DL論文から自動的にソースコードを生成。直感的なUIで編集することも可能
個の記事で紹介するのは、論文からコードを書くのを自動化する取り組みです。DNN関係の論文に掲載されている図や表から、Keras/Caffeのコードを自動生成します。さらにarXiv-風なwebサイトを構築し、5000論文を元に直感的なUIで操作できるクラウドを提供しています。
論文:DLPaper2Code: Auto-generation of Code from Deep Learning Research Papers
研究の再現性を高める
ディープラーニング関連の論文の充実に伴い、既存の研究の再現と採用が課題となっています。さらに、異なるフレームワークに関する研究論文を再現することは困難な作業です。
これらの課題に対処するために、本稿では、論文からコードを書くのを自動化する試みを提案しています。
著者らは論文を自動的に解析し、記述されたDL(ディープラーニング)モデル設計を抽出する新しいアルゴリズムDLPaper2Codeを提案しています。この方法は、研究論文の中から利用可能なDL学習設計フロー図と表を抽出し、抽象的な計算チャートに変換します。抽出された計算グラフは、リアルタイムで実行可能なKeras /Caffeソースコードに変換されます。
さらに、著者らはarXivに似たウェブサイトを作成し、5000の研究論文によって自動的に生成されたデザインを公開しました。これらは、直感的なドラッグアンドドロップのUIフレームワークを使用したクラウドソース方式で編集および評価することが可能です。
DLPaper2Code
テーブル(ビジュアルコミュニケーションとしてデータを並べる手段)はさまざまな構造を持つことができ、さまざまな種類の情報を伴うことがあります。
一方、研究論文では、DLデザインは主に図表を使って説明されており、調査論文には、図、テキスト、表にまたがって実装されるのに十分な情報が含まれていることがわかりました。したがって、本稿では画像としての図と表の内容を解析することに焦点を当て、そこからそれぞれの新しいDL情報を取得しています。論文より図とテーブルを抜き取り、実装ライブラリや言語に依存しない抽象計算グラフとして表現し、この抽象計算グラフから複数のライブラリでソースコードを自動生成します。
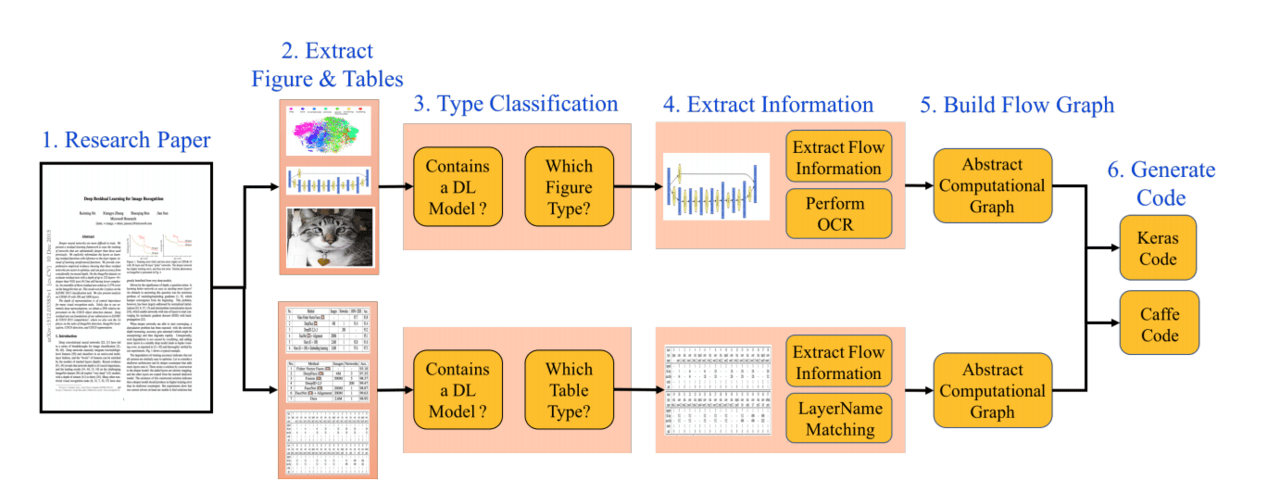
図1
提案するDLPaper2Code構造には、図1に示すようにいくつかの主要部分が含まれています。
1、研究論文のPDFからすべての図と表を抽出する。
2、バイナリ分類器を訓練して、どの画像とテーブルが深い学習モデルフローを表すかを検出。さらに、DLモデルを記述するために使用される図形や表のタイプについて、きめ細かい分類を実行。研究論文で利用可能なDLモデル設計を特徴付け、それらを5つの異なるカテゴリに分類する。
3、以下の図に示すように、画像を解析してノード、エッジ、フローを抽出し、抽象計算グラフを作成。さらに画像にOCRを実行してテキストコンテンツを抽出する。
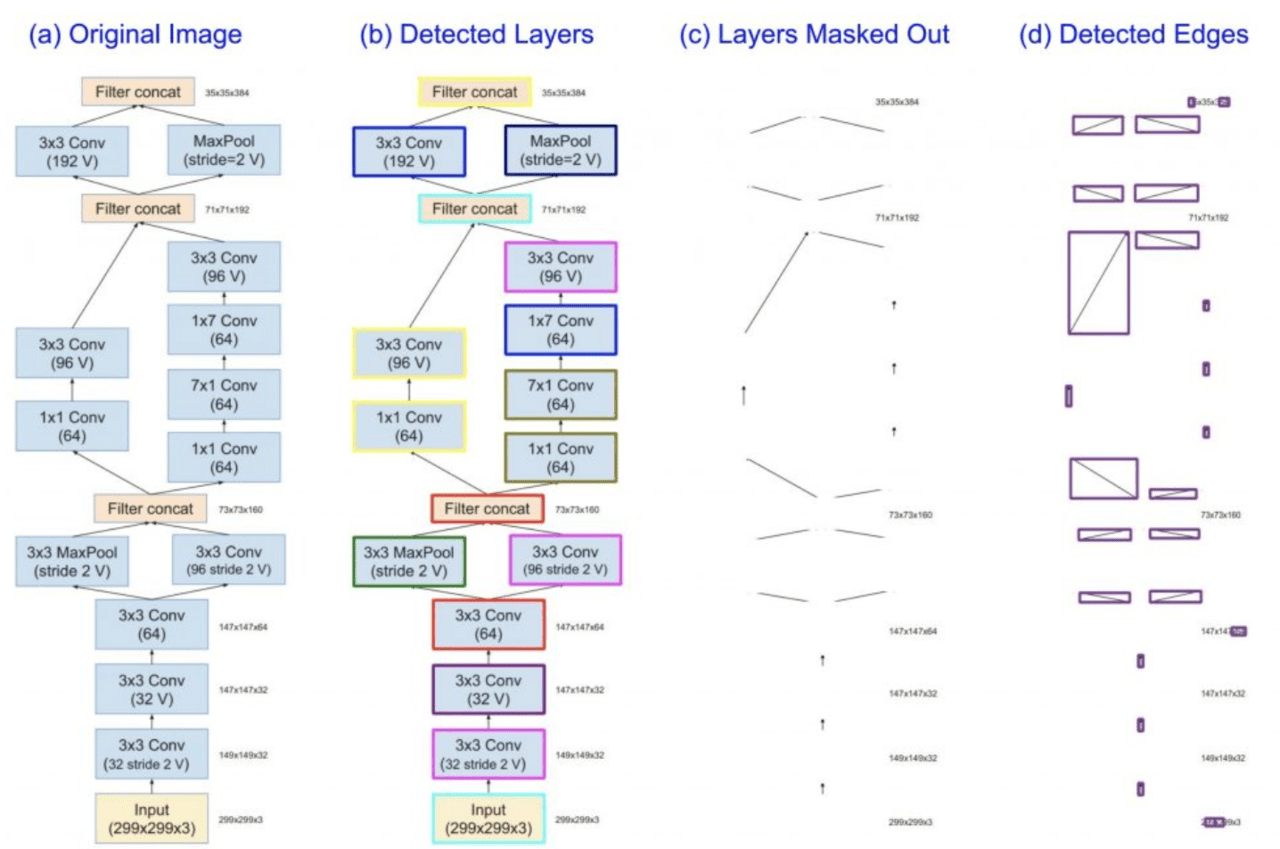
(この表は、行優先形式または列優先形式のどちらでも記述できます。PDFリサーチペーパーの表の配置に基づいて、表は独立して解析され、ディープラーニングモデルフローが抽出されます。)
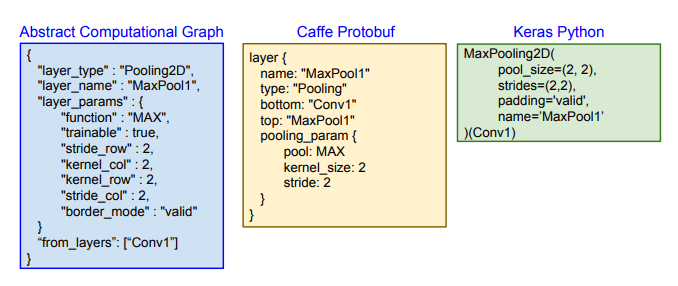
4、前のステップで抽出した抽象計算グラフを次の図に示すようにJSON形式に変換。さらに、JSONフォーマットで表現された抽出されたデザインから、手作業でキュレーションされたテンプレートベースのコードを使ってKeras(v2.1.2)、Caffe(v1)、Tensorflow(v1.4)、PyTorch(v0.3)でソースコード生成をサポートする。
DLモデルは5つの広いカテゴリーに分類される
本稿では徹底的な分析を行い、研究論文からの30,000枚以上の画像を手作業で観察し、DLモデルが図2に示すように5つの広いカテゴリーに分類されることを発見しました。これらの画像を5つのカテゴリー、すなわち(a)ニューロンプロット、(b)2Dボックス、(c)2Dボックス、(d)3Dボックス、および(e)パイプラインプロットに大別しています。ここでは、現在、既存の研究論文のおよそ50%を占める「2Dボックス」タイプの画像からの設計フロー情報の抽出をサポートしています。
 図2
図2
評価
提案されたDLPaper2Codeフレームワークを使用して、5000以上のダウンロードされた論文からDLモデル設計フレームワークを抽出しました。しかし、定量分析によって生成されたフレームワークプロセスは、標準的な評価方法がないため、実装が困難です。そこで著者らはarXivに似たWebサイトを構築しました。WebサイトではDLデザインと5,000件の研究論文のソースコードなどが提供されています。
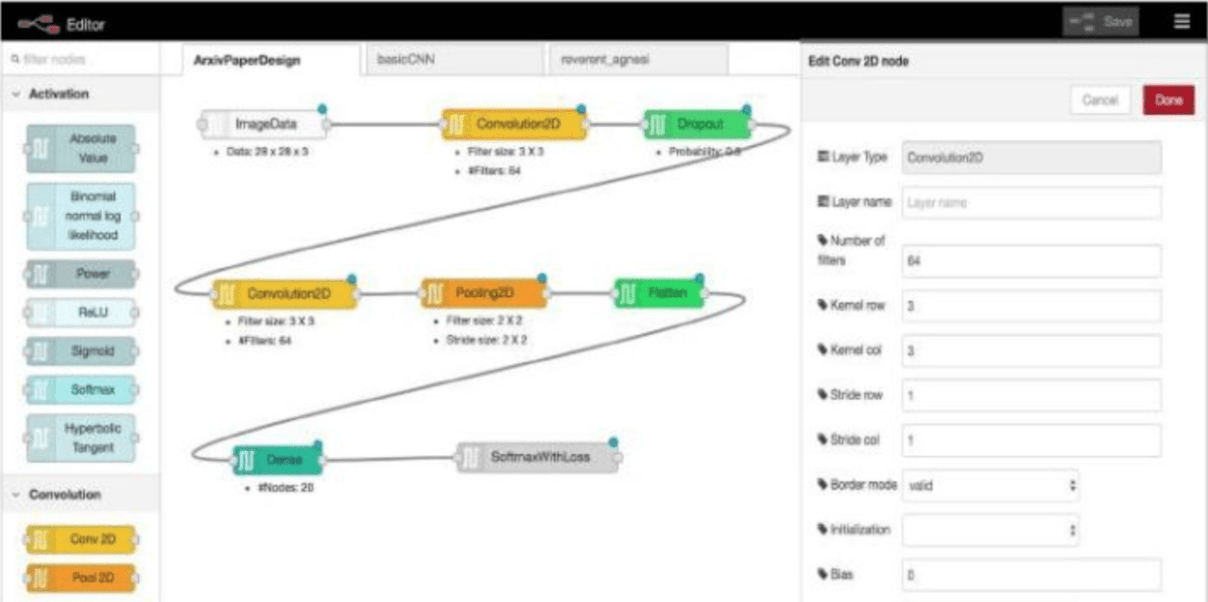
自動生成効果を測定するためのフィードバックとして、抽出されたデザインをユーザーによってスコアリングされます。さらに下図に示すように調査の一環として設計したUIベースの直接ドラッグアンドドロップエディタを使用して、抽出したデザインを手動で変更し、改良することができます。これにより、もし自動抽出が間違えていても直感的なインタラクティブで修正することが可能です。
さらに、提案された文法を評価するために、KerasとCaffeフレームワークのためのそれらの対応する2D Box視覚化から216,000以上の深層学習モデルのためのソースコードを作成しました。このデータセットに対する実験は、提案されたアプローチがフロー図内容を抽出することにおいて93パーセントを超える精度を有しているとのこと。
研究目標としては、研究努力を再現しやすくすることでディープラーニングを民主化することだそう。今後の課題としては、モデルの理解と再利用を容易にするために、深層学習モデルが研究論文で表現されている形式を標準化することでしょう。



この記事に関するカテゴリー






