ベストからブラジャーに。高解像度でリアルなファッション画像操作が可能なFE-GANが登場
【論文】Fashion Editing with Multi-scale Attention Normalization
この論文では、単純なスケッチや少ないカラーストロークから画像を合成したりなど、柔軟なユーザインタラクションを可能にするファッション画像操作ネットワークFE-GANを提案しています。
ファッションデザイナーがさまざまなスタイルの服のデザインを簡単に編集したり、映画制作者が、俳優や女優の表情、髪型、体型を制御してキャラクターをデザインしたり、さまざまなアプリケーションにおいて大きな潜在的価値を持っています。
例えば、下着の輪郭を描くだけで、ピンクのスポーツベストから下着へ簡単に変更できます。
こちらは、長いブロンドの髪をした長髪の女の子です。帽子の形がラフに描かれていますが、次の瞬間実際のリアルな帽子に変換されました。人工的な跡は全くありません。

これまでにもInstaGANなどのモデルがあり、写真の中のパンツからスカートに変換するなどの操作が可能でしたが、FE-GANには様々な付加機能がついてます。
例えばワンストロークで色の指定をすることができます。
また、衣服の形を変えることに加えて、衣服の色や柄を変えることもできます。

FE-GAN
以前の方法とは異なり、1段階で完全な画像を直接生成することはしません。代わりに、まず不明瞭な画像から構造解析マップを生成し、次に生成された解析マップから、レイアウト上に詳細なテクスチャをレンダリングします。
(1)フリー形式解析ネットワーク
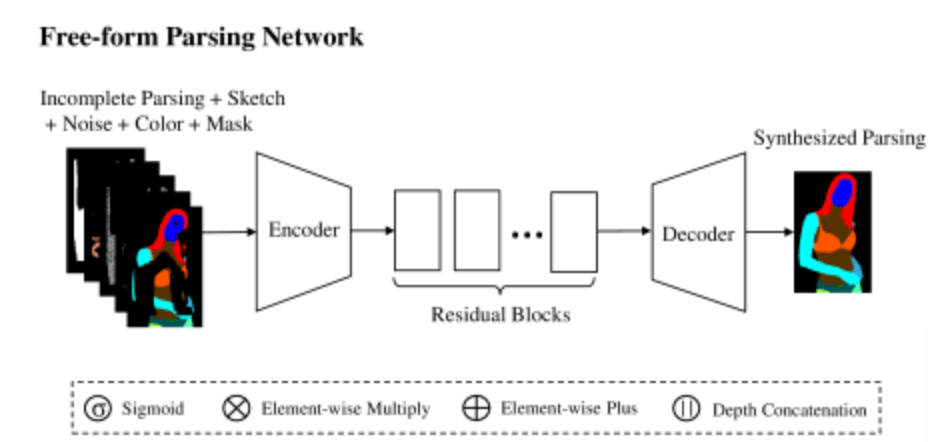
最初に、カラー・ブロックなどで遮られた不明瞭な画像を与えたときに完全な構造解析(マップを合成できるフリー解析ネットワークを提案しています。
MAP(Mean Average Precision)とは、画像認識モデルにある画像の識別を行わせた時に、
(i)物体(例えば犬)を対象物体として認識する事
(ii)背景画像(例えば白背景)を物体として認識しないこと の2つの最大化を目的とする指標の一つです。
今回の場合における構造解析マップとは、例えば、下着の絵をのせた場合、もともとの入力(人)の構造を解析し、ストロークや色あいなどから、載せられた絵が”下着”であることをモデルに理解させるように最適化を行うマップです。
エッジ検出を用いて画像から得られた不明瞭な構造解析マップ、任意のスケッチ、カラーストローク、ノイズなどが与えられると、フリー形式解析ネットワークは、スケッチとカラーによって導かれた完全な構文解析マップを再構築することを学習します。
(2)、構造解析型画像修理ネットワーク
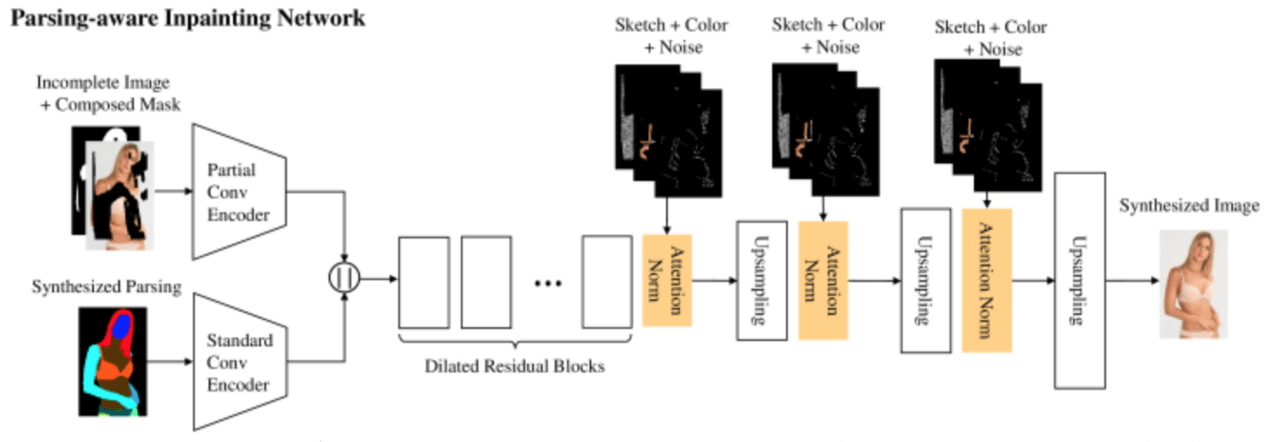
入力として、1で生成された構造解析マップと、不完全な画像(部分的に不鮮明な画像)を与えます。
1で統合された構造解析マップに対しては、標準的な畳み込みエンコーダーを用いて意味理解のある特徴量を抽出します 。
不完全な画像に対しては、画像の必要部分にのみ対する畳み込みエンコーダーを用いて、参考になる部分だけを取り出して、特徴量を抽出することを可能にします。この時、合成マスク(composed mask)を用いて画像内の対象物体のみから特徴量を抽出します。
デーコーダーには、スケッチと色で条件付けられたより重要な特徴を抽出するためのAttetionマップを学ぶことができる正規化Attention層を挿入します。
パフォーマンス
提案した方法を評価するために,画像ペインティングタスクにおける比較実験を行っています。公平な比較を行うために、マスク、スケッチ、カラー領域、ノイズなどから構成された不明瞭な画像を入力として使います。
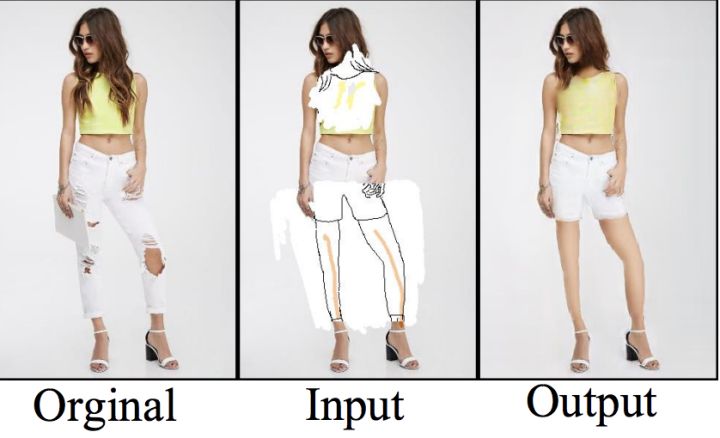
以下の画像は、ベースラインの方法と比較したものです。左オリジナル、左から2番目が入力画像、右端が、FE-GANの結果です。
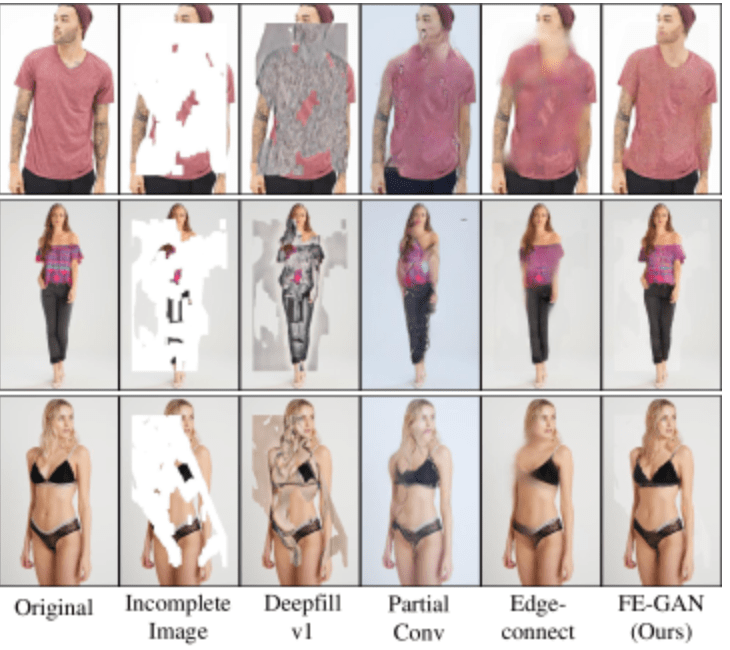
以下は3つのデータセット(上からDeepFashion、MPV、FashionE )に対する画像変換タスクを視覚的に比較したものです。左から2番目が任意のスケッチです。ベースラインと比較して、FE-GAN(右から2番目)が一番綺麗に合成できていることがわかります。




この記事に関するカテゴリー






