ついに誕生!期待の新しい活性化関数「Mish」解説
3つの要点
✔️ ReLU、Swishに次ぐ新たな活性化関数Mishを提案
✔️ MNISTやCIFAR-10/100などでReLUとSwishを圧倒
✔️ 論文筆者実装のGitHubレポは早速600以上のスターを持ち、非常に簡単に使える
Mish: A Self Regularized Non-Monotonic Neural Activation Function
written by Diganta Misra
(Submitted on 23 Aug 2019 (v1), last revised 2 Oct 2019 (this version, v2))
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Neural and Evolutionary Computing (cs.NE); Machine Learning (stat.ML)
本記事で使用している画像は全て論文中から引用しております。
導入
ニューラルネットワークは画像認識や自然言語処理など広く使われ、おもしろいことにも活用ができます。そんなニューラルネットワークは、非線形関数を表現できることにその強さがありますが、非線形関数を実現しているものこそが、活性化関数です。代表的な活性化関数にSigmoidやReLU (2011)などがありますが、ReLUの後継として2017年にSwishが登場しました。ただご存知のようにReLUが未だデファクトスタンダードとして君臨しています。そんな活性化関数界の流れに終止符を打つべく2019年に登場したのが今回紹介するMishです。Mishは様々なタスクでReLUとSwishを超えています。GitHub上で実装が公開されているので、簡単に試すことができます。
本記事では以下の流れで論文を解説していきます。
- Mish解説
- Mishの実験結果
- 結論
1. Mish
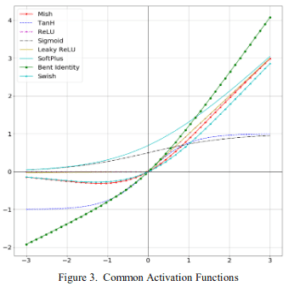
Mish関数を式で表すと$f(x)=x\cdot \mathrm{tanh}(\mathrm{softplus}(x))$
であり、ここで$\mathrm{softplus}(x)=\ln{(1+e^x)}$ です。図で表せば以下です。
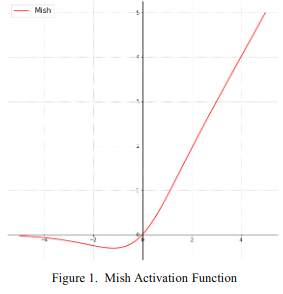
使うときはReLUなどを使っているところに代わりにMish関数を入れるだけです。簡単です。ただ、ReLUよりも少しだけ小さい学習率を使うのが良いそうです。論文中で挙げられているMish関数の特性は以下の5つがあります。
- 上限なし
- Sigmoidなどは1で飽和してしまい、その時の傾きはゼロとなってしまうため学習が遅くなるが、Mishは飽和しないため学習速度の低下を避けられる
- 下限あり
- 強い正則化をかけることができる
- 負の値を持つ
- ReLUと違い、負の値も残る
- ∞階微分まで関数が連続
- ReLUは微分したら連続ではなくなるため勾配を用いるOptimizerでは予想外の問題を引き起こしかねないが、Mishは∞階微分まで連続であるため大丈夫
- Mishによるアウトプットランドスケープが滑らか
- 損失関数も滑らかになり、最適化しやすくなる。
2. Mishの実験結果
2.1 MNIST
たくさん実験しているのでザッと説明していきます。基本的にSwish(およびReLU)との性能比較をしています。ネットワークは6層の通常のCNNを使っていると書いてあります。
2.1.1 層の深さ
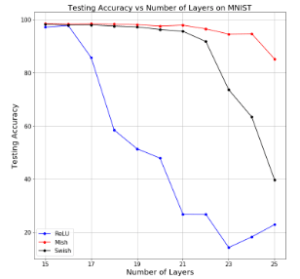
モデルの層を(skip connectionを用いずに)深くしたときの精度です。モデルの層が深くなってもMish(赤)が安定していることがわかります。
2.1.2 ロバスト性
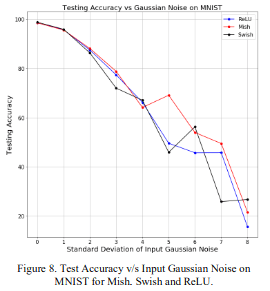
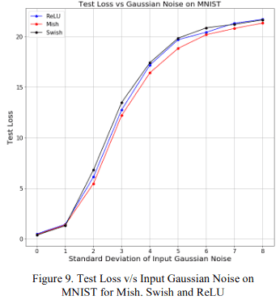
上図が精度で下図が損失です。横軸は入力に追加するGaussianノイズの標準偏差で、大きくなればなるほどノイズが大きな値を取りうることを示しています。ノイズが大きくなってもMishは高い精度および低い損失を示していますね。
2.1.3 様々な最適化アルゴリズム
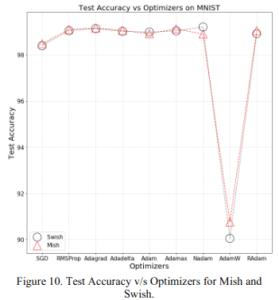
SGDやAdamなど様々な最適化アルゴリズムを使ったときの精度です。Nadamを使用した場合は劣っていますが、それ以外はあらゆる最適化アルゴリズムにおいてMishはSwishとほぼ同程度またはより良い性能を示していますね。
2.1.4 学習率依存性
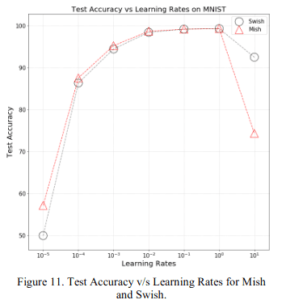
様々な学習率を用いたときの精度です。学習率が $[10^{-5}, 10^{-1}]$ においてはMishはSwishと同じかより良い精度を示しています。特に学習率が小さいときにはMishのほうがSwishよりも良いです。
2.1.5 様々な初期値
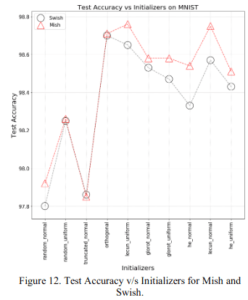
ランダム初期値やHe初期値など様々な初期値を用いた場合の精度です。こちらもMishがSwishと同程度かより良い精度を叩き出しています。
2.1.6 様々な正則化
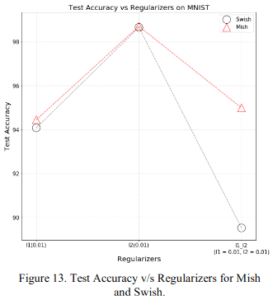
L1正則化、L2正則化およびL1-L2正則化を用いた場合の精度です。ここでもこれまでと同じようにMishがSwishと同程度かより良い性能を示しています。
2.1.7 ドロップアウト率依存性
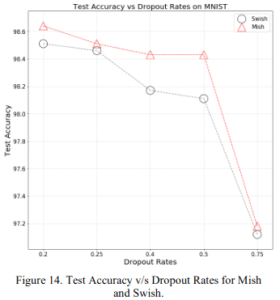
ドロップアウト率に対する精度の違いを示しています。いずれにおいてもMishのほうがSwishよりも良いことがわかりますね。
2.1.8 層の幅
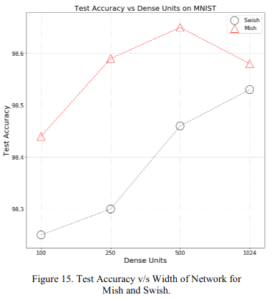
一層あたりのニューロンの数、つまり層の幅に対する精度を示しています。MishのほうがSwishよりも断然良いですね。
2.2 CIFAR-10
ここからはデータセットとしてCIFAR-10を使用しています。ネットワークはMNISTと同様普通の6層CNNを使用しています。
2.2.1 様々な最適化アルゴリズム
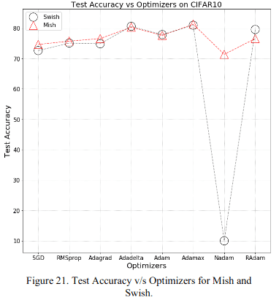
色々な最適化アルゴリズムを使った場合の結果です。相変わらずNadamはそもそもの性能がよくありませんが、MishがSwishと同程度またはより良いことがわかります。
2.2.2 学習率依存性
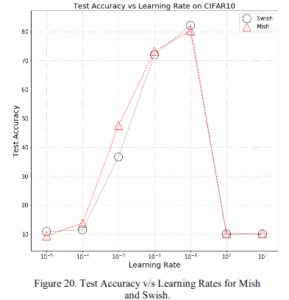
学習率においてもMishがSwishと比べ同程度またはより良い性能を示しています。
2.2.3 様々な初期値
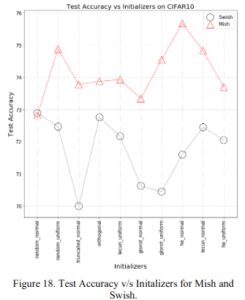
random_normalを除き、どの初期値でもMishがSwishよりも大幅にいいことがわかりますね。
2.2.4 様々な正則化
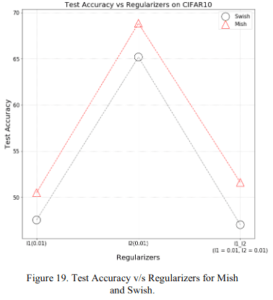
正則化においてもきれいにMishがSwishを圧倒しています。
2.2.5 ドロップアウト率依存性
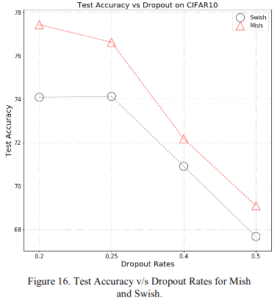
どのドロップアウト率でもMishのほうがいいですね。
2.2.6 層の幅
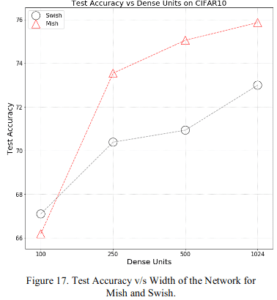
より表現力が出る層の幅が大きいときには、MishがSwishを圧倒しています
2.2.7 CosアニーリングとOne Cycleポリシー
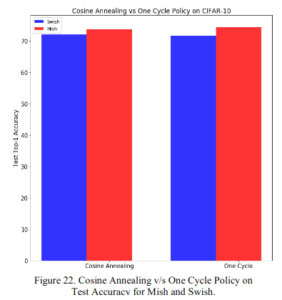
学習率のスケジューラであるコサインアニーリングとOne Cycleポリシーのいずれを用いてもMishのほうがSwishよりも高い精度を出していますね。
2.2.8 Mixup
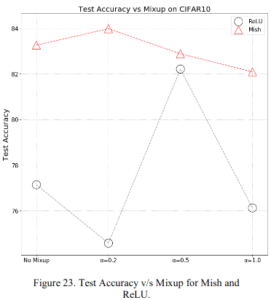
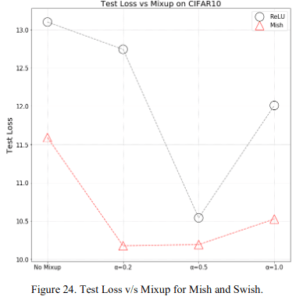
ここではdata augmentation手法の1つであるMixUp(2017)(解説)のハイパーパラメータ $\alpha$ に対する精度です。上図が精度で下図が損失です。ここではなぜかReLUと比べていますが、いずれにおいてもReLUに勝っています。
2.3 その他の実験
上述した実験たち以外にもいくつか実験を行っており、それらを紹介します。
2.3.1 さまざまな活性化関数
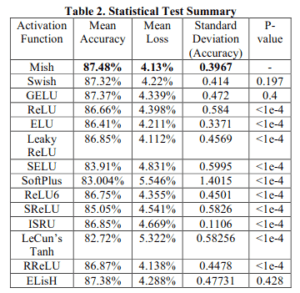
ネットワークにはSENet使用しています。Mishが一番高い精度、低い損失および低い(精度の)分散を示しています。
2.3.2 さまざまなネットワーク
様々なネットワークに対してMishの精度を見ていきます。テーブルで一気に紹介します。
2.3.2.1 CIFAR-10
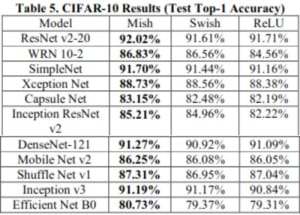
ResNet v2-20からEfficientNet B0, MobileNet v2まで幅広いモデルで高い精度を示しています。すごい!
2.3.2.2 CIFAR-100
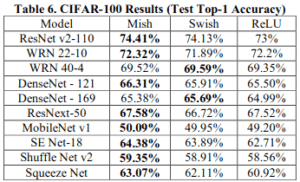
CIFAR-100においてはSwishに2つだけ負けていますが、それ以外は全てMishが勝っています。こちらもすごいです!
2.3.3 学習速度
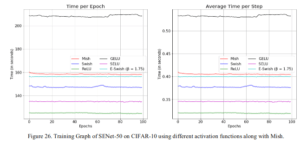
ここではMishの唯一の欠点とも言える、学習速度についてです。仕組みが単純なReLUと比べると速度では劣ってしまっていることがわかります。ただ、これまで見てきたMishによる精度向上を踏まえて使用するかどうかを判断してはいかがでしょうか。
3. 結論
ReLUとSwishを超える性能を示したMish。論文中ではさらにImageNetやNLPにも発展させることを次の展望として示しています。活性化関数をただMishに変えるだけなので、非常に簡単に使えます。モデルの精度をあげたいと思っている方は論文筆者による実装を使ってみてはいかがでしょうか!




この記事に関するカテゴリー






