CGとAIの架け橋「微分可能レンダラー」のルーツを日本発の論文から探る
Written by 加藤 大晴1 牛久 祥孝1 原田 達也1,2 (1東京大学 2理化学研究所)
CVPR 2018 (spotlight)
Google I/O 2019のプレゼンテーション”Cutting Edge TensorFlow”にて、GoogleからTensorFlow Graphicsが発表されました。
Tensorflow Graphicsはゲームや映画で多用される3Dコンピュータグラフィックスの知見を、画像認識に代表されるコンピュータビジョンの領域で活用することを目的に作られたもの(下図参照)で、現在は微分可能レンダラー(differential render)や3Dモデルに適応可能なグラフ畳み込みといった機能を持つTensorflow用のライブラリと、機械学習の可視化を支援する3D TensorBoardがGitHubで提供されています。
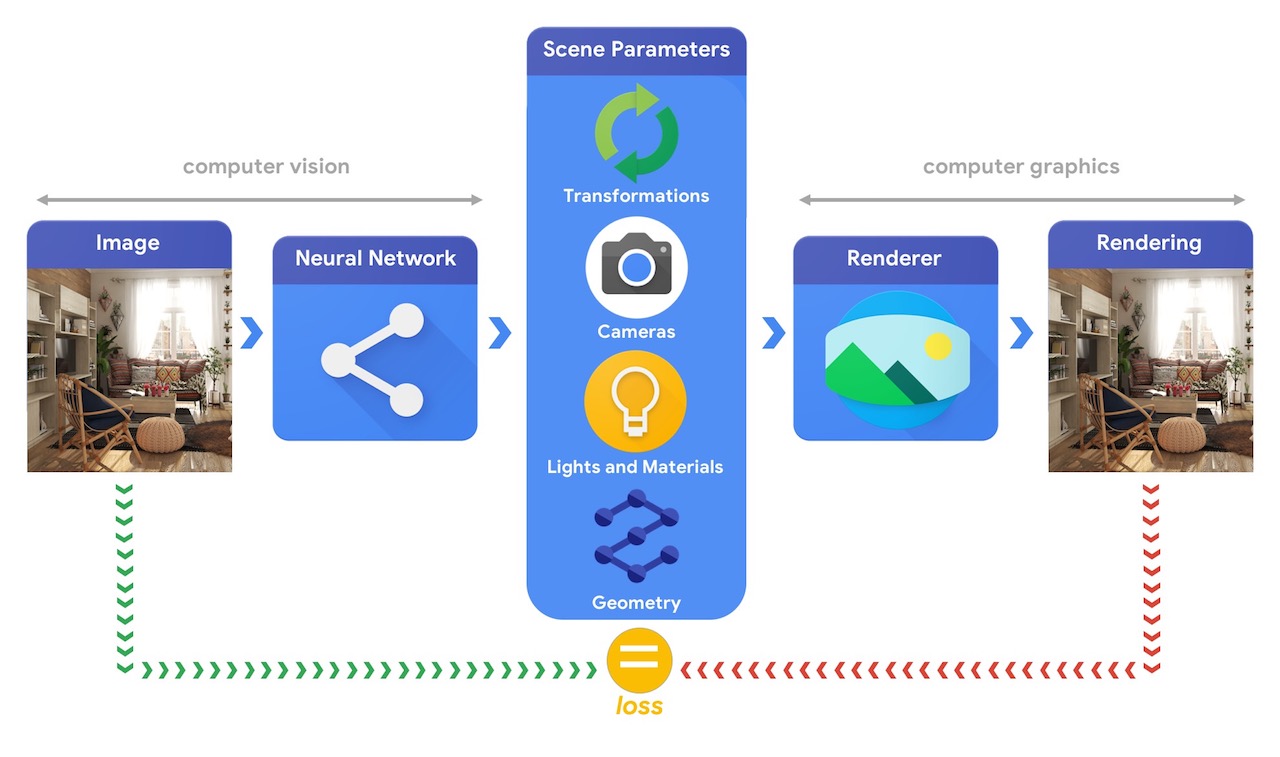
Tensorflow Graphicsの全体図
といっても、何のことやらさっぱり…というとそこのあなた。微分可能レンダラーの定義をお話しする前に、自動運転という画像認識の一大分野における課題と応用ついて考えてみたいと思います。
通常、自動運転における機械学習モデルの構築には、車載カメラで記録した動画像を、なんらかの手法で「これは人」「あれは自動車」という風に画像内の領域にタグ付けを行い、教師データを整備して学習させる必要があります。
しかし、これらの教師データを大量に用意するのは非常に大変なことで、撮影のための実車や、タグ付けチェックのための人手などに莫大なコストがかかってしまいます。
ここで、現実と見まがうほどの写実的(photo-realistic)な映像をCGで作り出せるとしたらどうでしょうか?
最近では、カーレースゲームでも、一回のゲームのプレイデータを元に非常にリアルなリプレイを様々な角度や条件で生成することができます。ならば、CGで作った運転シミュレーションの映像を学習に使うことで、教師データの質とボリュームの問題を解決できるはずです。しかしながら、もちろん課題はあり、車や人、あるいは信号機といった運転に絡むすべての要素を本物らしく再現しないといけません。
例えば車なら様々な車種の3Dモデルを用意する必要があります。これを人手で頑張るのはやっぱり大変なので、AIを使ってある程度自動化したいですよね?
微分可能レンダラー
そこで、微分可能レンダラーの出番です。まずレンダリング(rendering)とは、3Dモデル・カメラ・ライティング条件といった要素で構成される3D空間(を構築するパラメータ群)から2D画像に変換することを指し、レンダリングを行うプログラムをレンダラーと呼びます。
そして、逆に2D画像から3D空間の推定を目的としたプログラムを微分可能レンダラーと呼びます。ここで3Dモデルには、ボクセル(voxel)や、ポイントクラウド(point cloud)、メッシュ(mesh)といった表現手法があり、ボクセルやポイントクラウドはニューラルネットで扱いやすいことから多くの研究があります。一方、メッシュという三角形の集合体はメモリ効率や、幾何変換との親和性、またテクスチャマッピング(texture mapping)のようなカスタマイズ性の高い描画が出来ることから、ゲームや映画などで多用されているものの、高精度に2D画像から再構築する手法が当時は存在しませんでした。
この問題を克服するため、メッシュの微分可能なレンダリング(関数)の『逆伝播』を再定義し、ニューラルネットワークへ組み込むことを可能にしたのが、本稿で取り上げる加藤らの “Neural 3D Mesh Renderer, CVPR 2018”です。そしてアプローチは異なりますがニューラルネットを用いて3D空間を推定するGoogle/DeepMindのEslamiらの論文 “Neural Scene Representation and Rendering, Science 2018” がその後採録され、まさに微分可能レンダラー時代の幕開けとなりました。
何が可能になったのか
一口に3D空間と言っても様々な要素がありますが、この論文では下記パラメータの推定を扱っています。
・三角形メッシュの頂点位置(3次元座標)
・メッシュ上のカラーテクスチャ
・カメラ(位置、向き、画角など)
・ライト(平行光源 の向きと強さ、環境光の強さ)
“頂点位置の推定”とは何かという話ですが、これは幼児が粘土で何かを作るイメージを想定して頂ければ良いかと思います。
最初に、球状の粘土があり、作りたいイメージ…例えば飛行機があるとします。そして粘土の形を少しずつ変えながら、そのシルエットがなるべく目標とする飛行機に近くなるように変形するプロセスが推論に相当します。
なお、補足しておくと粘土をちぎって複数に分割する、また穴を開けるというような操作(CG用語に置き換えるとトポロジーの変更)はこの論文では想定していません。
それでは、この手法で何が新しくできるのか?論文の著者がプロジェクトページで公開している以下のアニメーション画像を見て頂くとイメージしやすいかと思います。
(i)単一画像からの3Dメッシュ再構成
以下の図は椅子の2D画像から、椅子の3Dモデルをメッシュとして再構成した様子を示したものです。
 |
→ |  |
以下は従来のボクセルベースの手法と比較図になります。ボクセルは斜めの面を表現しようとすると、立方体の”ギザギザ”が発生してしまうことがわかります。解像度を高めれば緩和しますが、計算量やメモリ消費量が3乗のオーダーで増大してしまうため実現は容易ではありません。
|
 |
提案手法の再構成性能は、領域の一致具合を示す評価指標(Intersection over Union; IoU)で比較すると、13カテゴリ中10カテゴリでボクセルベースの手法を上回っています。

(ii)画像から3Dへのスタイル転移
ニューラルネットワークに組み込み可能なレンダラーを実現することの大きなメリットの一つは、既存のディープラーニングベースの機械学習モデルの併用ができることです。例えば、スタイル変換(style transfer)を組み合わせることで、画像から3Dへのスタイル変換も可能であることを論文は示しています。
下図は左から、適用するスタイルの画像、スタイル変換前のメッシュ、変換後のメッシュになりますが、色だけではなく頂点位置にも変更が加わることにより、カクカクした画風が反映され、ポリゴン形状に変化した様子が伺えます。
 |
→ |  |
まとめ
最後に、下画像はメッシュ再構築とスタイル変換の流れの全体図です。
この論文は、レンダリングの中でもラスタライズ(Rasterization)という三角形の塗りつぶし処理を、”いかに微分可能な処理として再定義するか”に主眼が置かれているため、 他の一般的なCV論文に出てくるようなネットワーク図は出てきません。
また、内容の理解には機械学習だけではなくCGのドメイン知識を読者に求めてしまうことから、なぜこのような技術が必要とされているのかという背景を本稿では重点的に記述させて頂きました。
私は、もともとCGの研究者だったこともあり、まさにCGとAIと架け橋ともいえる「微分可能レンダラー」には大きな可能性を感じています。そして、CGの使用用途として代表的な存在とも言えるゲームや映画は、今度はAIを鍛える側になり得るというのは未来感が溢れる話ではないでしょうか?
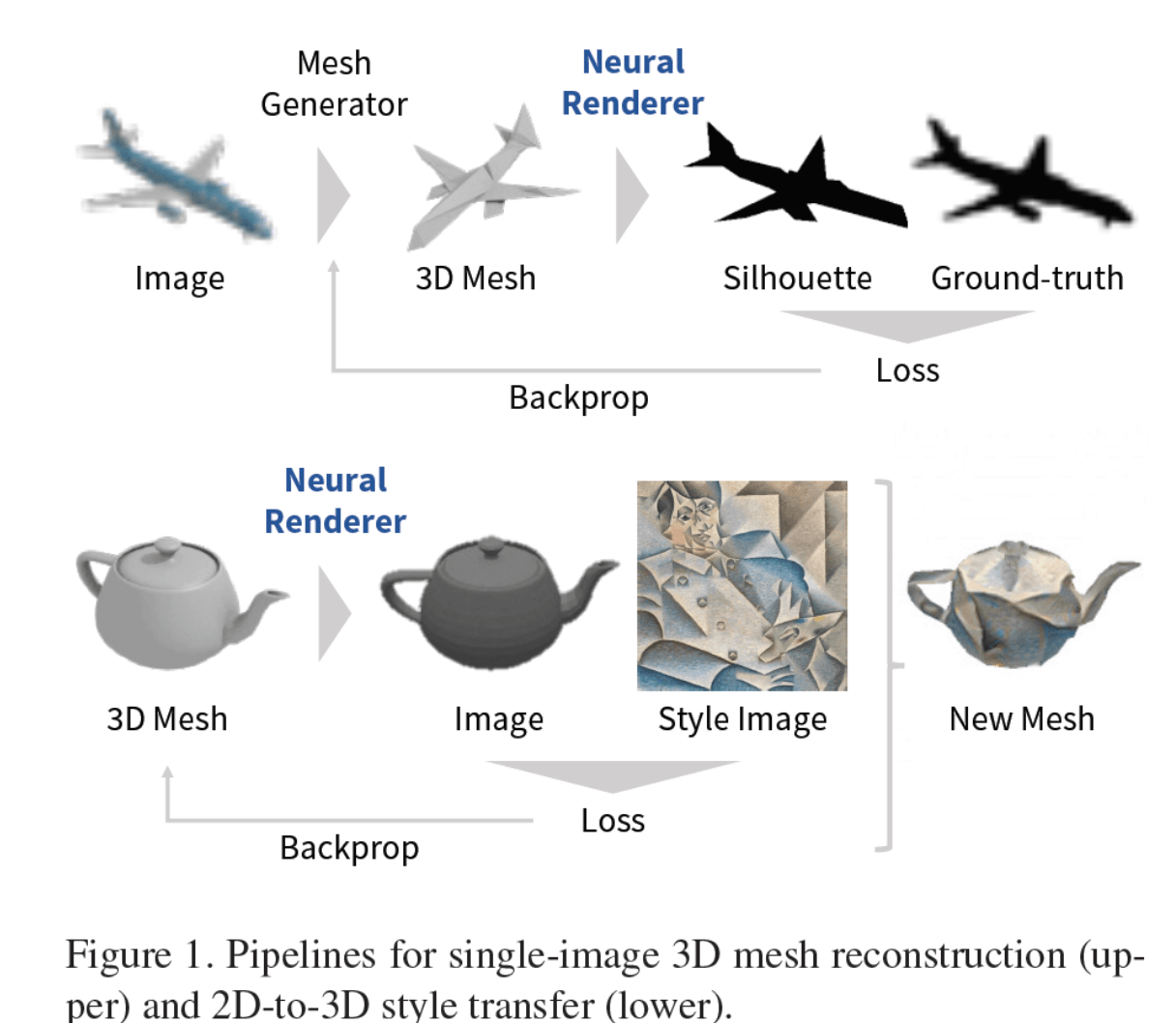
メッシュ再構築とスタイル変換のパイプライン




この記事に関するカテゴリー






