たった2行で画像認識モデルの精度向上!?新しいDataAugmentation自動最適化手法「RandAugment」解説!
3つの要点
✔️ ランダムにData Augmentationの手法を選択するRandAugmentを提案
✔️ 従来のAutoAugmentと比べ探索空間を$10^{-30}$にも削減し計算量を激減させたことで実践で使えるようにしただけでなく、CIFAR-10/100やImageNet, COCOなどのデータセットにおいて有用性が確認できた
✔️ ImageNetのSoTAであるNoisyStudentにも使われており、関数は2行で実装できるため読者の方も容易に使うことができる。
RandAugment: Practical automated data augmentation with a reduced search space
written by Ekin D. Cubuk, Barret Zoph, Jonathon Shlens, Quoc V. Le
(Submitted on 30 Sep 2019 (v1), last revised 14 Nov 2019 (this version, v2))
Comments: Published by arXiv
Subjects: Computer Vision and Pattern Recognition (cs.CV)
導入
画像認識の分野では、画像データを少し回転させたり左右反転させたりなどの操作をすることで画像データ数を増やすData Augmentation(以下、DA)が広く使われています。ただ、どの操作を行うのかというのは試行錯誤で見つけるしかなく時間がかかります。そこで強化学習を使うことで自動的にDAを選択してくれるというAutoAugmentが提案されました。AutoAugmentは膨大な計算量から実際のタスクよりも小さいタスクに対して最適なDAを探し、その結果を実際のタスクにも使うという戦略を使っています。しかし、本論文では既存手法であるAutoAugmentに対して以下の2つの致命的な欠点があることが指摘されています。
- 強化学習を必要とするため計算量が膨大(探索空間$10^{32}$)すぎて使いづらい
- 小さいタスクに対して最適だからといってそれが本来のタスクにおいても最適とは限らない
この膨大な探索空間を削減($10^2$)することで計算量をはるかに抑え、上記2つの欠点を解決したものこそがRandAugmentです。下の表を見てもRandAugmentの探索空間の小ささと性能の高さがわかります(ここでBaselineとは”flip left-right”および”random translation”だけを適用して学習させたモデルです)。
本記事ではこのRandAugmentの仕組みおよび実験結果を解説していきます。
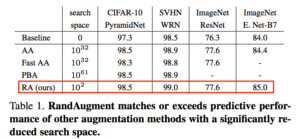
(AA: AutoAugment, PBA: Population Based Augmentation, RA: RandAugment,
WRN: Wide-ResNet, E. Net: EfficientNet(解説))
本記事の構成は以下になります。
- RandAugment解説
- RandAugment実験結果
- 結論
続きを読むには
(5302文字画像12枚)AI-SCHOLARに
登録いただく必要があります。



この記事に関するカテゴリー






