Google、オーディオデータを視覚的に表現するデータ増強法「SpecAugment」を発表
Google AIが、最先端の自動音声認識モデルのパフォーマンスを向上させる技術「SpecAugment」を発表しました。 オーディオデータを視覚的な問題として扱うことでデータの増強に成功しています。
【参考論文】SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition
オーディオデータを、視覚的な問題として扱う
音声入力を受けてそれをテキストに転写するプロセスである自動音声認識(Research Scientist Automatic Speech Recognition、以下ASR)は、ディープラーニングから大きな恩恵を受けています。現在ASRは、グーグルアシスタント、グーグルホーム、そしてユーチューブのような多くの製品に使われ、至る所で見るようになりました。

しかし、ディープラーニングベースのASRシステムを開発する上で、多くの重要な課題が残っています。課題の一つとして挙げられるのは、多くのパラメーターを持つASRモデルは、トレーニングデータを過剰に適合させる傾向があるということです(過学習)。
一般的に十分な量のトレーニングデータがない場合、データの増強プロセスを通じて既存のデータの有効サイズを増やすことが可能であり、これは画像分類の分野におけるディープラーニングでよく使われるプロセスです。
しかし、音声認識でデータの増強をする場合、トレーニングに使用される音声波形を何らかの方法で(例えば、それを加速または減速することによって)変形すること、または背景雑音を追加することを含みます。つまり、用意するデータ自体は大量の音声データが必要となり、膨大な計算コストがかかります。
最近発表された論文では、これらをオーディオデータではなく、視覚的な問題として扱います。従来から行われているように音声データ(オーディオ波形)を増強する代わりに、SpecAugmentでは、スペクトログラムを直接増強します(すなわち、音声データの視覚的表現)。この方法は単純で、計算コストが安く、追加のデータを必要としません。また、ASRネットワークのパフォーマンスを驚くほど向上させ、ASRタスクで最先端のパフォーマンスを実証しています。
スペクトログラム自体を直接編集して増強するアプローチ
従来のASRでは、音声データを、スペクトログラムなどの視覚的表現に変更してからネットワークモデルにエンコードしていました。認識処理はスペクトログラム(視覚的表現)で行われますが、用意するトレーニングデータ自体は大量の音声データが必要となり、膨大な計算コストがかかります。(図1)
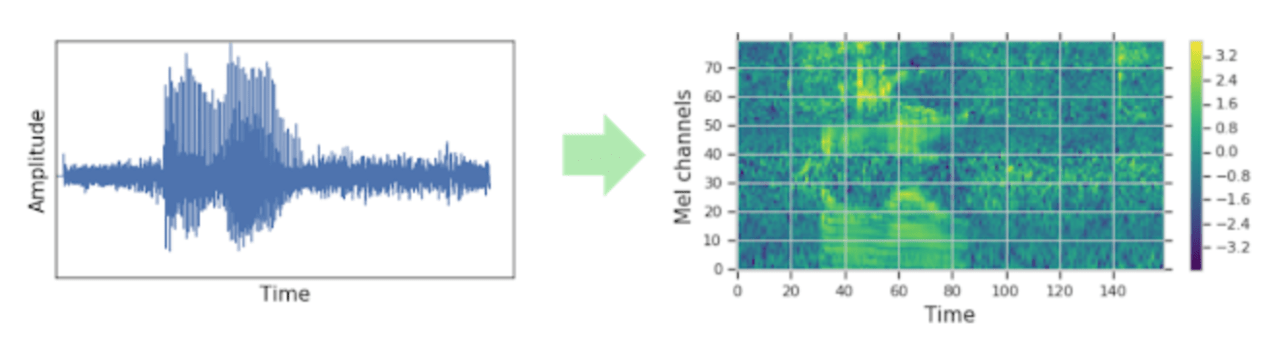 図1:従来の方法:音声データは通常、ネットワークに入力される前に視覚的表現に変換される。
図1:従来の方法:音声データは通常、ネットワークに入力される前に視覚的表現に変換される。
一方、今回のアプローチでは、音声データではなくスペクトログラム自体を直接編集して増強するアプローチを調査します。強化はネットワークの入力機能に直接適用されるため、トレーニング速度に大きな影響を与えることなく実行できます。
具体的には、スペクトログラムを時間方向にワープし、連続した周波数チャネルのブロックをマスキングし、発話のブロックを時間的にマスキングすることによってスペクトログラムを修正します。(図2ご参照ください)
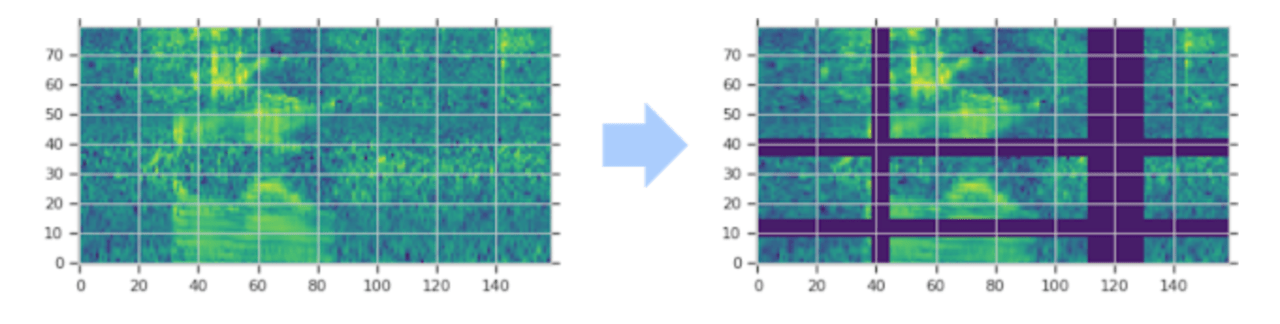 図2:スペクトログラムは、時間方向にワープし、(複数の)連続する時間ステップのブロック(垂直マスク)およびメル周波数チャネル(水平マスク)をマスキングすることによって増強されます。スペクトログラムのマスクされた部分は、強調するために紫色で表示されています。
図2:スペクトログラムは、時間方向にワープし、(複数の)連続する時間ステップのブロック(垂直マスク)およびメル周波数チャネル(水平マスク)をマスキングすることによって増強されます。スペクトログラムのマスクされた部分は、強調するために紫色で表示されています。
言語モデルなしで高い精度を実現
そしてもう一つ重要なのは言語モデル(LM)の助けがいらないということです。言語モデルとは、言語において単語と単語の関係を数学的に表したものです。本来であればただの音でしかない音声を、「単語列に対してどういう単語が来るか」を学習することで、意味のある文章に変換できるというわけです。そのため、言語モデルは、テキストから得られた情報を活用してASRネットワークのパフォーマンスを向上させる上で重要な役割を果たしてきました。
ただし、言語モデルは通常、ASRネットワークとは別にトレーニングする必要があり、メモリが非常に大きくなる可能性があるため、電話などの小型デバイスには適していませんでした。一方、今回のSpecAugmentを使って訓練されたモデルは、言語モデルの助けを借りなくても、従来の方法よりも高い精度を出すことができています。
最先端のスコア
今回の手法、SpecAugmentをテストするために、LibriSpeechデータセットを使用してエンドツーエンドのネットワークをトレーニングすることによって、提案された方法の評価を行いました。ここでは、音声認識に一般的に使用される3つのListen Attend and Spell(LAS)ネットワークを使用しています。
ASRネットワークのパフォーマンスは、ターゲットスクリプトに対するワードエラー率(WER)によって測定されます。SpecAugmentは、ネットワークやトレーニングパラメータを追加調整することなくネットワークのパフォーマンスを向上させることがわかりました。
 LibriSpeech 960hおよびSwitchboard 300hのタスクの最先端の結果に対するワードエラー率(%)
LibriSpeech 960hおよびSwitchboard 300hのタスクの最先端の結果に対するワードエラー率(%)
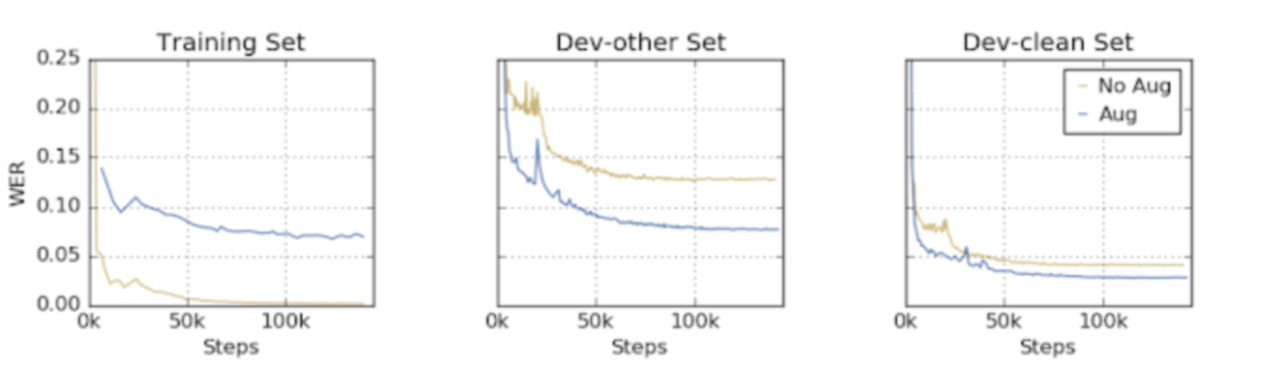
さらに重要なことに、SpecAugmentは故意に破損したデータを与えることによってネットワークがトレーニングデータに過剰に適合するのを防ぎます。この例として、トレーニングセットと開発セットのエラー率が、増強のある場合とない場合のトレーニングによってどのように進化するかを以下に示しています。拡張なしでは、ネットワークはトレーニングセットでほぼ完璧なパフォーマンスを達成しながら、ノイズが少ない開発セットとノイズの多い開発セットの両方で大幅にパフォーマンスが低下していることがわかります。
一方、増強を行うと、両方の開発セットでより良いパフォーマンスを出しています。ネットワークがトレーニングデータに過剰に適合しなくなったこと、つまりトレーニングパフォーマンスの向上がテストパフォーマンスの向上につながることが分かりました。
こうした技術に支えられる自動音声認識モデルは、スマートスピーカーに搭載されるような会話型AIの音声をテキストに変換するような様々な場面で利用されています。誤認識率が低下することで、実際に指を動かしてタイプするよりも早い入力が音声で可能になることが期待できるのではないでしょうか。



この記事に関するカテゴリー






