文だと思うので、本記事で事前知識を入れてからでも目を通してみてはいかがでしょうか。
What Does BERT Look At? An Analysis of BERT’s Attention
written by Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D. Manning
(Submitted on 11 Jun 2019)Accepted to BlackBoxNLP 2019
Subjects:Computation and Language (cs.CL)






この記事に関するカテゴリー






