GANの三つ巴バージョン!? データ増強をするためのGANモデルGAMO
今回紹介する論文はこちら。
論文名: Generative Adversarial Minority Oversampling
Subjects: Computer Vision and Pattern Recognition
Submit: 22 Mar 2019 (v1), last revised 3 Apr 2019 (this version, v2)
Written by: Sankha Subhra Mullick, Shounak Datta, Swagatam Das
この論文は、「GANで画像が生成できるなら、データ数の少ない問題に対処できるんじゃないか?」という考えから提案されたものです。
不均衡データ
実世界にAIを応用する際、必ずと言っていいほど不均衡データという問題に直面します。不均衡データ問題とは、「クラス間においてデータ数が偏りがある状態」のことです。例えば、医療AIの世界では健康な人間のレントゲン画像は1万枚あるが、ある病気にかかっている人間のレントゲン画像は100枚しかない。なんてことが頻繁に起こります。その際、ある病気にかかっているかどうかをAIに判断させることは非常に難しくなります。理由は簡単。AIは健康な人間のデータを大量に学習しているので、新しいデータに対して「健康である」と判断しがちになってしまいます。
データ増強
不均衡データに対処する方法は大きく分けて3つ存在します。
1. over-sampling(データ増強): 少ないデータを増やす
2. under-sampling: 多いデータを減らす
3. cost-sensitive learning: 少ないデータに対する勾配が大きくなるような損失関数を設計する
この中でも、今回紹介する論文は1.のover-sampling(以下、データ増強)に関する論文となっています。
普通のデータ増強では、1枚のデータを少し傾けたり、1枚のデータにノイズを加えることで、複数枚のデータであると見なし、数の少ないデータを増やします。
今回紹介する論文では、GANのアイディアを用いてデータ増強を行います。
提案手法
早速、提案されたモデルを見ていきましょう。
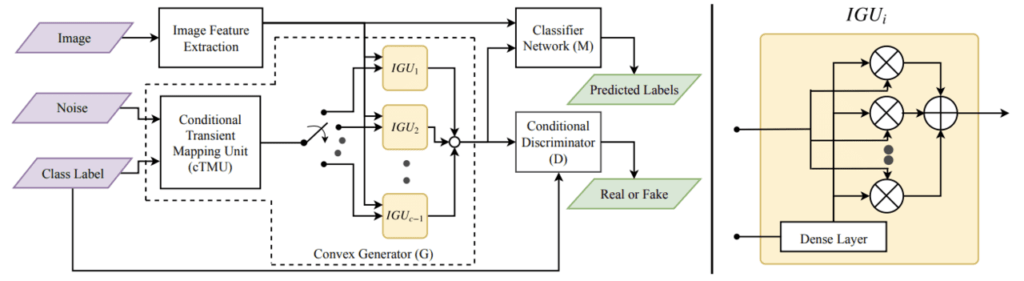
上図が提案モデルのGAMO(Generative Adversarial Minority Oversampling)です。このモデルは通常のGANとは異なり、画像の特徴量を生成するG, 画像の特徴量を分類するM, 画像の特徴量がリアル画像なのかGによるフェイク画像なのかを予測するDの3つのモデルから構成されます。
(特徴量とは、画像などのデータをCNNなどで圧縮した低次元ベクトルのことを言います。)
この図を見てもわかりくいかと思いますので、簡略化したモデル図を作成しました。この図を用いてモデルの概略を説明します。詳しい理論が知りたい方は後述しますので、そちらもご覧ください。
続きを読むには
(3377文字画像5枚)AI-SCHOLARに
登録いただく必要があります。



この記事に関するカテゴリー






