Google、マネキンチャレンジを訓練データとして用いた深度マップ作成を提案
googleAIが、ビデオ(人とカメラが同時に動いてる)から奥行きを予測するため、トレーニングデータセットとしてyou Tubeに上がっている「マネキンチャレンジ」ビデオを使用するという新しい取り組みを行っています。この技術を応用することで、ムービーから人や物を消したり、実際には存在しないオブジェクトを合成したりなどが可能になります。
論文:Learning the Depths of Moving People by Watching Frozen People
人間の視覚システムは、2Dで投影されたものから現実の3D世界を理解する優れた推理能力を持っています。複数の動いている物体動いている複雑な環境でさえ、物体の幾何学と深度の順序付けを自然に行い現実的な解釈をすることができます。
一方、コンピュータビジョンの分野では、2次元画像データから位置情報を計算する事によって、幾何学な3Dシーンを再構成する方法を研究してきましたが、ロバストな再構成は依然として困難なままです。

特に難しいのは、このようなカメラとシーン内のオブジェクトの両方が自由に移動している場合です。これは、同じ物体を2つの異なる視点から同時に観察できる(と仮定した)三角測量の原理に基づいた従来の3D再構成アルゴリズムを混乱させてしまいます。
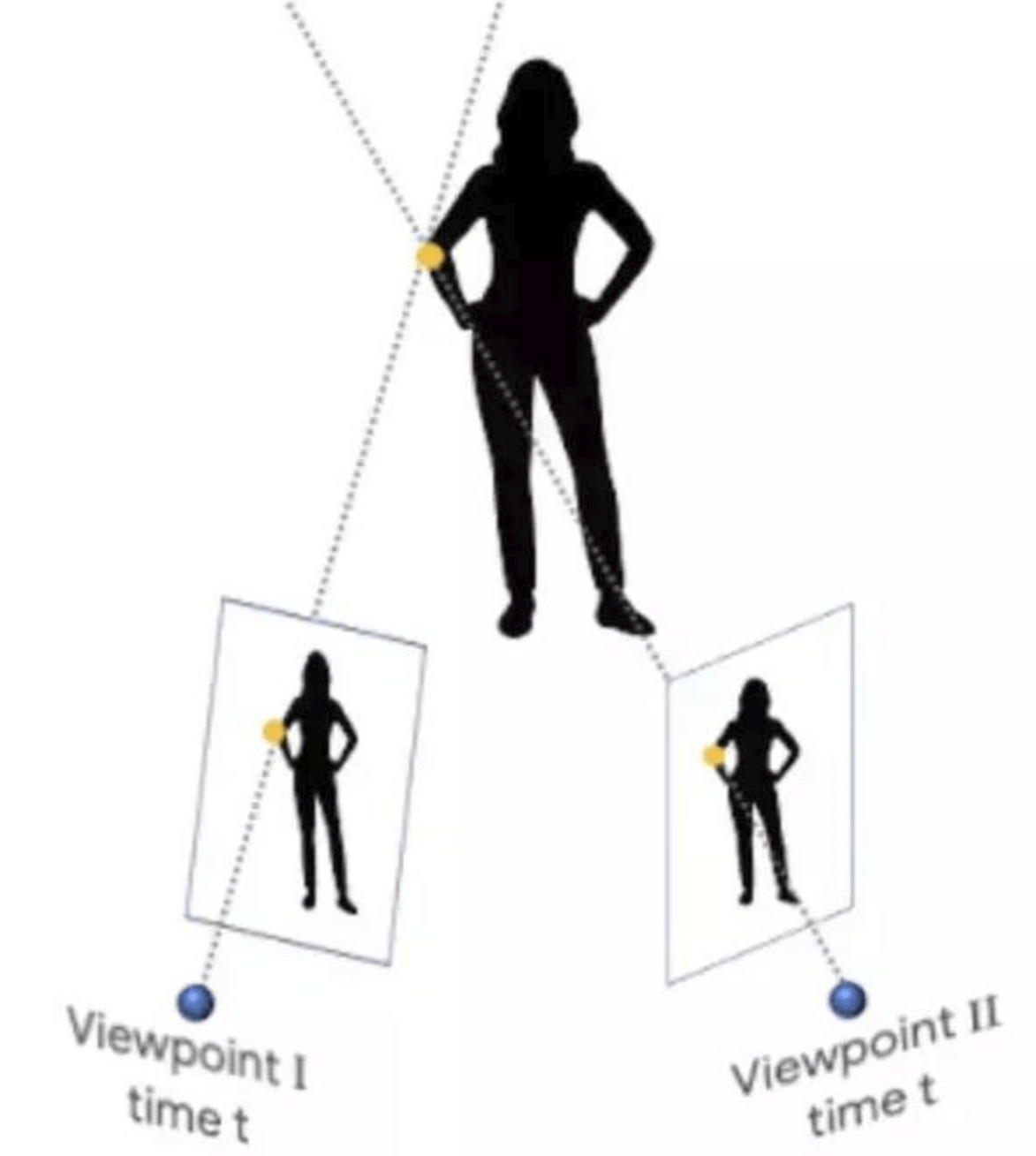
従来の方法では、2つの視点が同時にシーンを捉えることを前提としています。
この仮定を満たすには、マルチカメラ(複数の視点から同じ物体を撮影したもの)のようなものか、カメラ(単一)が移動していても物体が静止したままのシーンが必要です。
googleAIによって発表された論文では、カメラと対象の両方が自由に動くビデオから深度マップを生成できる方法を提案しています。カメラの動きと複雑な人間の動きが同時に発生する困難なケースにおいても深度マップを予測することが可能になります。
新しい点としては、カメラが自然な姿勢で人が「止まっている人」の周りを移動する多数のインターネットビデオからの新しいデータ源です。
トレーニングデータの入手

Googleが注目したのが、2016年頃に爆発的に流行したマネキンチャレンジのムービーです。マネキンチャレンジは、ある場所にいる人全員が一斉にマネキンのように制止する様子をムービーに収めたもので、2019年現在でもYouTubeで見ることができます。Googleはこのマネキンチャレンジの「人間は止まっているのに、カメラは動いている」というムービーを利用し、約2000本をもとにトレーニングを行いました。
人物を含むシーン全体が静止しているのでMulti-View Stereo(MVS)のような三角測定ベースの方法を用いて深度マップを推定でき、この導出した深度マップデータを訓練として使用します。
深度予測に機械学習を使用することが最近急増していますが、このような、カメラと人間の同時動作の場合に学習に基づくアプローチを調整したのは初めての取り組みです。
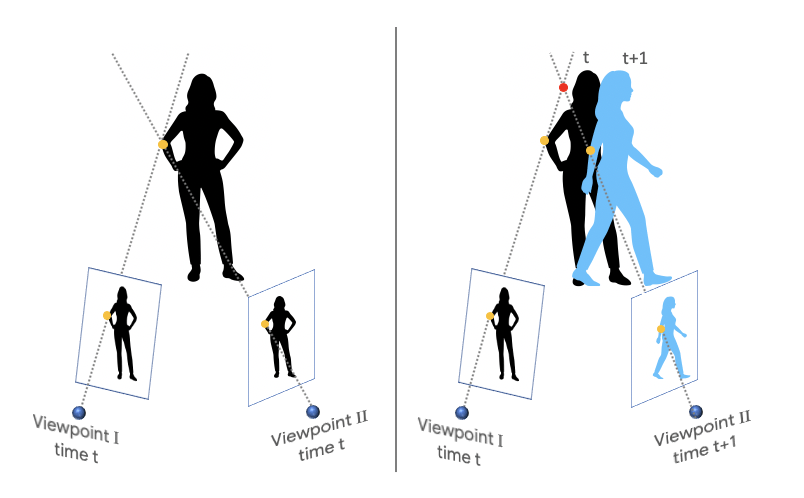
動いている人の奥行情報を推測するには?
マネキンチャレンジを用いた学習によって「人間が静止していてカメラが動いている映像」の訓練を行ったわけですが、ここにおける目標は「人間もカメラも動いている」ムービーを3D映像としてとらえることです。このギャップを埋めるためには、ネットワークに与える入力情報を複数組み合わせて構造化する必要があります。
考えられる手法としては、ビデオの各フレームに対して別々に深度を推測することです。
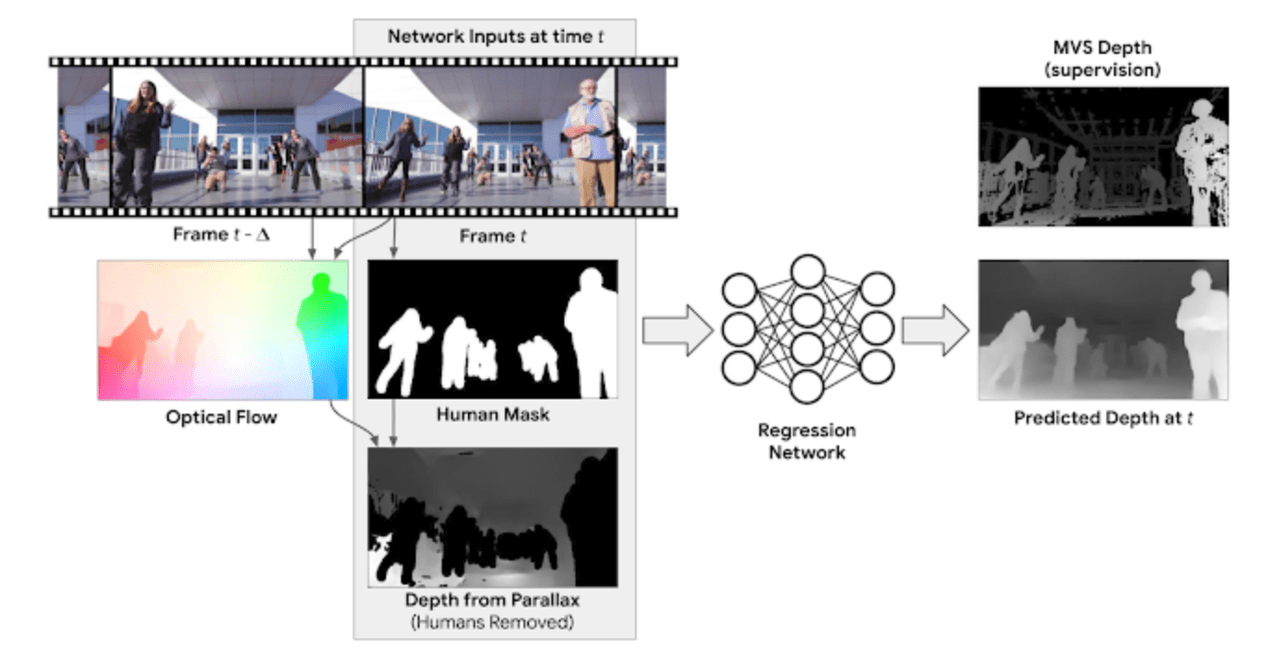
例えば、運動視差、すなわち静止物体の2つの異なる視点の間で、動きを算出するのは奥行きの強い手がかりになります。ここでは、フレームと別のフレームを比較して、オブジェクトの動きを2次元的なベクトルで表す”オプティカルフロー”を算出し、ピクセル単位で変化をとらえるという手法を採用します。
しかしこの方法は、静止した人間にのみ有効です。さらに移動する人間を処理するために、動いてる人間の領域をマスクするセグメンテーションネットワーク(Mask R-CNN)を適用します。
つまり、深度予測ネットワークモデルへの入力は、「RGB画像」、「人間をセグメンテーションするためのマスク」、「オプティカルフローから計算された人間以外の領域の深度マップ」 の3つになります。
様々な実験
実験では、複雑な人間動作(歩行、走行、ダンスなど)を描写するビデオで行い、高い精度で深度を予測できることを実証しています。
以下は、今回の提案と最先端の方法と比較した結果です。
上:学習ベースの単眼カメラを用いた奥行き予測(左:DORN、右:Chen et al)下段:学習ベースのステレオカメラを用いた予測(左:DeMoN、右:本モデル)

このモデルを用いて予測された深度マップは、隠れたり欠けている領域を、他のフレームの映像を使って補完する機能持ち合わせているため、深度マップを利用することで、ムービーにさまざまなエフェクトを加えることができます。
例えば 以下のアニメーションは「合成ぼかし」を適用したものです。最初は画面の手前から奥に向かって歩いている赤色のパーカーの男性にピントが合っていて、それ以外の風景はぼけていますが、すれ違う老夫婦にピントをあわせて、中央の男性をぼかすことなどもできます。

ムービーから人を消し去ったりすることも可能です。以下のアニメーションでは、ムービーの別の場面から得た「人の背景の映像」で塗りつぶすことで実現しています。




この記事に関するカテゴリー






