
YesBut: The Emergence Of A Dataset That Makes The VLM Understand Irony And Caricature!
3 main points
✔️Proposed "YesBut" multimodal dataset for evaluatingsarcasmunderstanding
✔️Evaluates Vision-Language models on three tasks: detectingcaricatures, understanding, and creating finished products
✔️ Identified limitations in understanding sarcasm even with state-of-the-art models and identified room for performance improvement
YesBut: A High-Quality Annotated Multimodal Dataset for evaluating Satire Comprehension capability of Vision-Language Models
written by Abhilash Nandy, Yash Agarwal, Ashish Patwa, Millon Madhur Das, Aman Bansal, Ankit Raj, Pawan Goyal, Niloy Ganguly
(Submitted on 20 Sep 2024)
Comments: EMNLP 2024 Main (Long), 18 pages, 14 figures, 12 tables
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
code:
The images used in this article are from the paper, the introductory slides, or were created based on them.
Summary
Satire is a type of humor that criticizes people, society, and politics through irony and exaggeration, and is a powerful tool for raising issues and encouraging critical perspectives. Satirical images, especially on social media, are frequently posted to express irony and humor by presenting contrasting scenarios. However, understanding these contrasting scenarios requires the interaction of objects in the image, and in some cases the text, as well as common sense and reasoning skills.
Previous research has proposed methods for detecting humor and sarcasm in text, images, or a combination of the two, but has not comprehensively evaluated sarcasm across multiple tasks, such as "detecting," "understanding," and "creating a finished product.
In this paper, three tasks are set up to assess the comprehension of satire: 1:
1. caricature detection: This task determines whether a given image is a satire. This task is treated as a binary classification problem.
2. understanding satirical images: This task involves explaining in natural language the content and ironic points of satirical images. The model should describe each sub-image and explain why it is funny/ironic.
3. Creating the finished caricature: Given a portion of an image, choose from two options the other image that completes the caricature.
The study created a "YesBut" dataset containing 1,084 satirical and 1,463 non-satirical images, each containing two subimages of different artistic styles. The satirical images create humor and irony by having the left subimage show a normal scenario and the right subimage depict an ironic situation that goes against it.
As a result, the state-of-the-art Vision-Language models are not performing as well as expected on these satire tasks. In particular, for "satire image detection," even the best models have an accuracy rate of less than 60%, indicating that there is still significant room for improvement in understanding satire and humor.
This study not only provides a new data set and task for assessing satire comprehension, but also highlights the need for further improvement of the Vision-Language model in the future.
Explanation of Figures and Tables
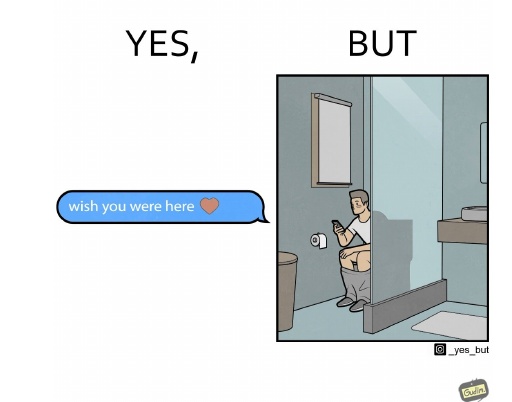
The diagram expresses humor and sarcasm in the form "YES, BUT". On the left side is a message app callout with the message "wish you were here" (wish you were here). This is a phrase that generally conveys a touching and warm sentiment.
However, if you look at the image on the right, you will see that the person sending the message is sitting on the toilet. This contrast creates irony and enhances the fun. The gap between the action in the personal and somewhat funny situation of the toilet and the touching message is a source of humor.
Such a format is a satirical display of cultural themes concerning contemporary means of communication and personal privacy.
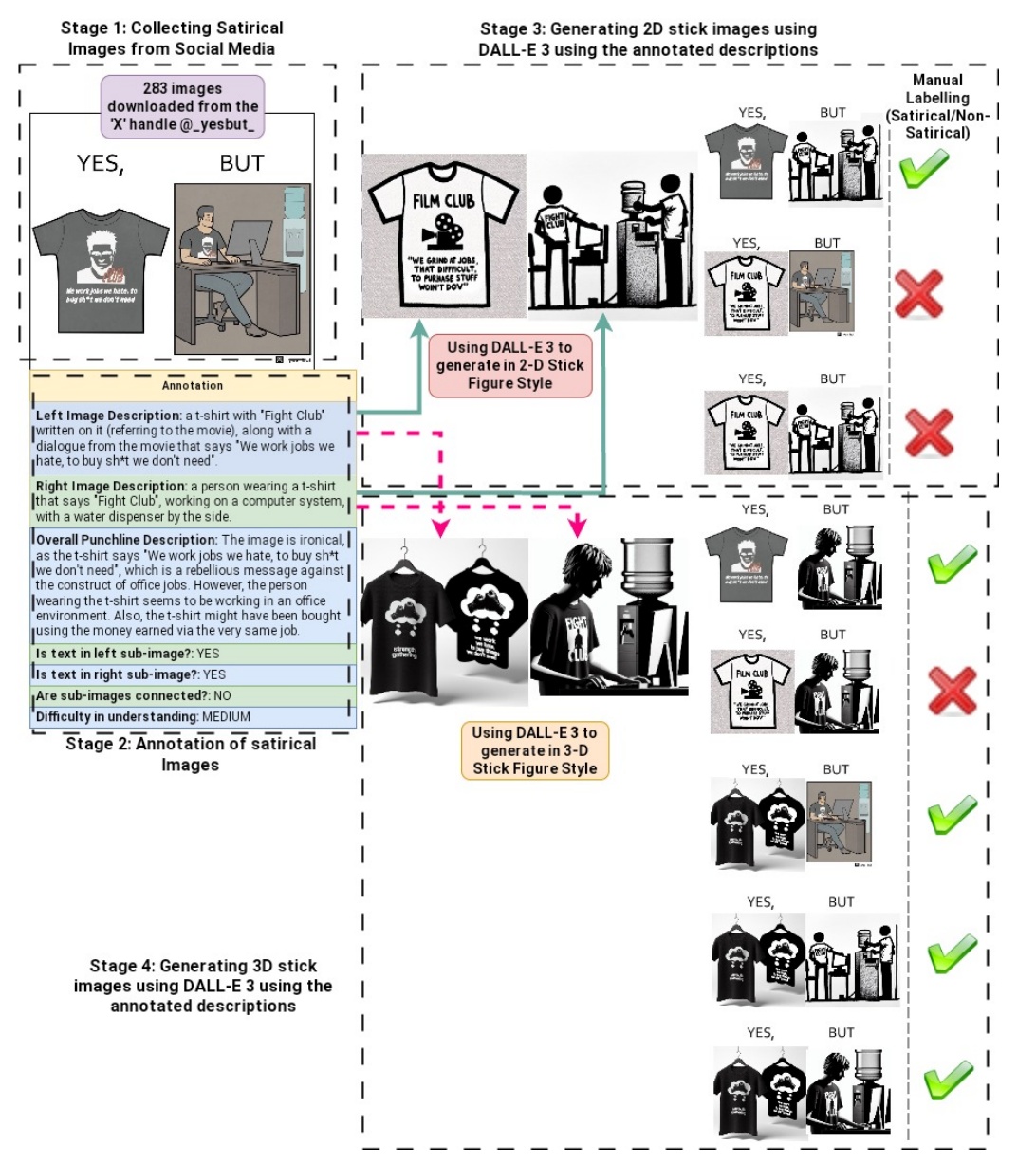
This diagram illustrates the process of collecting and generating satirical images in four stages.
Stage 1: Gathering from Social Media
- 283 images are collected from social media. At this stage, images with the theme "YES, BUT" are featured.
Stage 2: Annotation of satirical images
- Detailed annotations can be added to the collected images.
- The image description at left includes a T-shirt labeled "Fight Club" and dialogue from that film.
- The image description at right shows a person wearing a T-shirt with "Fight Club" on it operating a computer near a water dispenser.
- The satirical description of the entire image underscores the irony of this figure. The image conveys the message that we work jobs we hate and buy things we don't need.
Stage 3: Generating 2D stick images using rendering
- Using DALL-E 3, an image is generated in the style of a 2D stick figure based on the annotation.
- The generated images are manually classified and labeled as satirical or not. Images with the correct label will be marked with a green check.
Stage 4: Generation of 3D stick images
- Similarly, using DALL-E 3, images are generated in 3D stick figure style.
- Artifacts are manually classified and properly labeled as in 2D.
In the process, images are generated in a variety of styles and approaches, showing how elements of satire are expressed.
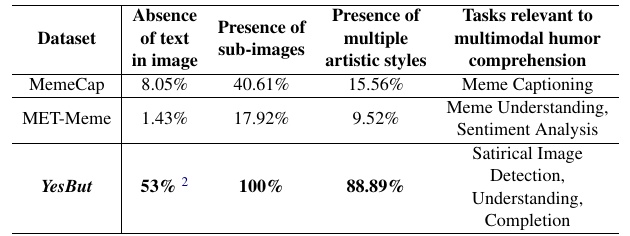
This chart compares the characteristics of the different datasets and their uses. The three datasets, "MemeCap," "MET-Meme," and "YesBut," are described from the following four perspectives
1. presence or absence of text in the image:.
- 8.05% of the images in "MemeCap" and 1.43% in "MET-Meme" have no text.
- YesBut" indicates that 53% of the images have no text.
- Images without text should convey meaning and humor through the image alone.
2. with/without sub-images
- 40.61% of the images in "MemeCap" and 17.92% in "MET-Meme" have sub-images.
- In "YesBut" all images contain sub-images.
3. the existence of various artistic styles
- 15.56% of images in "MemeCap" and 9.52% in "MET-Meme" have multiple artistic styles.
- In "YesBut," 88.89% of the images have this feature. This feature is notable as an element that enriches the expression of humor and satire.
4. tasks related to multimodal humor comprehension: 1.
- MemeCap" is mainly used for "Meme caption generation.
- MET-Meme focuses on "Meme Understanding" and "Emotional Analysis.
- YesBut" is used for tasks such as "satirical image detection," "understanding," and "completion.
From this table, it is clear that the "YesBut" dataset is designed to evaluate humor and satire from multiple perspectives.
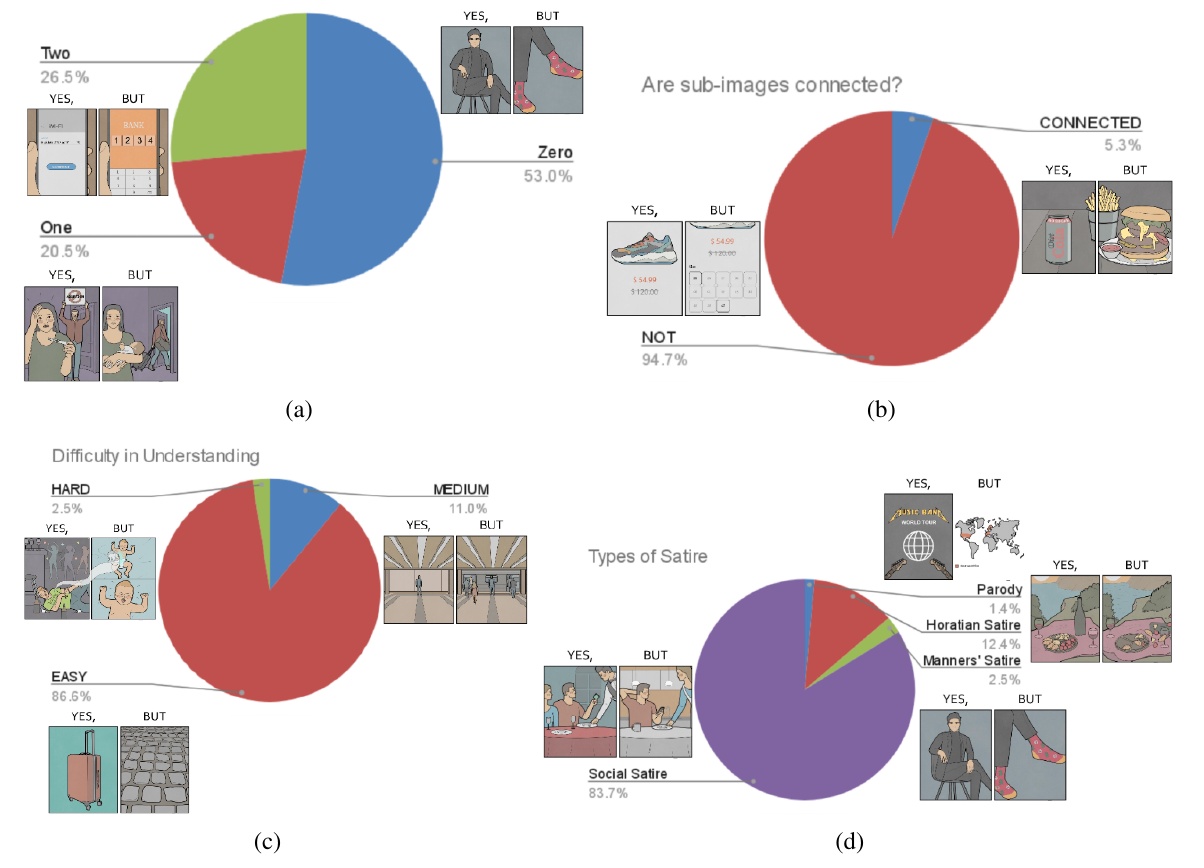
This chart analyzes the characteristics of satirical images from four different aspects.
(a) The first pie chart shows the number of subimages. Zero" accounts for 53.0%, which is a typical pattern used in satire, depicting two subimages, which do not appear to be related. Other categories such as "One" and "Two" are also present, but show smaller numbers.
(b) Next is a pie chart of subimage connectivity. NOT" accounts for 94.7%, indicating that the majority of images are not directly connected between sub-images. In contrast, "CONNECTED" accounts for only a small percentage.
(c) The graph shows the difficulty level of understanding sub-images. With "EASY" at 86.5%, it is clear that most images are relatively easy to understand. Only a few images have a high degree of difficulty, such as "MEDIUM" and "HARD.
(d) Finally, the graph shows the type of satire. Social Satire" is the predominant type of satire at 83.7%, indicating that social satire is the predominant type of satire. Parody" and "Horatian Satire" are at 14% and 12.4% respectively, while "Manners' Satire" is very rare.
These statistics are a visual representation of the different satirical styles and the diversity of elements contained in them.
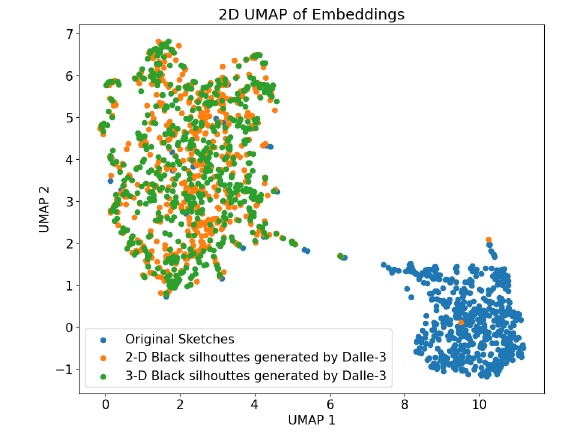
This figure shows a two-dimensional visualization of data distribution using a technique called UMAP (Uniform Manifold Approximation and Projection), which is one of the methods to compress high-dimensional data into lower dimensions.
Different colored dots in the figure indicate different types of images.
- The blue dots represent Original Sketches. These are the original images and are the basis used for the study.
- The orange dots indicate "2-D Black silhouettes generated by Dalle-3. These are 2-D silhouettes generated by the Dalle-3 artificial intelligence model.
- The green dots indicate "3-D Black silhouettes generated by Dalle-3. These are also 3D silhouettes generated by Dalle-3.
This figure shows how the original sketches and the AI-generated images differ and how diverse they are. In particular, the original sketches form clusters that differ from the rest of the data set, suggesting that they have different characteristics. This is the basis for assessing how well the model can distinguish between different styles of images.
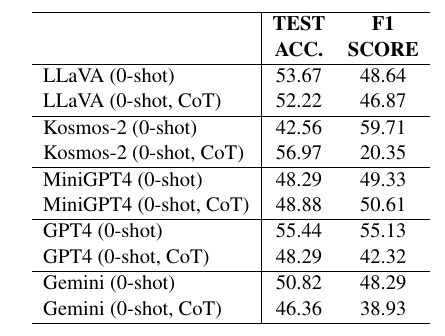
This table shows the performance of several Vision Langage Models (VL models) on the "Detect Satirical Images" task. This task identifies whether a given image is satirical or not.
- LLaVA: This was performed in both "Zero-Shot" and "Zero-Shot Chain-of-Thought (CoT)" settings. Zero-Shot is a setting where the model processes the task immediately without additional learning or context. With a "Test Accuracy (TEST ACC.)" of 53.67% and an F1 score of 48.64, there is a slight decrease in the CoT setting.
- Kosmos-2: The zero shot CoT setting shows the best results with a test accuracy of 56.97%. This suggests that the coordinated inference is working.
- MiniGPT-4: This model has an accuracy in the 48th percentile for both settings, with a slight variation in F1 scores, but no dramatic improvement.
- GPT-4: 精度とF1スコアが約55%で、他のモデルと比較して中庸なパフォーマンスを示しています。CoTの設定では精度が低下しています。
- Gemini: This model shows slightly lower performance than the others, with even lower accuracy in the CoT setting.
Overall, we find that each model responds differently to the task of understanding the satiric nature of the pictures, and in particular that CoT reasoning does not necessarily improve performance in all cases. While there are differences in performance across models, the overall results suggest that there is still room for improvement.
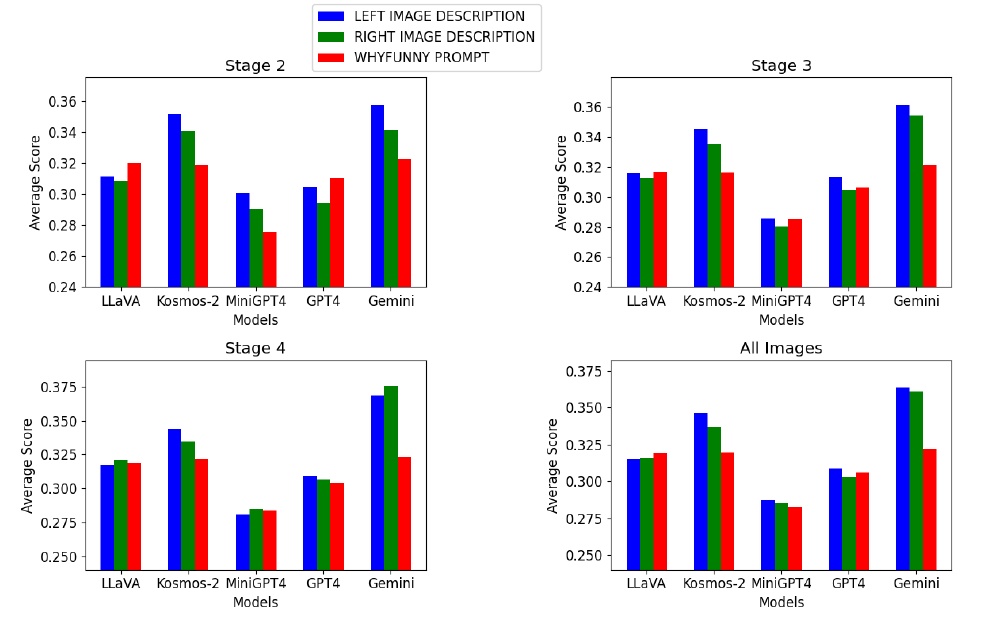
This figure shows how effectively different models can understand satirical images at different stages within the "YesBut" data set. Evaluations are made through the left-hand image description, the right-hand image description, and at the "WHYFUNNY" prompt.
- The top two graphs show the evaluation results for Stage 2 and Stage 3. Five models are compared here: LLaVA, Kosmos-2, MiniGPT4, GPT4, and Gemini. For each model, the average scores for the three evaluation criteria are shown.
- The two graphs at the bottom show the results for Stage 4 and all images. This allows a visual comparison of how each model performs at the various stages.
At a glance, one can see that the Gemini model is rated higher than the others in all stages. In particular, it scores higher in Stage 3 and Stage 4, indicating its superior ability to understand the satire of the image.
Conversely, MiniGPT4 scores relatively lower than the other models, suggesting challenges in understanding satire at certain stages.
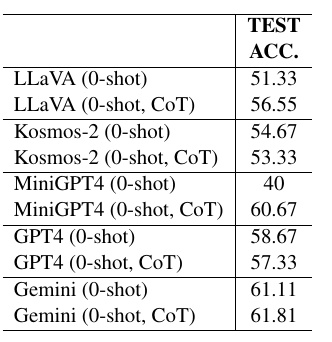
This chart shows the performance of various Vision Language (VL) models in the task of "Satirical Image Completion." Specifically, it compares the test accuracy (precision) of each model in the "Zero-Shot" and "Zero-Shot CoT (Chain-of-Thought)" settings.
1. model overview: 1.
- LLaVA: This model has an accuracy of 51.33% at zero shot and 56.55% at zero shot CoT.
- Kosmos-2: 54.67% accuracy for zero shot and 53.33% for zero shot CoT.
- MiniGPT4: This model has a zero shot accuracy of 40%, but a much better zero shot CoT of 60.67%.
- GPT4: This one has an accuracy of 58.67% for zero-shot and 57.33% for zero-shot CoT.
- Gemini: shows the highest accuracy, 61.11% for zero shot and 61.81% for zero shot CoT.
2. trend of results: (1)
- Many models show improved accuracy with zero-shot CoT. The exception to this is Kosmos-2, which shows a slight decrease in accuracy with zero-shot CoT.
- Overall, Gemini shows the highest accuracy. This suggests Gemini's superior performance in complex tasks.
3. applicability:models with high accuracy demonstrate the ability to understand images in specific contexts and find common patterns, allowing for integrated visual and verbal processing.

This image is an example of humor and irony. It is divided into two parts: "YES" and "BUT."
In the "YES" section on the left, a fire extinguisher is indicated. The extinguisher is labeled "FOAM," indicating that it is for oil or flammable liquid fires and cannot be used for electrical fires. In the background, a waterscape can be seen, and the situation is peaceful itself.
When it comes to the "BUT" section on the right, a sliding door-like grate is placed in front of the fire extinguisher, suggesting that access is restricted when one actually tries to use it. This grating ironically represents a situation in which the fire extinguisher cannot be quickly removed.
The contrast between the two images humorously depicts a situation in which a fire extinguisher is visually placed in an accessible location but is actually difficult to use. It can also be interpreted as a satire of social systems and situations that seem to work well on the surface but do not in reality.
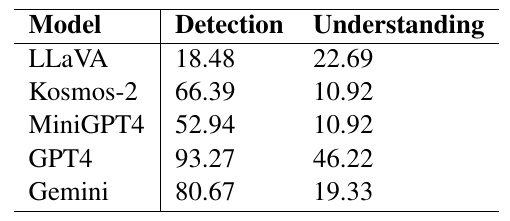
This figure is a table showing the performance of several models. It shows how well (in percentage) each model was able to tackle two specific tasks.
- Detection" presumably refers to the task of finding specific elements in images or data, and is an assessment of how well the model performed it.
- Understanding" indicates how deeply one understands and grasps the meaning of given information.
Looking at the results for each model, GPT4 scores very high with 93.27% for detection and 46.22% for comprehension. Next best is Gemini, with 80.67% for detection and 19.33% for comprehension.
The other models score in the low 10% range, especially in comprehension, suggesting that there is still room for improvement in deeper understanding of the data; Kosmos-2 and MiniGPT4 perform moderately well in detection, but similarly score in the 10% range in comprehension.
What we can see from this table is that each model has areas where it is good at different tasks and areas where it needs improvement. In particular, GPT4 excels in both tasks, while the other models show variability in detection and comprehension.

This image consists of two panels with "YES" on the left and "BUT" on the right.
- The left panel shows a hand pulling out a sheet of tissue paper. This shows normal behavior.
- The right panel shows many tissue papers being pulled out at once. This one represents an unexpected result.
This creates irony and humor. This image symbolically represents a situation in which simple actions often produce disappointing results.
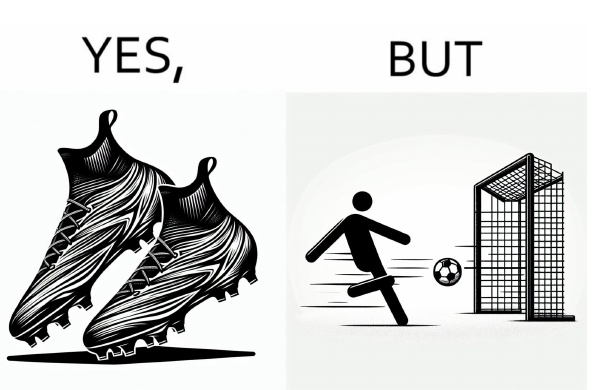
This image is a visual representation of a joke about soccer. On the left side of the image is a soccer shoe with the word "YES" written on it. This indicates that the player is ready to play soccer. On the right side, on the other hand, a stick figure kicking a goal is depicted and the word "BUT" is written. This suggests that the play did not go as intended or that an event occurred contrary to the expected outcome.
This humorous depiction of the gap between expectations and reality provides laughter and mild surprise to the viewer. Such charts are not only useful for literacy, but are also used to provide a satirical view of social situations.

In this diagram, two different scenarios are depicted. The "yes, but" format is used for each set, with opposing ideas shown in between.
In the figure on the left, (A) and (B) are presented. (A) depicts a large question mark, while (B) shows a fireplace flame on a TV screen mounted on the wall. This combination makes the pseudo fireplace look interesting through the TV screen, unlike the actual fireplace.
The figure on the right also shows (A) and (B). In (A), the traffic light is red and there are many people standing around. In (B), a question mark is placed. These contrasts may indicate a contradiction where the signal does not change.
This use of the "yes, but" format is designed to visually highlight the conflict and irony.

This image is intended to express humor or satire. The word "YES," is written in the upper left corner and the word "BUT" can be seen in the upper right corner.
Image (A), below left, is a simple, diagrammatic illustration of a fireplace surrounded by a fire. It represents a typical fireplace scene with people warming themselves.
Image (b), below right, is a picture of a gorgeous fireplace, beautifully stacked with firewood. However, this fireplace is not a real flame, but an image projected on a TV screen.
The satirical element that this entire diagram illustrates is the irony of real and apparent warmth. The contrast between the warmth of a real fireplace and an electronic fireplace as mere decoration is humorously emphasized.
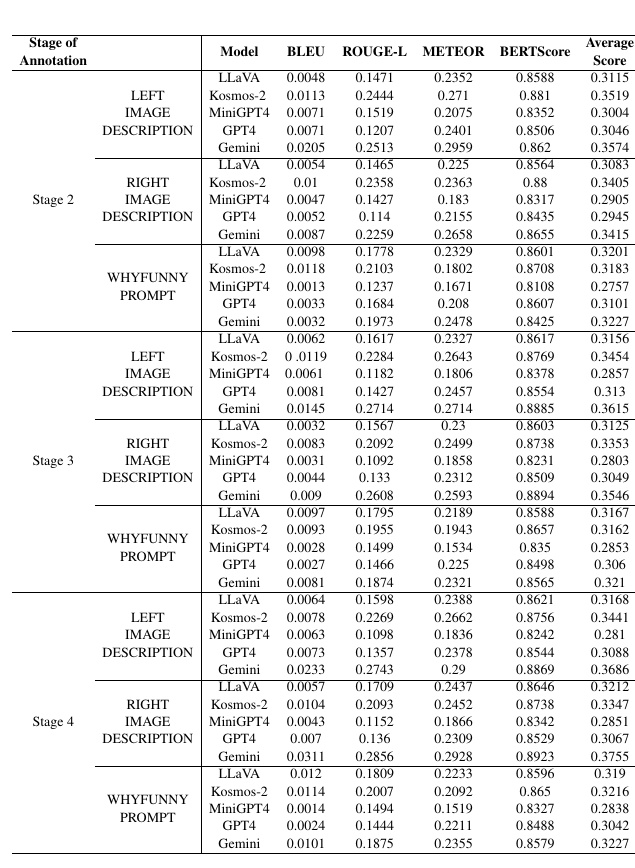
This figure shows the results of the metrics used to assess the ability of different models to comprehend satirical images in the YesBut data set. The following details are explained below.
1. evaluation stage:The dataset is divided into three distinct stages. In each stage, the model attempts to understand the sub-image descriptions and satire of the images provided.
2. models:Several models are included in the figure: LLaVA, Kosmos-2, MiniGPT4, GPT4, and Gemini.
3. evaluation metrics
- Automatic evaluation metrics such as BLEU, ROUGE-L, METEOR, and BERTScore are used to assess the quality of the sentences generated by the model.
- Each metric measures the similarity between the model-generated text and the reference text.
4. summary of results:.
- There are tasks such as "LEFT IMAGE DESCRIPTION", "RIGHT IMAGE DESCRIPTION", and "WHYFUNNY PROMPT" at each stage.
- Scores for each metric are shown, and these scores quantify the performance of the model.
5. Average Score:Finally, the average score for each task as a whole is shown as "Average Score. This is a measure of the overall performance of the model.
Through this chart, we compare and evaluate how well different models understand and explain satire. Different models produce different results, showing which models can understand satire more effectively.
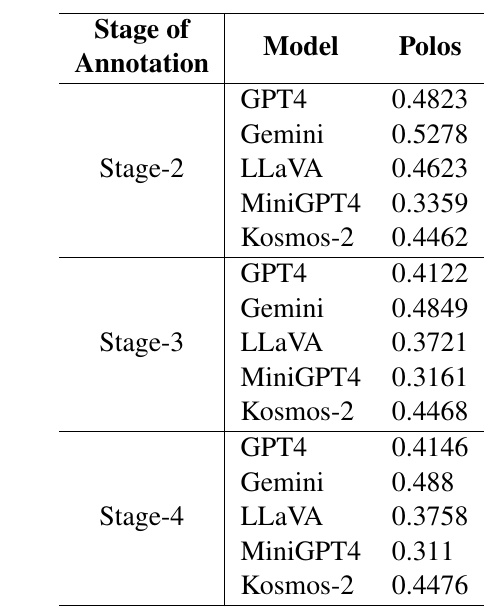
This table evaluates the performance of different models in different phases. The evaluation indicator "Polos" is a numerical representation of the model's performance in a particular task.
Stage-2: The
- With a GPT4 score of 0.4823, performance is average compared to other models.
- Gemini shows the highest score at 0.5278.
- LLaVA is 0.4623, slightly lower than the other models.
- MiniGPT4 has the lowest score at 0.3359.
- Kosmos-2 scored in the middle of the pack with a score of 0.4462.
Stage-3: The
- The GPT4 score dropped to 0.4122.
- Gemini still maintains a high score of 0.4849.
- LLaVA has a low performance of 0.3721.
- MiniGPT4 continues to be low, at 0.3161.
- Kosmos-2 scored 0.4468, almost identical to the Stage-2 score.
Stage-4: The
- The GPT4 score is slightly higher at 0.4146.
- Gemini again shows a high performance of 0.488.
- LLaVA is 0.3758, with stable results.
- MiniGPT4 remains a low score at 0.311.
- Kosmos-2 is consistent and has recorded 0.4476.
Overall, Gemini shows consistently high performance at all stages; MiniGPT4 shows the lowest scores at all stages, showing a difference from the other models. These numbers indicate differences in model comprehension and performance at the progression stages of a particular task.
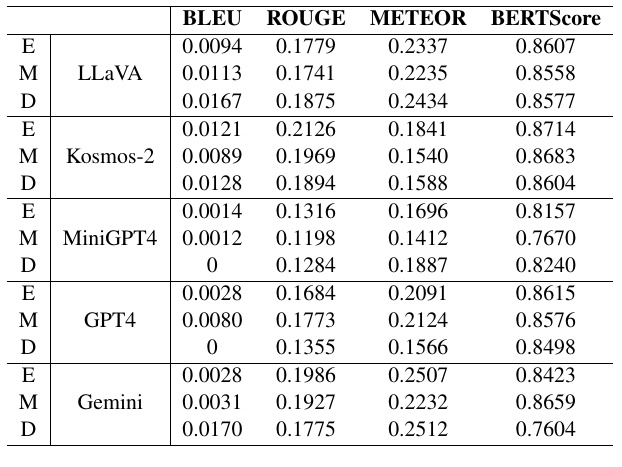
This table shows how well several models perform on the text generation task. The performance of each model is evaluated on datasets of different difficulty levels (EASY, MEDIUM, and DIFFICULT). The four indicators used are BLEU, ROUGE, METEOR, and BERTScore. Each of these indicators is used to evaluate how close or semantically similar the generated text is to the original text.
- BLEU measures the n-gram agreement between the generated text and the reference text. A higher value indicates a better match with the original text.
- ROUGE is a metric often used, especially in summarization tasks, to evaluate the degree of agreement between the generated text and the reference text.
- METEOR is a measure of agreement that includes consideration of word changes and synonyms.
- The BERTScore is a score for checking semantic similarity using a pre-trained model called BERT.
In the table, it is shown how each model scores on each difficulty level (E/M/D). For example, the LLaVA model has a BLEU score of 0.0094 for the EASY data set and 0.0167 for the DIFFICULT data set. This indicates that as the difficulty level increases, the accuracy of this model's generation changes.
The other models, Kosmos-2, MiniGPT4, GPT4, and Gemini, are evaluated in a similar manner, showing performance based on their respective metrics. Through these evaluations, it is possible to compare which model shows the best performance for the selected task and data set conditions.

This image expresses satire by comparing two scenes. The image on the left depicts an ordinary chair. At first glance, it shows a normal scene. The image on the right depicts a person taking a selfie in a mirror while sitting on a toilet. The juxtaposition of these two moments creates irony and humor by emphasizing that the person is in an interesting situation instead of sitting in an ordinary chair. Thus, the contrast between the two scenes skillfully depicts a satire of self-expression and lifestyles in contemporary society.
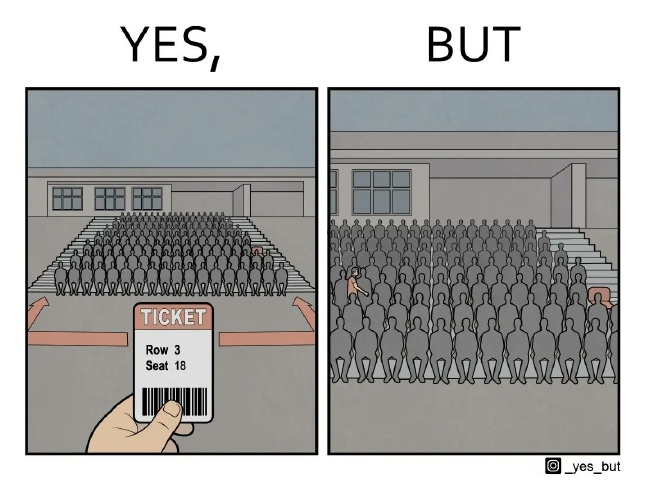
This figure shows a person holding a ticket and the resulting situation. In the image on the left, a ticket is shown held in the hand. On it is written "Row 3, Seat 18," which depicts a designated seat in the audience. The auditorium is nearly full, and arrows can be seen indicating how to get to the seating area.
The image on the right, on the other hand, depicts the same audience scene. You can see a figure trying to make it to the middle of the row and having to pass in front of everyone because the seats are filled. This arrangement ironically illustrates the tediousness of people having to pass through a full house.
Thus, it humorously depicts the contradiction of a situation in which the presentation of a ticket should allow one to reach one's seat without problems, but in reality one has to wade through many people to get there.

This image is a satire using the contrast between "yes" and "but". The person on the left has expertise in many scientific disciplines (astronomy, mathematics, physics). However, he has no knowledge of TikTok. On the other hand, the person on the right has a very high level of expertise in TikTok, but no expertise in other scientific fields.
This comparison is a satirical representation of the way expertise is valued in today's society. In particular, it implies that the influence of social media may be evaluated as an expert. This situation of being evaluated by different standards creates an element of humor and satire in the image.
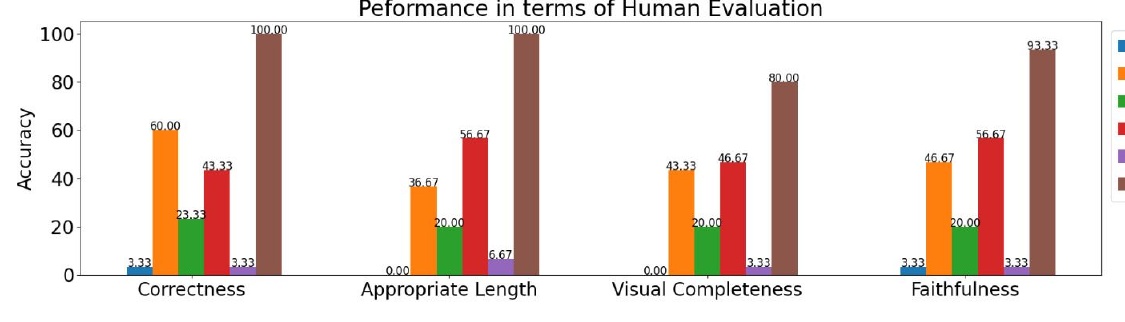
This figure shows a comparison of performance based on human evaluations. The four evaluation criteria are accuracy, adequate length, visual completeness, and fidelity.
1. for accuracy, the bar shown at the top of the figure indicates that one model or method achieves 60% accuracy. On the other hand, other methods show much lower accuracy in comparison.
2. regarding the appropriate length, the best methods reached 100%, but some methods lacked a certain length, which affected some of the evaluations.
3. for the visual integrity item, the best method reaches 80%, while the other methods are lower, with extremely low values observed for some.
4. Regarding fidelity, the best method shows 93.33%, while other methods do not reach this figure. However, some of them show more than 50%, ensuring a certain degree of reliability.
The figure as a whole shows that there are clear differences between the different evaluation criteria. The results are intended to provide an intuitive understanding of how well a particular model or method performs on various criteria.

This table compares the interpretations of humans and different models for a given image.
1. human description:indicates that a person with high expertise in TikTok is more important than a person with high expertise in other areas. Here, the number of microphones indicates the importance of the person.
2. LLaVA:A man with a purple mohawk and glasses is surrounded by microphones and the phrase "expert, astronomy" appears above. He states that this arrangement creates a funny and ironic situation and represents the absurdity of labels and assumptions based on people's appearances and stereotypes.
3. kosmos-2:Describes an older man asking a young masked man questions in front of a microphone. States that the older man's knowledge is being treated in a sarcastic manner.
4. GPT4:states that it exaggerates the difference between two people's expertise in different fields, thereby causing a strange situation.
5.MiniGPT4:Description is incomplete and not detailed.
6. Gemini:states that it shows the contrast between a person with expertise speaking in esoteric jargon and a less knowledgeable person speaking in a general, familiar way.
This comparison suggests that there are significant differences in image interpretation among the models.



Categories related to this article





