敵対的サンプルは”バグ”ではなく意味のある”特徴”
論文:Adversarial Examples Are Not Bugs, They Are Features
敵対的サンプルは、”バグ”ではない?
ニューラルネットワークの脆弱性は、近年大きな注目を集めています。特に懸念されるのは、Adversarial example(敵対的サンプル)と呼ばれるな事例の現象です。
Adversarial exampleはニューラルネットワークモデルに対し、分類エラーなどの誤った出力を引き起こし、認識させないようにする一種の攻撃です。
【関連】ディープニューラルネットワークを欺くための1ピクセル攻撃
ニューラルネットワークを騙すGAN 顔認識ネットワークに別の人物として認識させることが可能に

Adversarial exampleによって引き起こされたの違いは人間にとって区別が難しいですが、それでもニューラルネットワークは左上のパンダを非常に高い確信を持ってテナガザルとして誤って分類します。
今まで一般的に言われてきたのは、Adversarial exampleは、モデルの“特異モード”から生まれるものであり、よりよいトレーニングアルゴリズムとより大きなデータセットで十分な成果を出せば、バグは消えてしまうということです。一般的な意見としては入力空間が高次元であったり、限られたサンプル事象の結果であったりするということです。
しかし、本当にバグなのでしょうか。
新しく出た論文では否定的な答えを出しています。
通常(分布)精度を最大にするためだけに分類モデルを訓練します。その結果、モデルは、たとえ人間にとって不可解に見える信号であっても、利用可能な任意の信号を使用する傾向があるというのが論文の主張です。
事実、標準のMLデータセットには、非常に予測性は高けど人間には知覚できないパターンが含まれていることがわかりました。モデルは、そのようなパターンから生じる「ロバストでない」特徴に頼り学ぶことを前提としており、この依存が敵対的な混乱を招くと考えています。
様々な実験を通して、Adversarial exampleがバグではなく、意味のある”特徴”であることを証明しています。
敵対的サンプルで学習させる
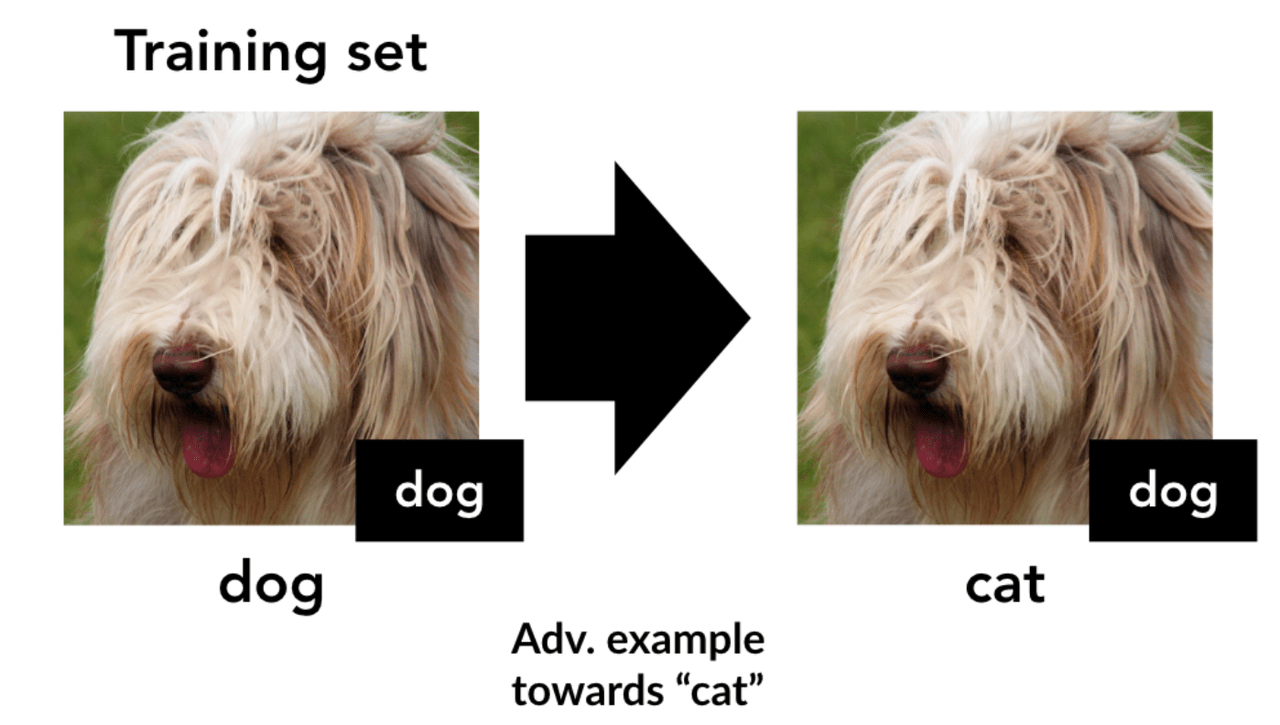
標準の画像データセットを用意し、これら犬の画像に”ネコ”と誤認識させる敵対的摂動を仕掛けたデータセットを作成します。次に、これらのAdversarial exampleのクラスに対応するラベル”ネコ”を付け、この間違った”ネコ”ラベルからモデルを訓練します。

この分類モデルは、 元の(変更されていない)テストセット(標準CIFAR-10テストセット)でどのように機能するのか調べました。驚くべきはこの摂動特徴のみで訓練され、人間が認識する基本的な視覚特徴では訓練されていないこのモデルが、元の正常な条件下のテストセットに対して中程度の精度(例:CIFARでは44%)を達成したことです。
敵対的サンプルは汎化を助ける
入力はオリジナルとほぼ同じでしたが、すべて間違ってラベル付けされていました。誤ってラベル付けされたデータセットをトレーニングすることで、人間に見えるような予測可能な情報がないにもかかわらず、高い精度が得られました。このプロセスは、トレーニングセットの入力が小さな敵対的摂動のみを介してラベルに接続されていることを実証しています。
つまり、Adversarial exampleは、一般化された意味でのターゲットクラスを予測するパターンとして利用できるということです。
さらに、論文ではデータの予測特徴は「ロバスト」と「非ロバスト」な特徴に分割できると仮定しています。
ロバストな特徴は、人間に定義されたAdversarial exampleを仕掛けられた場合でも、真のラベルを予測しますが、非ロバストな特徴はAdversarial exampleに対応します。訓練後に猫ラベルを付け直した後、ロバストな特徴が実際には間違った方向(すなわち、頑強な犬の特徴を持つ絵は猫と分類される)を指しましたが、一方、非ロバストな特徴は実際に汎化に対する正しいガイダンスを提供できています。
ロバストな特徴だけで学習させる

また、ロバストな特徴だけを含むデータセットを用いてテストしています。Adversarial exampleを用いてロバストになるように訓練されたモデルを使い、ロバストなトレーニングセットだけを作成します。
このデータセットを、Adversarial exampleなしに訓練します。結果として得られたモデルが強い正確さとロバスト性を持っていることが分かりました。これは、標準的なトレーニングセットでのトレーニング(正確ではあるがもろい)とは全く対照的です。
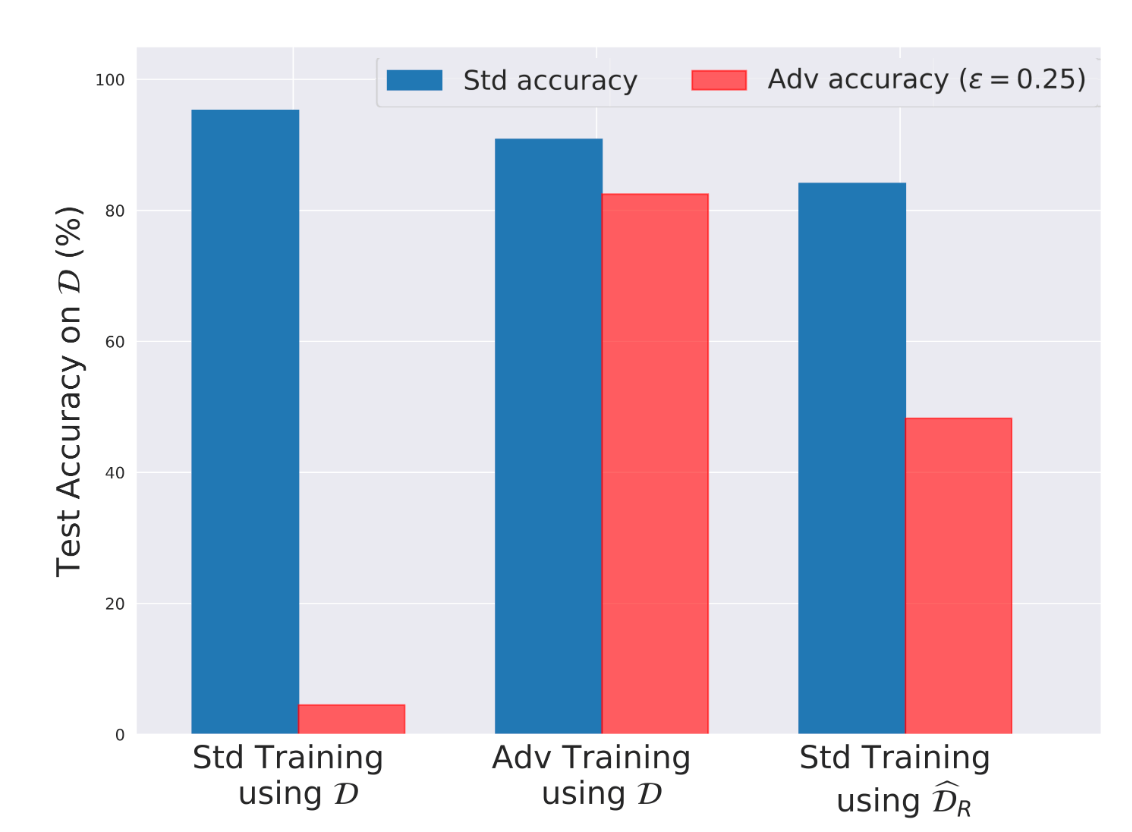
結果から、ロバスト性(ひいては非ロバスト性)が実際にはデータセット自体の特性として生じている可能性があることがわかりました。これは、Adversarial exampleが、必ずしもトレーニングアルゴリズムやデータセットの大きさに関連しているわけではないという証拠です。
結論
最後に、この論文では、人間中心の現象としてAdversarial exampleを扱っています。なぜなら、標準的な教師つき学習の観点から、非ロバストな特徴はロバストなものと同じくらい重要であり得り、分類タスクのパフォーマンスの観点からは、ロバスト性だけを好む理由はないからです。この観点から、敵対的な摂動を用いた訓練は、必要な不変性を学習モデルに組み込むためのツールと考えることができます。
同時に、標準モデルにおける非ロバスト性は、解釈可能性を向上させることを目的としたアプローチを考慮する必要があります(人間に理解できないため)。特に、モデルの予測に関する「説明」は、そのような非ロバストな機能を強調するか、または隠す傾向にあるからです(人間にとって意味のあるものではないとされがちなため)。
説明可能性はモデルの忠実性と人間の両方にとって意味のあるものではないのかもしれません。



この記事に関するカテゴリー






