AIの学習をより人間らしくする?学習経験を活かした効率的な学習手法MTLの登場!
3つの要点
✔️これまでの学習経験を元に、未知のタスクを少ないデータから解く手法の提案
✔️一部のパラメータのみを更新することで、効率良く、そしてこれまでの学習を忘れないように学習可能
✔️難しいタスクを重点的に学習することで、未知のタスクを少ないデータで精度良く学習可能
はじめに
近年、深層学習が世間にも浸透し、様々な場面で深層学習が使用されるようになってきました。深層学習を用いた有名なものとしては、自動運転に使用される画像認識技術や、アレクサやSiriに使用される自然言語処理技術などが挙げられます。
深層学習を代表とする人工知能研究の大きな目標は人間と同じような知性を作ることです。人間は一度物体を見るだけで、その物体を高精度に認識することが可能です。しかし、深層学習技術では、大量のデータで学習しなければ、物体を認識することが出来ません。
では、人間はどのように少ないデータから高精度に物体を認識しているのでしょうか。これは、これまでの学習経験を活かしていると考えられます。例えば、私たちはこれまで大量の物体を見て学習をしています。これによって、物体Aと物体Bを見分ける時に、どこを見れば良いか経験的に学んでいます。
つまり人間は、学習するプロセスを学んでいるということです。これはメタ学習という分野で盛んに研究がされています。このメタ学習を用いれば少ないデータでの学習(Few-Shot learning)が可能となります。
従来手法では、大量のデータで学習させ、その後、少量のデータで再学習してより良い初期値を得ていました。これにより、未知のタスクにも少ないデータで対応できるようにしていました。
提案手法では、一度学習させたパラメータは再学習させず、別の少量のパラメータを用意して、そのパラメータを学習させます。そうすることで、一度学習したことを忘れずに、効率的に学習を行うことが出来ます。この手法をMeta Transfer Learning(MTL)と呼びます。
さらに、難しいタスクを重点的に学習させることで、どうすれば難しいタスクを少ないデータで学習できるのか、その術を学ぶことが出来ます。この手法をhard task (HT) meta batchと呼びます。
MTLとHTを組み合わせた手法により、画像分類における未知のタスクを、少ないデータで高精度に学習することが可能となりました。
メタ学習とFew-Shot learning
上記で述べたように、Few-Shot learningとは少量のデータで学習を行うことです。k枚の画像で学習することをk-shotと呼び、良く1-shotや5-shotが評価に使用されます。
Few-Shot learningでは主にデータ拡張のアプローチとメタ学習のアプローチをとっています。近年、メタ学習によるFew-Shot learningへの研究が盛んとなりつつあります。
メタ学習は定式化すると以下のステップで行われます。
① 学習データをmeta training用とmeta test用に分割する。
② meta training用のデータで元となる分類器であるbase learnerの学習を行う。例えば100クラスの画像分類のタスクで、各クラスに500枚データが含まれているようなデータでの学習を行う。
③ meta traning用のデータからタスクTを抽出する。例えば、5クラスの画像分類を行うタスクなど。このタスクをエピソードと呼ぶ。各エピソードをTtrとTteの二つに分割する。
③Ttrを用いて、base learnerを再学習する。
④ Tteを用いて、③で学習したパラメータを最適化する(meta learnerの学習)
⑤ ①〜④で学習したmeta learnerを用いて、未知のタスクであるmeta testのデータを評価する。
上記のステップが一般的なメタ学習です。これを踏まえた上で、提案手法の紹介をしていきます。
提案手法
ここからは提案手法を見ていきましょう。提案手法は大きく分けて4つのステップで構成されています。
① 大規模なデータDでbase learnerを学習させる。
② エピソードTを抽出し、base learnerの分類層を付け替えて、その層のみをTtrを用いてmeta leanerを学習する。学習したパラメータをθとする。
③ 別の少量のパラメータΦをTteを用いて学習する。
④ 最後に②で学習したパラメータθをTteで学習する。
では、①と②〜④に分けて、上記のステップを詳細に見ていきましょう。
大規模なデータでの学習
①では大規模なデータでの学習を行います。これは基本的なメタ学習と同じです。
少量のパラメータでの学習(MTL)
従来のメタ学習では、一度大規模なデータで学習させた後に、学習したパラメータを抽出したエピソードTで再学習していました。しかし、これでは学習の効率性も悪く、一度学習したタスクを忘れてしまう可能性があります(破壊的忘却)。そこで、本研究ではMeta Transfer Learning (MTL)を提案しています。図2は従来手法とMTLの違いを表したものです。
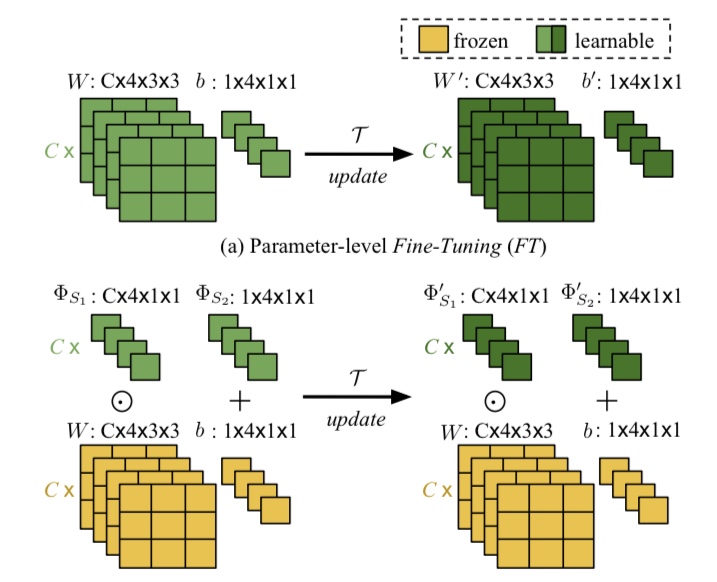
図2. 提案手法と従来手法の違い
MTLは図2にあるように、少量の別のパラメータΦを用意し、抽出したエピソードTでΦのみを学習します。これにより、効率よく、破壊的忘却をさせることなく学習することが可能となります。この学習したパラメータΦを用いて、以下のScaling and Shifting(SS)という操作を行います。なお、パラメータΦはネットワークの層の数だけ用意します。
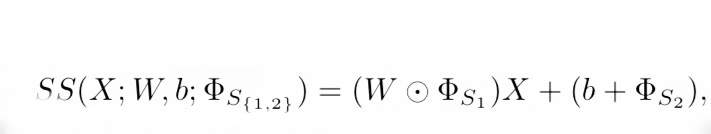
式1. SS操作
まとめると、上記に述べた操作により、以下の三つの効果が期待されます。
1) 効率よく学習が行える
2) 破壊的忘却を防ぐことができる
3) 少量のパラメータのみを学習させることで過学習を防ぐことができる
人間の学習を考えると、一度学習したものを全て更新するということはせず、一部のみ変更・学習していると考えられます。その意味で、MTLはより人間らしく学習を行う手法だと考えられます。
また、3)により、深いネットワーク構造でも過学習することなく、学習することが可能となります。これにより、強力なネットワーク構造を使用することが可能となるという大きなメリットが生まれます。
難しいタスクの重点的な学習(HT)
さらに提案手法では、hard task meta batch(以下、HT)を提案しています。従来手法(meta batch)では、タスクはランダムに抽出していました。HTでは、②においてランダムにタスクを抽出するのではなく、これまで学習した中で、難しいタスク(精度の低いタスク)を重点的に抽出を行います。
これも人間の学習と比較すると、分かりやすいかと思います。簡単に解ける問題より、難しい問題を重点的に解いた方が、どこに着目すれば問題が解けるか分かるようになると考えられます。これをHTではこれを利用して、学習を行います。
実験結果
ここからは提案手法を用いて、二つのデータセットで実験を行った結果を見ていきます。
データセット
・miniImageNet
ImageNetをメタ学習用に再構築したデータセットです。100クラスで、各クラスごとに600枚の画像が用意されています。このうち、64クラスをmeta-trainig用、20クラスをmeta-test用、残りの16クラスをmeta-validation用に分けます。
・Fewshot-CIFAR100(FC100)
CIFAR100をメタ学習用に再構築したデータセットです。100クラスにそれぞれ600枚の32×32ピクセルの画像で構成されています。100クラスのうち、60クラスをmeta-training用、20クラスをmeta-test、残りをmeta-validation用に分割しています。それぞれのクラスはsuperクラスと呼ばれるものに属しており、miniImageNetに比べて、似ているクラスが同じ分割に入らないようにされています。
実験設定
まず、meta-training用の全てのデータでbase leanerを学習させます。次に、5クラス分類で、Ttrに1,5,10枚の画像を、Tteに15枚の画像を使用してmeta leanerを学習します。従来手法ではTteに32もしくは64枚の画像を使用しています。
ネットワーク構造
使用するネットワークは4層の畳み込み層で構成された4CONVとResnet-12を用います。これは画像特徴量を抽出する機構であり、Θと表記します。分類層は一つのFC層を用います。分類層はθと表記します。
実験結果
まず、提案手法であるMTLの性能を見ていきましょう。図1はResNet-12を用いて、MTLと従来手法を比べた結果です。
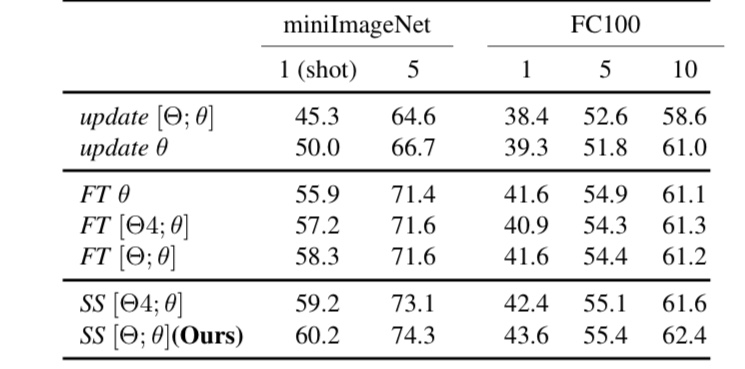
図3. 提案手法の効果
ここで、updateはメタ学習なしでの学習、FT(Fine Tuning)は従来のメタ学習手法での学習、SSは提案手法です。各手法に記載の【】は学習させるパラメータを表しています。例えば、【Θ;θ】はパラメータ全てを学習することを表しています。なお、4ΘはResNetの4段目のパラメータを表しています。
図3によると、提案手法は従来手法より高精度に画像分類を行えています。特にminiImageNetにおいて、高精度であることがわかります。この結果よりMTLがFew-shot learningにおいて効果的だということが分かります。
また、以下の図4をご覧ください。
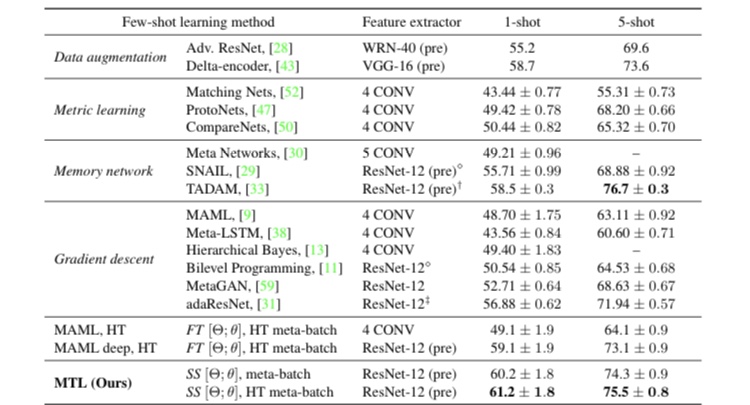
図4. miniImageNetにおける提案手法と従来手法の結果の比較
図4はminiImageNetにおいて、様々な手法と提案手法を比べた図です。1-shotにおいて、提案手法(MTL +HT)は最も高い精度を出しています。5-shotにおいては、TADAMという手法に精度が劣っていますが、この手法はResNet-12に72のFC層を加えたネットワークを使用しています。これは提案手法より、多くのパラメータが必要となり、学習の収束が遅くなります。
また、4CONVよりResNet-12を使用するほうが、より高精度に分類出来ていることが分かります。MTLを用いることで、少量のパラメータの学習だけで良くなり、深いネットワークでも過学習せずに学習することが可能となっています。
また、学習するパラメータが少なくなったことによる効果を見てみましょう。以下の図は、2つのデータセットでの学習曲線を表しています。

図5. 提案手法による学習スピード
ここで、図5(a)(b)はそれぞれminiImageNetでの1-shot、5-shotにおける結果です。また、図5(c)(d)(e)はFC100における1-shot、5-shot、10-shotにおける結果を表しています。
従来手法では、120kのiterationが必要でしたが、提案手法ではどちらのデータでも10分の1以下の学習で収束しています。特にFC100においては、1〜2kのiterationで収束しています。
まとめ
本記事では、人間と同じように学習するメタ学習手法を紹介しました。提案手法は少量のパラメータのみ学習させています。さらに、難しいタスクを重点的に学習することで少ないデータで画像分類のタスクを高精度かつ効率的に解くことを可能となりました。
人間のように学習させるということは、人間のことをより深く知る必要があります。脳科学などの知見がメタ学習にも取り入れられると、より優れた手法が登場するのではないかと思います。
このような研究の延長線に、人間のような知性が生まれるのではないかと、個人的に思います。メタ学習の研究は近年、盛んに行われており、より一層優れた手法が登場すると考えられます。メタ学習に興味を持たれた方は、最新の動向を逐次チェックしてみることをオススメ致します。
Meta-Transfer Learning for Few-Shot Learning
written by Qianru Sun, Yaoyao Liu, Tat-Seng Chua, Bernt SchieleAccepted to CVPR2019 open Access
Subjects: Computer Vision



この記事に関するカテゴリー






