
Introduction To Kubric, A Large-scale Data Generation Library
3 main points
✔️ The quality of a machine learning model is the quality of the data.
✔️ Data synthesis can avoid issues such as detailed annotation assignment, removal of sampling bias, and legally secure data collection.
✔️ Kubric is a Python library that can perform data generation useful for many tasks.
Kubric: A scalable dataset generator
written by Klaus Greff,Francois Belletti,Lucas Beyer,Carl Doersch,Yilun Du,Daniel Duckworth,David J. Fleet,Dan Gnanapragasam,Florian Golemo,Charles Herrmann,Thomas Kipf,Abhijit Kundu,Dmitry Lagun,Issam Laradji,Hsueh-Ti(Derek)Liu,Henning Meyer,Yishu Miao,Derek Nowrouzezahrai,Cengiz Oztireli,Etienne Pot,Noha Radwan,Daniel Rebain,Sara Sabour,Mehdi S. M. Sajjadi,Matan Sela,Vincent Sitzmann,Austin Stone,Deqing Sun,Suhani Vora,Ziyu Wang,Tianhao Wu,Kwang Moo Yi,Fangcheng Zhong,Andrea Tagliasacchi
(Submitted on 7 Mar 2022)
Comments: 21 pages, CVPR2022
Subjects: Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR); Machine Learning (cs.LG)
code:
The images used in this article are from the paper, the introductory slides, or were created based on them.
summary
Have you heard the term "data-driven" in recent years? This means "data-driven" or "data-driven and driven," indicating that "the quality of data is more important than machine learning methods in determining results. As a result of the explosive popularity of machine learning and the various research and development efforts conducted by universities and companies, it has become clear that data quality is critical to model accuracy.
However, it is difficult to collect and store quality data, i.e., data whose annotations are detailed and accurate, free of bias, well-organized, and legally secure.
Data synthesis, on the other hand, is a technique that could solve the above problems. On the other hand, tools for data synthesis are immature compared to tools for training and designing machine learning models.
Therefore, this paper proposes a Python framework called Kubric, which can work with PyBullet and Blender to generate photorealistic images and annotate them with details. Additionally, it can be distributed across thousands of machines, allowing for large-scale data generation to be deployed.
In this paper, we validate the effectiveness of Kubric by generating 13 different types of data for key tasks.
Introduction.
Large-scale, high-quality data is essential for deep learning. The quantity and quality of data is as or more important than model design and training methods. However, collecting and managing sufficient high-quality data for even simple image-based tasks is a difficult task.
Data synthesis has been used for benchmark evaluation because it is easy to annotate (true/false) and to control image complexity. It can also be used to systematically evaluate data that do not conform to the assumptions of the model, even by synthesizing data not assumed in the model design. Similarly, synthetic data has been used to train models and has been shown to be surprisingly effective.
However, tools for data generation are not very mature. In this paper, we propose Kubric, a workframe for data generation, which can generate data sets in various formats (see figure below) for vision tasks and can be annotated in detail. Furthermore, Kubric can run large data generation jobs on thousands of machines. In this paper, we generate 13 different datasets and validate them with various benchmarks.
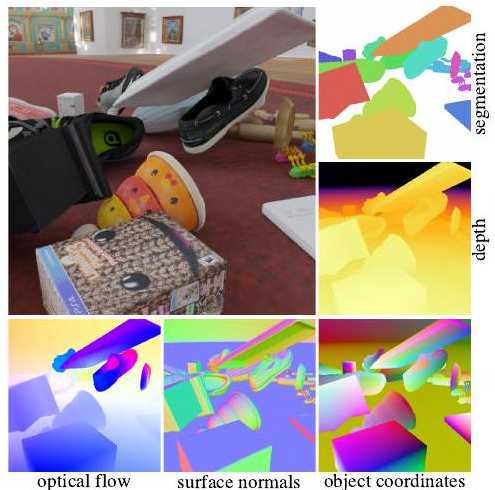
Above is a scene created with Kubric (note: in the paper, of course, it is a still image, but on GitHub you can see it as a video). Object collisions and other simulations are done in PyBullet, and rendering is done in Blender. The exported image (above) contains rich annotations such as segmentation, depth map, optical flow, and normal vectors.
Related Research
Synthesized data provides high-quality labels for many image tasks; CLEVR, ScanNet, SceneNet RGB-D, NYUv2, SYNTHIA, virtural KITTI, flying things 3D, and others have been reported as data synthesis tools, but they are designed for specific specific tasks. In many cases, data such as camera settings, lighting conditions, etc. are not preserved.
There are also data synthesis pipelines using Blender and Unity, but even these are often designed for specific tasks. More to the point, without in-depth knowledge of the rendering engine, it is difficult to assign new attributes to the data.
ThreeDWorld is known as a general-purpose data synthesis engine like Kubric.
ThreeDWorld offers a flexible Python API and a Unity3D-based engine, NVIDIA Flex physics simulator, and comprehensive export to sound generation with PyImpact. Also, the closest thing to Kubric is BlenderProc, but the difference between BlenderProc and Kubric is that Kubric allows jobs on thousands of machines and is more heavily integrated with TensorFlow.
Data Sets and Issues
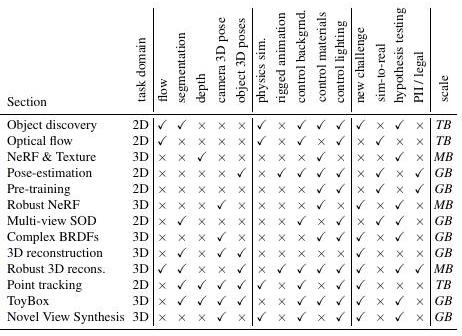
To demonstrate Kubric's performance and versatility, we describe a series of challenges using Kubric-generated data (listed in the table below).
Object discovery on video
Object discovery means discovering object segmentation masks from videos. The dataset is a video called MOVi, which is divided from A to E according to difficulty level. Comparison is made between SAVi and SIMONe, which are currently SOTA.

Above is the MOVi data set, showing that in D and E, there are some objects (e.g. shoes in the foreground) that are not extracted.
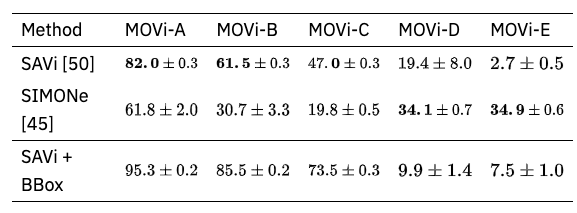
The above results show that object discovery is difficult as visual and dynamic complexity increases. This experiment shows that the data generated by Kubric is useful for evaluating existing architectures.
optical flow
Optical flow is the movement of pixels from one particular frame to the next on a video. It is known that optical flow does not result in high quality data when annotated by humans.

FlyingChairs, shown above, is a dataset of literally floating chairs, and is used in the optical flow dataset. Kubric solves these problems.
Among the known models for optical flow, PWC-net, RAFT, and VCN, we used RAFT to train on Kubric. The results showed a significant performance improvement over FlyingChairs.
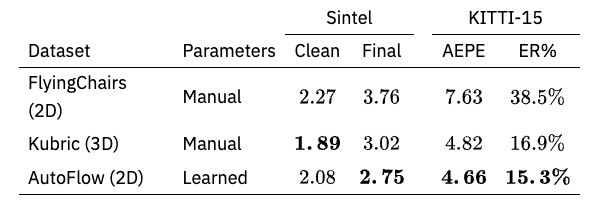
Comparison with AutoFlow is somewhat more complicated, as AutoFlow performs hyperparameter optimization on the model Sintel, so AutoFlow and Kubric cannot be simply compared. Nevertheless, as shown in the table below, they are comparable in performance. Depending on the hyperparameter settings, Kubric is expected to achieve higher performance than AutoFlow.
Texture composition in NeRF
Neural radiance fields (NeRF) is essentially a volumetric representation method, but is commonly used to model the surface of an object. Benchmarking the performance of NeRF by comparing real surfaces with those reconstructed by NeRF is still an unexplored field.

For the NeRF benchmark in this paper, we synthesized an object consisting of the planes shown above. The surface properties (texture) of the object are procedurally generated from blue noise (azure noise). The cutoff frequency is then set for each pixel, which is used as the annotation data. The correlation between the frequency and depth variance is then analyzed (which is the task) and the error from the actual value set is measured.

The results show that the accuracy of color prediction (PSNR) increases with decreasing frequency, while the accuracy of surface properties (depth variance) decreases.
Pose Estimation
Interactive experiences with pose estimation (e.g., Kinect) use human poses as features, but there is clearly a sampling bias for good-looking poses when photos are used as the data set. Therefore, instead of photos, less presentable poses can be complemented by image generation.

The image used for pose estimation is shown above.
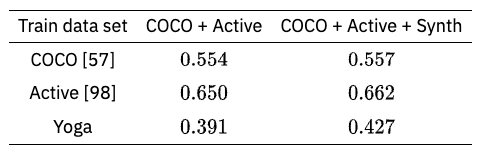
The mean average precision (mAP) was improved by adding images generated by the human body model that are not in the existing data set (COCO).
Other Tasks
In addition to the aforementioned tasks, Kubric-generated data is also available for pre-training visual representations, Robust NeRF, Salient Object Detection (SOD), composite BRDFs (bidirectional reflectance distribution functions (BRDFs), single view reconstruction, video-based reconstruction, point tracking, semantic segmentation, and capped new viewpoint synthesis. Kubric-generated data can also be used for the following tasks
summary
Kubric is a Python library with rich annotation support and an export format for adding data directly to the learning pipeline.
In this paper, we tested the effectiveness of Kubric in 11 case studies. The results showed that Kubric significantly reduced the effort required to generate the necessary data and facilitated reuse and collaboration.
The authors hope that Kubric will lower the barriers to data generation and prevent data fragmentation. Kubric also has its challenges: it does not fully support Blender or PyBullet functionality. In the future, Kubric will support camera effects such as fog and flames, depth of field and motion blur.



Categories related to this article






