文字には有益な情報が詰め込まれている!?
ニューラルネットワークを用いた自然言語処理において、一般的に入力として文字や単語が用いられます。しかし、日本語や中国語で用いられる漢字や、韓国語で用いられるハングルには、その文字の中に意味を持つ部分が複数存在しています。近年の自然言語処理では、こうした情報を用いてタスクの学習を行う方法について研究されており、その効果が示されています。この記事では、文字を構成するパーツを用いて自然言語処理を行う試みに関する近年の研究をいくつかご紹介します。
一般的な自然言語処理における入力
まずは、文書分類や機械翻訳、固有表現抽出といったニューラルネットワークを用いた自然言語処理において、テキストをどのように入力しているのかを簡単に整理します。
単語単位
最も一般的な入力単位は単語で、文を単語に分割したのちに各単語に対応する単語分散表現を用意します。
日本語であれば、MeCabなどの形態素解析器を用いた単語分割が主流で、さまざまなタスクにおいて利用されています。たとえば「昨日のお店は最高だった」という文であれば「昨日/の/お店/は/最高/だ/った」といった具合に分割が行われ、各単語に対応した分散表現がニューラルネットワークに入力されます。
単語単位での入力は人間にとっても理解しやすい単位であるため、結果の分析などにおいても非常に扱いやすい入力単位であると言えます。
一方で、単語単位での学習では、推論時(学習済みのモデルを用いて実際に運用する段階)において学習データに含まれていない単語に対処できないという「未知語問題」が発生してしまいます。
例えば「最高」という単語は学習データに含まれるが、「最低」という単語は未知のため推論に失敗していまうといった具合です。学習データに存在しない単語の分散表現は学習ができないため、推論時に初めて現れた単語には適切な分散表現を与えられず、推論性能が落ちてしまうという重大な問題に繋がります。
文字単位
単語単位で発生してしまう「未知語問題」に対処するために、文字単位での入力を用いた学習も提案されています。「学習データに含まれていない単語」は多くあるのに対して、「学習データに含まれていない文字」が推論時のデータに現れることは滅多にありません。そこで文字単位での入力を利用することで、推論時に初めて見た文字列に対しても分散表現を与えることができ、未知の文字列による性能の低下を防ぐことができます。
また、日本語や中国語で用いられる漢字といった表意文字には、アルファベットに比べて多くの意味が詰まっていると考えられます。例えば感情分析の推論において、学習データに存在しない「好感触」という文字列が含まれていたとします。「好感触」という文字列そのものは学習データに存在していないものの、「好」という文字は学習データに多く存在しているため、この文字列がある程度どのような意味なのかを分類器は推測することができます。
sub-文字単位
一部の言語で用いられる文字は、複数のパーツの組み合わせから成っています。例えば我々が使っている漢字も、その多くが複数のパーツから構成されていることは周知の事実です。すなわち、文字単位で入力するよりもさらに細かい入力単位として、文字を構成するパーツを入力とする「sub-文字単位」がありうるということです。これにより、文字単位での入力で捉えきれていない情報がが利用できる可能性があり、こうした文字を用いる言語における自然言語処理の性能向上が期待できます。この記事では、そのような文字として「漢字」と「ハングル」を取り上げ、実際にどのようなアプローチが取られているかを簡単に紹介します。
漢字
論文1:Sub-character Neural Language Modeling in Japanese
論文2:Subcharacter Information in Japanese Embeddings: When Is It Worth It?
漢字の特徴
我々が漢字を理解する上で、部首などのパーツは重要な役割を果たしています。例えば「鯊」という漢字をみたとき、その読みや意味が明確にわからなくても「魚」というパーツから「どうやら魚か魚に関係する何からしい」ということが推測できます。このような漢字の特性に基づいて、漢字をパーツの組み合わせで表現したデータセットが複数存在しています。論文1では「賂」という漢字を例に、既存の四つのデータセットにおける漢字の表現方法を図のように比較しています。こうしたデータセットを利用することで、漢字における「sub-文字単位」の情報を用いた自然言語処理が可能となります。

なお、図で紹介されているデータセットはそれぞれ以下のリンクから利用することができます。
GlyphWiki
IDS
KanjiVG
KRADFILE
手法と評価
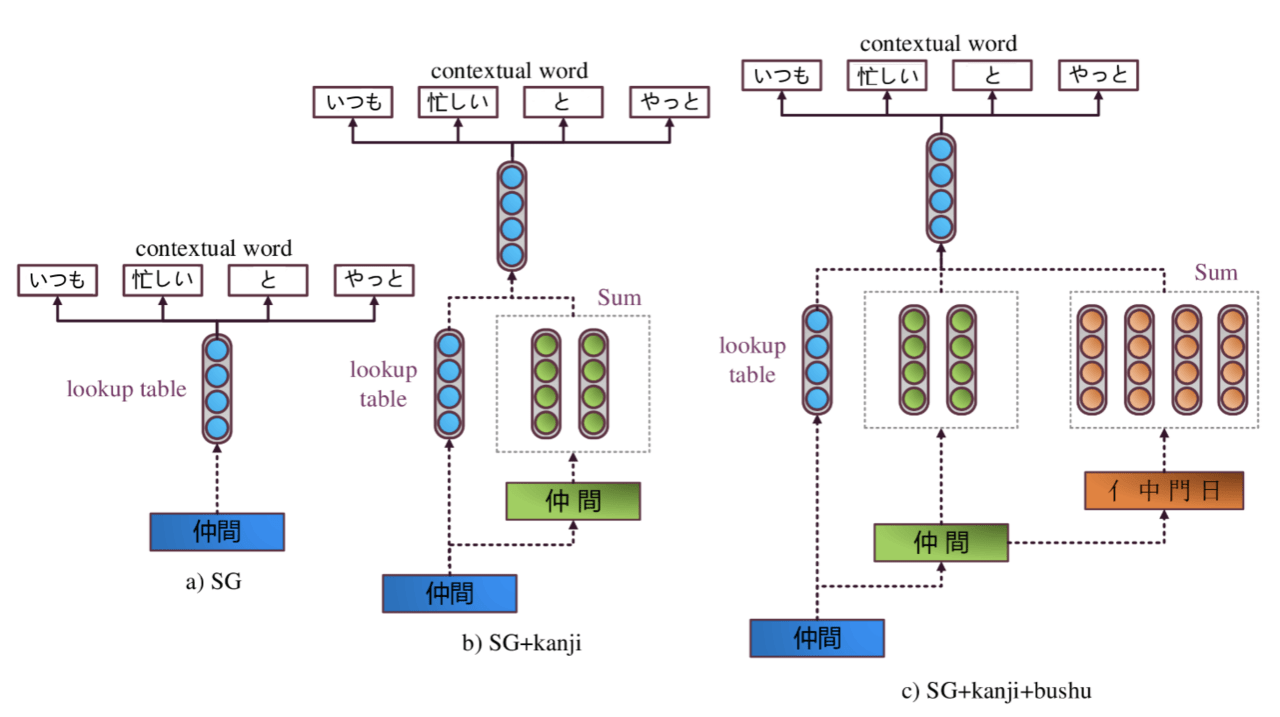
「sub-文字単位」の情報を用いるために、論文2では以下のようなモデルを用いています。図はある単語を入力とし、周囲の単語を当てるSkip-Gramというタスクを解くためのもので、入力である「仲間」という単語にsub-文字情報を足し合わせる単純なモデルを表しています。SG+kanji+bushuというモデル(図右)では、
- 「仲間」という単語単位
- 「仲」「間」という文字単位
- 「人」「中」「門」「日」というsub-文字単位
の全ての情報を足し合わせることで、「仲間」という単語を表現しています。
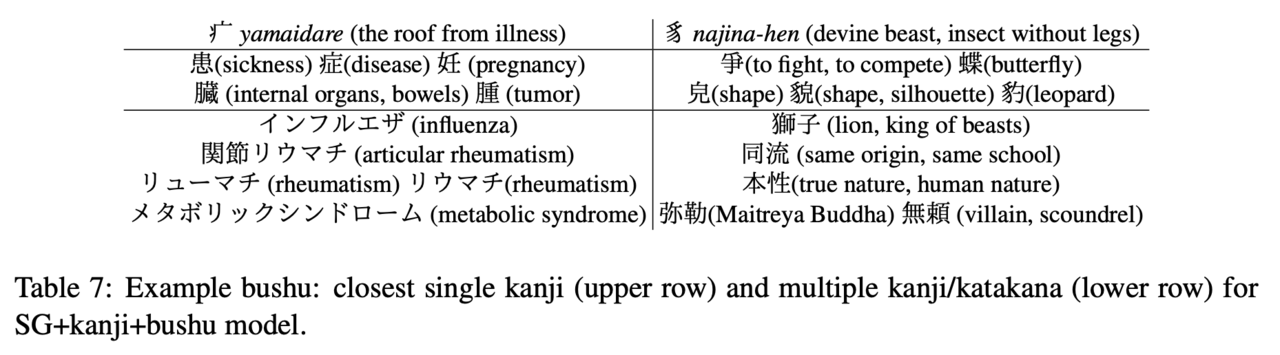
上記のモデルを大規模なコーパスで学習することで、「sub-文字単位」すなわち漢字における部首などの分散表現を獲得することができます。以下の表は、学習された部首の分散表現に近い意味を持つ漢字と単語を列挙したものです。「やまいだれ」の部首は「患」「症」といった病気に関係する漢字と近い意味を持つだけでなく、「インフルエンザ」といった具体的な病名単語とも近い意味を持っていることが学習できているとわかります。同様に、獣などを表す「むじなへん」も、直感的に意味が似ている単語と似た分散表現を獲得できていることがわかります。
ハングル
論文:Subword-level Word Vector Representations for Korean
ハングルの特徴
ハングルは朝鮮語を表記するために用いられる表音文字です。
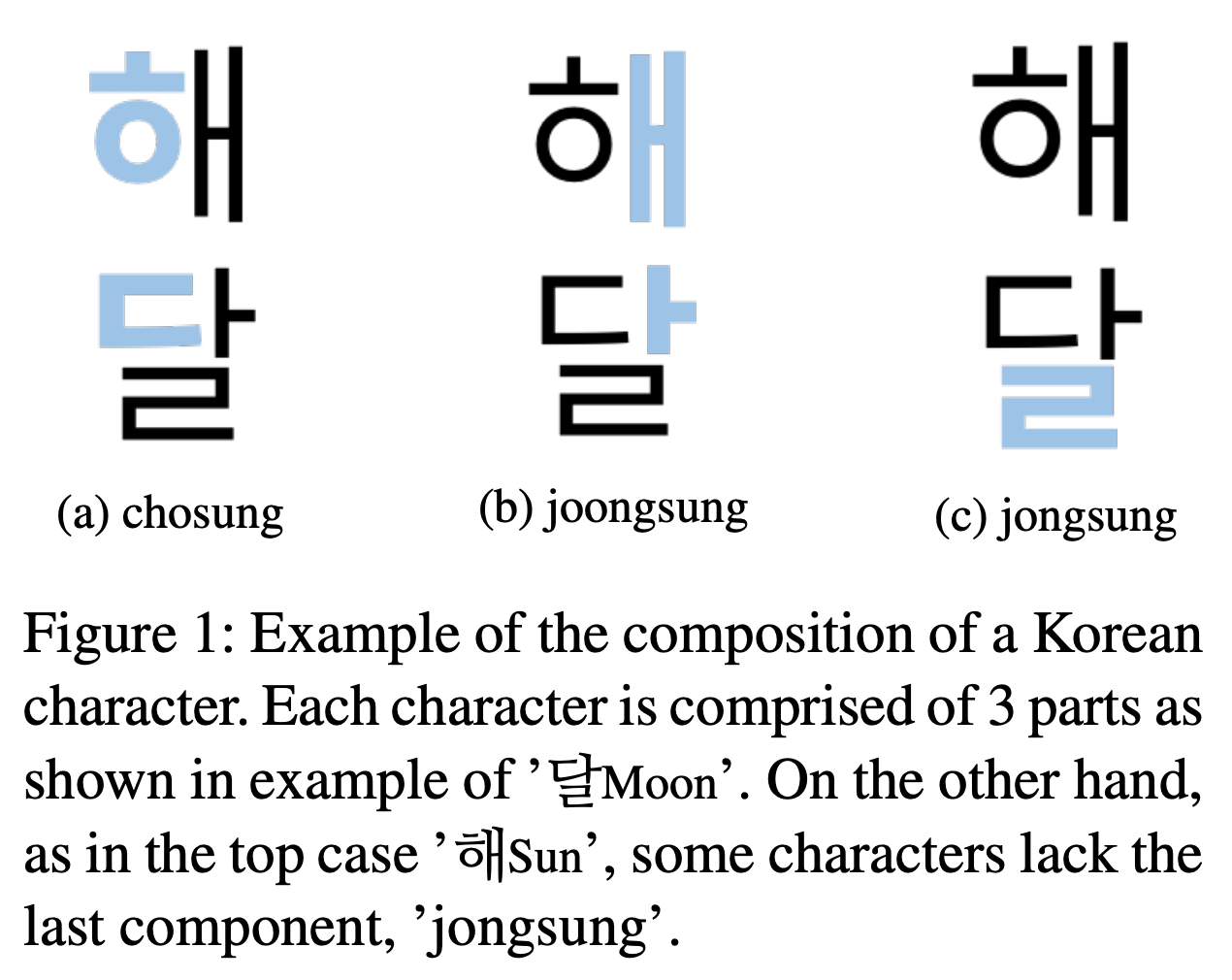
我々が用いている平仮名や片仮名といった表音文字とは異なり、一つの文字が発音記号の組み合わせから成ることが特徴的です。図のようにハングル文字はjamo(字母)と呼ばれる発音を表すパーツの組み合わせでできており、その多くはchosung(初声)・joongsung(中声)・jongsung(終声)の三つから構成されています(ただし終声を持たない文字も多く存在します)。
それぞれの字母が発音を表しているため、ハングルではあらゆる発音を表現することができます。可能な発音パターンは非常に多く、それに対応する文字を作り出すことができるためハングルの文字種は非常に多いと言えます。そこで、字母というsub-文字レベルでの入力を行うことで「エコに」ハングルを表現することができると考えられます。
手法と評価
論文では単純に字母を並べることで、sub-文字単位での入力を試みています。たとえば「먹었다(食べた)」という単語であれば「ㅁ, ㅓ, ㄱ」「ㅇ, ㅓ, ㅆ」「ㄷ, ㅏ, e」という文字ごとに字母を並べたものを入力とします。ここで「다」には終声が存在しないため、終声がないことを表す「e」トークンを利用しています。
さらに韓国語は、日本語のように単語の後ろに活用や格情報をつなげていく膠着言語のため、文字をまたいだ字母の連結によってこうした情報が捉えられると考えられます。そこで上記の文字ごとの字母表現を連結し、単語ごとに「<, ㄱ, ㅏ, ㅇ, ㅇ, ㅏ, e, ㅈ, ㅣ, e, >」と分解するという方法を提案しています。ここで「<」「>」はそれぞれ単語の始まりと終わりを表す特殊な記号です。
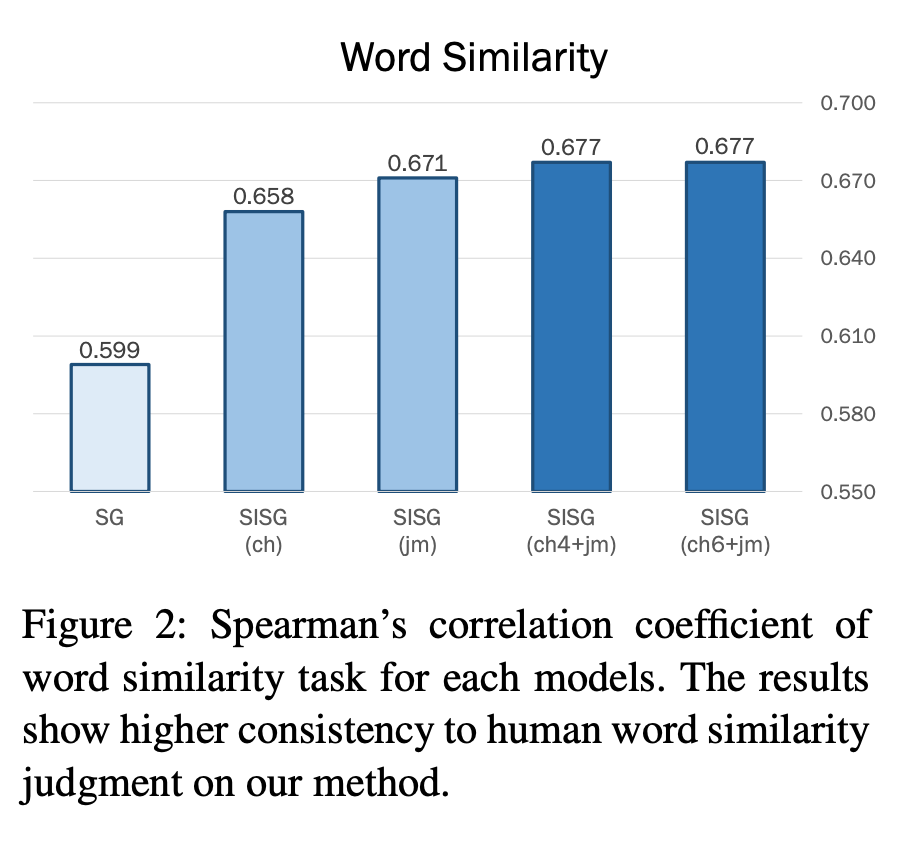
以下のグラフは単語の類似度を当てる「word similarity」というタスクの結果です。単純に単語単位で分散表現の学習を行うモデル(SG)に比べて、文字ごとに単語分散表現を学習するモデル(SISG(ch))によって性能が大きく上がり、さらに字母を用いる(SISG(jm))ことで性能の向上が見られます。このことから、ハングルによるテキストにおいては単語を用いた解析よりも文字単位での解析が有効であり、さらに字母によるsub-文字単位での解析が性能を底上げするということが示唆されています。
まとめ
本記事では、自然言語処理において一般的に用いられる単語や文字といった単位よりもさらに細かいsub-文字単位での解析についての研究を紹介しました。漢字のような表意文字だけではなく、表音文字であるハングルにおいても文字を構成するパーツを用いた解析を行うことで性能の向上が見られています。こうした結果は、世界の話者人口が一位である中国語を解析する上でも非常に役立つと考えられます。全ての言語がアルファベットを用いているわけではないため、こうした言語特有の表記体系を分析し、活用することは自然言語処理をしていく上で重要だと言えます。



この記事に関するカテゴリー






