
AIはツイートからユーザーの所在地を当てられるか
3つの要点
✔️Twitterの投稿(ツイート)からユーザーの所在地を予測
✔️Twitterのメタデータや国と都市の階層性を考慮したモデルを提案
✔️従来手法に比べて高い性能でユーザーの所在地を予測可能
A Hierarchical Location Prediction Neural Network for Twitter User Geolocation
Binxuan Huang, Kathleen M. Carley. EMNLP 2019
ユーザーがどこに住んでいるかという情報、すなわち位置情報は、効果的なマーケティングや災害時の被災状況確認などにおいて重要です。東京に住んでいるユーザーであれば東京付近のトレンドを考慮したマーケティングを行うことで、効率よくユーザーにアピールすることができます。また災害時などは、被災地域のユーザーの画面に表示される広告を避難情報に置き換えるなどの工夫により、緊急時の情報伝達を円滑に行うことが来ます。
一方で、所在地に関する情報は重要な個人情報であり、ユーザーとしては極力公開したくないものであるといえます。サービスの運営者であれば、IPアドレスなどの情報を取得しておおまかな位置情報を確認することができますが、ユーザーの位置情報を活用したい人々の多くはこうしたセンシティブな情報にはアクセスできません。そこで、ユーザーの日ごろのSNSへの投稿から所在地を予測する技術が求められています。
ユーザーが投稿したテキストからユーザーの属性(ここでは位置情報)を予測する研究は、自然言語処理分野で広く扱われています。本記事では自然言語処理の有名な国際学会であるEMNLP2019にて発表された論文で、Twitterの投稿からユーザーの所在地を予測する手法を紹介します。
Twitterのプロフィールはあてにならない
マーケティングなどを目的としてTwitterのユーザーの位置情報を取得しようとした時、プロフィール欄の所在地記入欄を利用する方法が考えられます。Facebookなどの実名SNSであれば、ユーザーは他のユーザーと繋がるために積極的に正しい位置情報を公開しています。
しかし、Twitterのような匿名文化が根付いたSNSのユーザーは、こうした個人を特定しうるような情報を公開しない傾向にあります。特にTwitterのプロフィール欄は自由記述方式であるため、現実には地理情報とは全く関係のない宣伝や一言を記述しているユーザーが多く存在します。そのため、単純にTwitterのプロフィール欄の情報だけを用いてユーザーの位置情報を予測することは困難と言えます。
Twitterの投稿(ツイート)にはGPSによる位置情報を付加することもできますが、匿名性を好むユーザーの多くはこの機能を利用していません。そこで、Twitter上で公開されているプロフィール情報や投稿を総合的に考慮してユーザーの所在地を予測する技術が関心を集めています。
ツイートからユーザーの所在地を予測する
ツイートとユーザー情報を活用するニューラルネットワーク
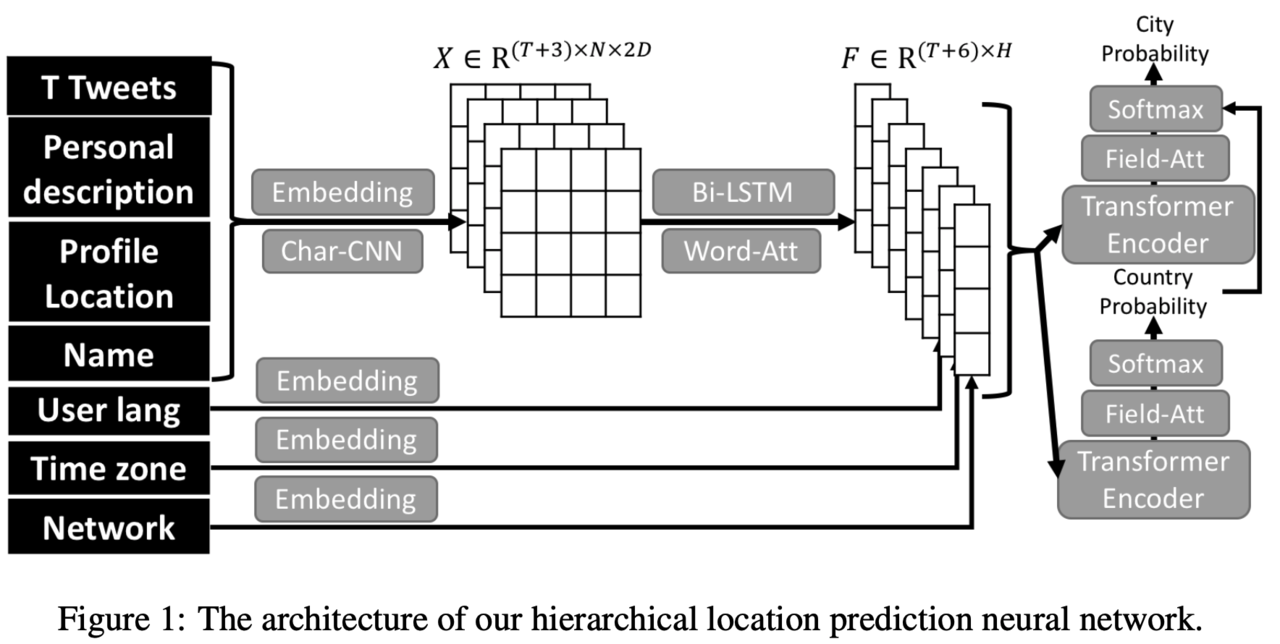
本論文では、Twitter上で利用可能な情報を総合的に考慮してユーザーの位置情報を予測するニューラルネットワークを提案しています。上図は提案手法の外観を示しており、左側がTwitterで利用可能な情報の入力、右側が位置情報(国と都市)の出力となっています。
提案手法では直近T件のTwitterの投稿(Tweet)の他に、自己紹介欄(Personal description)、自由記述の所在地欄(Profile Location)、ユーザーの名前(Name)、使用言語(Lang)、タイムゾーン(Time zone)、メンション情報(Network)を活用し、ユーザーの正しい位置情報の予測を試みます。ここで所在地欄は自由記述方式であるため、上述したとおり多くのノイズを含んでいる可能性があります。
使用言語とタイムゾーンは有限個のラベルとして表現できるため、それぞれの要素に対応する埋め込み表現を学習することができます。例えば使用言語であれば、日本語・英語・中国語などに対応したベクトルを用意し、これを学習することでそれぞれの素性を表現します。
メンション情報はユーザーがどのユーザーに返信機能(リプライ)を使ったかという情報から構築します。これは単純にフォロー・フォロワーの関係を使用するよりも有効であるとされています。メンション情報はネットワーク、すなわちグラフ構造になっているため、グラフ埋め込みのための手法であるLINE1)LINE: Large-scale Information Network Embeddingを使用して学習されたベクトルを利用します。
ツイート、自己紹介欄、所在地欄、名前はそれぞれユーザーが自由に記述することができます。Twitterでは特殊文字や崩した表現などが多く使われているため、単純な単語埋め込みでは未知語が多くなり情報が欠落してしまいます。提案手法では文字情報に対して畳み込みニューラルネットワークを用いることでこの問題に対処し、崩れた表現などから情報を失うことなく情報をベクトルへとエンコードします。エンコードされた情報に対して、さらにBiLSTMと単語レベルの注意機構を用いることで、これらの素性をより豊かに表現できるような設計としています。
最後に、これらベクトルで表現された7つの素性をまとめてTransformerでエンコードし、ユーザーの位置情報である国と都市を予測します。
国と都市の階層性を活用
国と都市の予測は分類問題として解くことができます。上図の右側の出力部分から分かるとおり、提案手法では国と都市を別々に予測しています。例えば図右下のTransformerの計算結果からは「アメリカ」「日本」といった世界に存在する国に対応するラベルから一つ予測し、図右上のTransformerの計算結果からは「ワシントンDC」「東京」といった世界中の都市に対応するラベルから一つを予測します。
この二つのTransformerがそれぞれ独立してラベルを出力する構造だと、国ラベルとして「アメリカ」が予測されているにもかかわらず、都市ラベルとして「東京」が予測されてしまうことがあります。提案手法ではこれを防ぐために、国と都市の階層性を考慮した都市ラベルをを予測できるような工夫を加えています。
具体的には先に国ラベルを予測し、予測された国に含まれる都市の確率が高くなるように都市ラベルの分布を調整することで、この階層性を考慮した予測を実現します。例えば国ラベルとして「日本」が選ばれた時、都市ラベルの分布のうち「東京」「大阪」などのラベルの確率が高くなり、「ワシントン」「ロンドン」などのラベルの確率が低くなるような調整を行います。
実験と結果
提案手法を評価するために、実際のTwitterの投稿から作成された3つのデータセットでの実験を行います。
Twitter-USはユーザーの所在地が北アメリカに限定されたデータセット、Twitter-Worldは世界中のユーザーが含まれるデータセットで、それぞれツイートに付加された位置情報タグを正解ラベルとしてデータセットを作成しています。上述した提案手法の詳細から分かるとおり、正解となる位置情報タグは使用されません。WNUTは世界中のユーザーを対象とした大規模なデータセットで、ノイズの多いテキストを対象としたワークショップ2)2016 The 2nd Workshop on Noisy User-generated Text (W-NUT)にて使用されたものです。
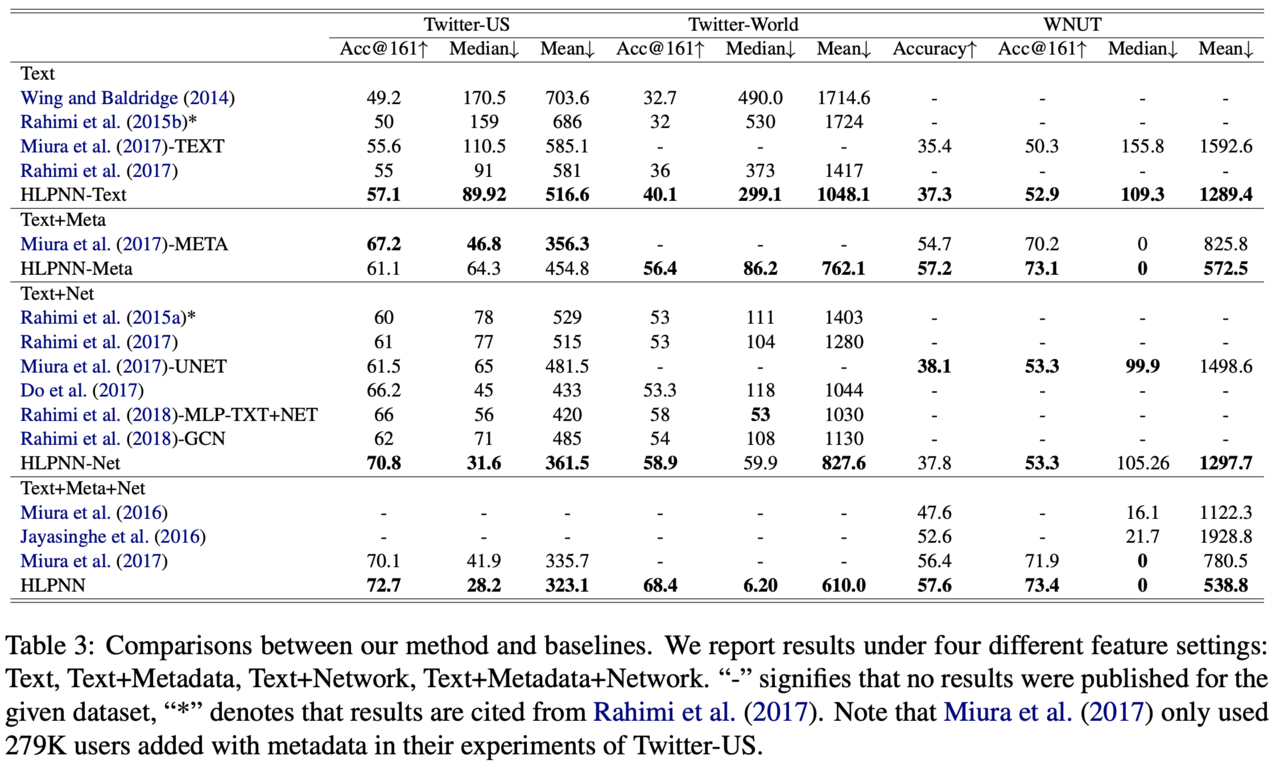
下表は各データセットにおける実験結果を示します。本論文での提案手法は「HLPNN」と表記されており、ツイート情報(Text)、プロフィールやタイムゾーンなどのメタ情報(Meta)、メンション情報(Net)のそれぞれの素性を用いたモデルについて比較されています。評価にはAcc@166という指標が用いられており、これは予測したラベルが正解の都市の半径161km(100マイル)以内であれば正解とみなす指標です。
表より、提案手法は既存研究に比べて高い精度でユーザーの位置情報を予測できていることがわかります。また、どの手法もメンション情報(Net)を利用することで性能が大きく向上することが分かります。このことから、ユーザーの位置情報を予測するうえで「誰とつながっているか」が重要な手がかりとなることが示唆されます。
まとめ
本記事ではTwitterの情報からユーザーの位置情報を予測する研究についてご紹介しました。投稿内容やプロフィールなど、公開された限られた情報からユーザーの位置情報を予測する試みは挑戦的である言えます。実験の結果より、ユーザーが誰とつながっているかを示すメンション情報が位置情報の特定において重要な素性となることが示されました。
現在の技術では、100マイルの誤差を許せば7割程度の精度でユーザーの所在地を特定することができます。ニューラルネットワークを用いたSNSに関する研究は盛んに行われており、今後もこの予測性能が上がっていくと期待されます。また、人手でユーザーの所在地を特定する場合には、投稿された画像や動画が重要な情報となるため、画像処理の分野の進展に合わせて位置情報予測の性能も向上していくと考えられます。
何気なく投稿したツイートが重要な素性となって、自分の詳細な位置情報がAIにバレてしまう、という日も遠くないのかもしれません。
References
| 1. | ↑ | LINE: Large-scale Information Network Embedding |
| 2. | ↑ | 2016 The 2nd Workshop on Noisy User-generated Text (W-NUT) |



この記事に関するカテゴリー






