You Can Now EASILY Train 10x Bigger Models On Your GPU Using 'ZERO-Offload' !!
3 main points
✔️ A new Hybrid GPU+CPU system that allows you to train 10x bigger models on a single GPU.
✔️ Highly scalable to 128+ GPUs, and can be integrated with model-parallelization.
✔️ A fast CPU Adam optimizer with 6x speedup
ZeRO-Offload: Democratizing Billion-Scale Model Training
written by Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, Yuxiong He
(Submitted on 18 Jan 2021)
Comments: Accepted to arXiv.
Subjects: Distributed, Parallel, and Cluster Computing (cs.DC); Machine Learning (cs.LG)



First of all
Since their advent, the size of Deep Neural Network(DNN) models has scaled rapidly, with the recent GPT-3 model having a staggering 175 billion parameters. This increase in size is one of the reasons why models as big as the GPT-3 perform so well. However, training these networks is a challenging and expensive task. To train a model with 10B parameters properly, one would need about 16 NVIDIA V100s which cost about 100k dollars. This makes training such models inaccessible to many researchers and data scientists. Therefore, making it possible to train DNNs cheaply and yet effectively is a challenge we ought to overcome.
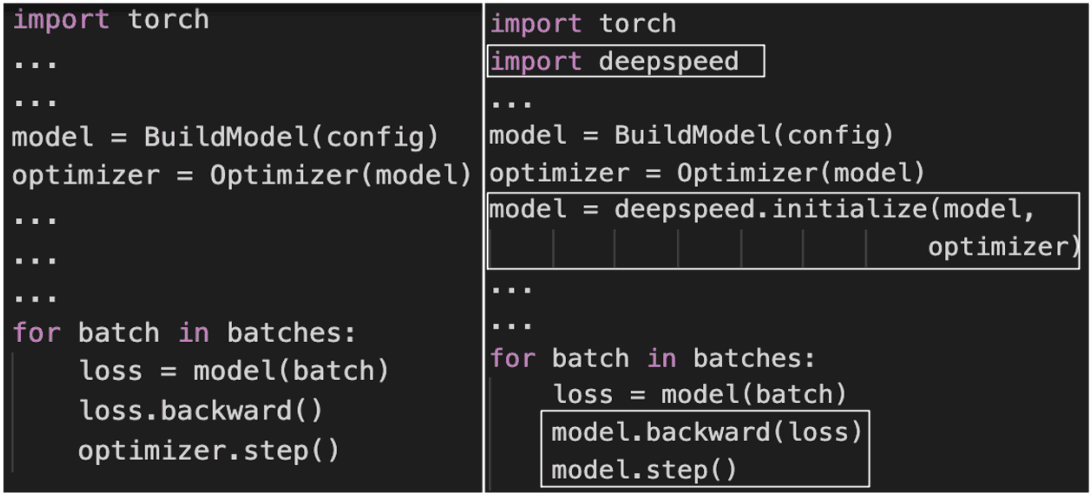 Changes to the PyTorch code to integrate ZeRO-Offload
Changes to the PyTorch code to integrate ZeRO-Offload
In this paper, we introduce 'ZeRO-Offload', an efficient, scalable, and easy-to-use system as a part of the open-sourced DeepSpeed PyTorch library. With just a few lines of code, you can train up to 10x larger models on your GPU. It is also highly scalable and offers almost linear speedup for up to 128 GPUs. Besides, it can work together with model parallelization to train even larger models.
Some Key Concepts
There have been significant efforts in the past to enable training larger models on a GPU with more than its memory capacity. For this, we need to be able to adjust the model states(parameter, gradient, and optimizer states) and residual states(activations, temporary buffers, and unusable memory) into and out of the memory. These efforts can be classified as follows:
Scale-up large model training
It refers to splitting the model among multiple GPUs to meet memory needs. Model parallelism and pipeline parallelism are two such techniques that split the models vertically and horizontally respectively. A recent work ZeRO makes model parallelism more efficient by making it unnecessary to replicate all model states on all GPUs and instead of using communication collectives to gather information as needed during training
Scale-out large model training
It refers to using a single GPU to train larger model sizes. This has been done in three major ways:
- How to use low precision or mixed precision numbers
- How to trade memory for computation by recalculating from checkpoints
- This method uses the CPU's memory.
ZeRO-Offload is based on the third method.
Key Features of ZeRO-Offload
In this section, we explain the features of ZeRO-Offload and their functioning mechanisms.
Unique Optimal Offload Strategy
ZeRO-Offload expands training memory by offloading a portion of the model states to the CPU (residual states are not handled). The challenges in doing that involve the slower CPU computation and GPU-CPU communication overhead. To overcome these challenges, Zero-Offload models the training as a graph as shown below and divides it among the GPU and CPU. It can achieve an optimal solution for the given CPU-GPU pair under the constraints that: CPU workload be much smaller than GPU such that CPU does not act as a bottleneck, and maximized memory saving with reduced CPU-GPU communication volume.
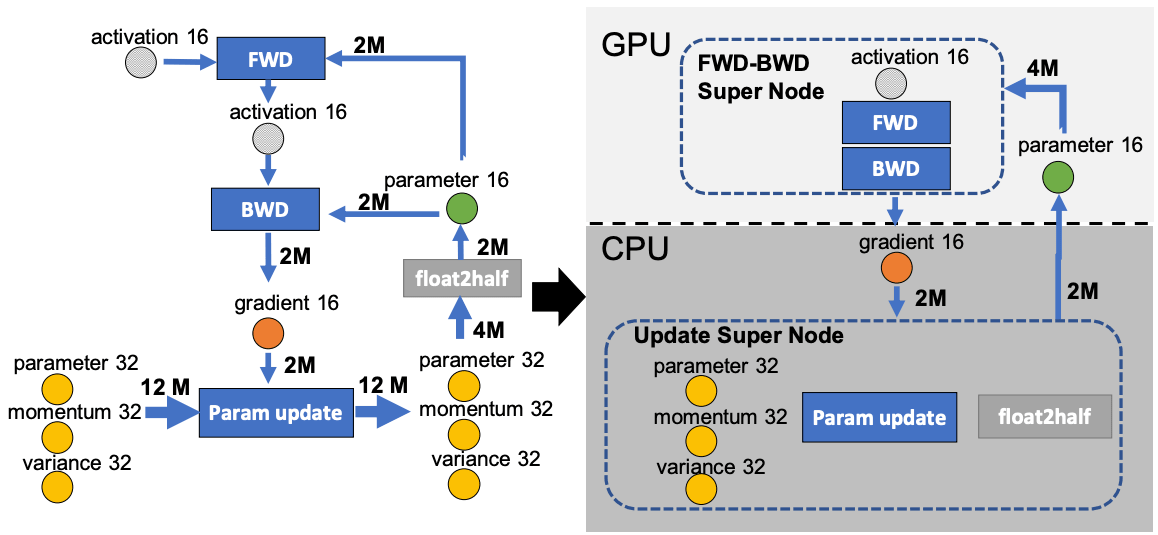
The forward and backward passes have time complexity O(model_sizexBatch_size) and are performed in the GPU called the FWD-BWD Super Node. To prevent the CPU from being a bottleneck, we want the CPU computation workload to be lower than the GPU. So, the weight updates and norm calculations with time complexity O(model_size) are performed on the CPU and called the Update Super Node.
The fp16 parameters are stored in GPU and the fp16 gradients, fp32 momentum, variance, and parameters are stored in CPU. This results in a 4-node system: FWD-BWD supernode, update supernode, gradient16(g16), and parameter16(p16) node.
Single-GPU Scheduling
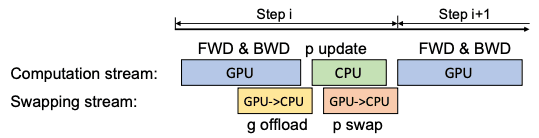
The forward pass is followed by loss calculation and then backward pass which do not require communication with the CPU. The gradients computed are immediately transferred to the CPU and do not require much memory to store in GPU. Gradient transfers and backpropagation can be overlapped which reduces communication costs further. After performing fp32 weight updates on the parameters on the CPU, they are copied to the fp16 GPU parameters, and the process repeats.
Multi-GPU Scheduling
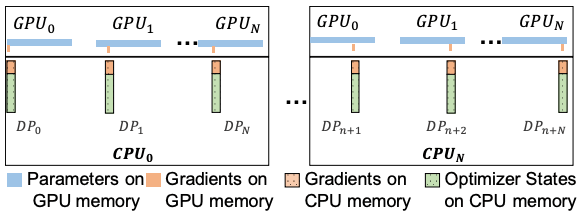
ZeRO-Offload works along with ZeRO to allow multiple GPU compatibility. Specifically, it uses ZeRO-2, which divides the gradients and optimizer states among GPUs. Each GPU holds a copy of the parameters but is responsible to update a portion of the parameters. So, it only holds the gradients and optimizer states for that portion of parameters. After a forward pass, each GPU updates its designated parameters on its mini-batch(each GPU gets a different mini-batch). Then, the updated parameters from all the GPUs are collected using the all-gather communication collective, combined, and redistributed.
Optimized CPU Execution
We also introduce a fast CPU Adam optimizer by parallelization of data processing in the CPU. The optimized Adam uses SIMD vector instruction for hardware parallelism, Loop unrolling for instruction-level parallelism, and OMP multithreading for utilizing multiple cores and threads
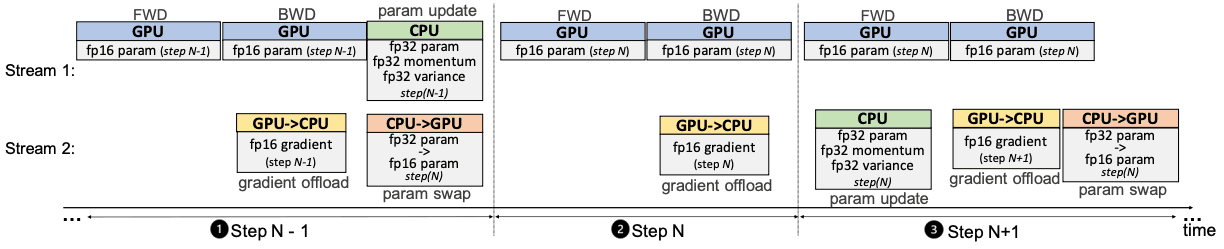
Despite the optimized Adam, the CPU computation load size might get closer to the GPU load size in the case of smaller batch sizes. In this case, we use a one-step delayed parameter update(DPU) and overlap GPU and CPU by one step. In DPU, the early N-1 steps are skipped because of rapidly changing gradients. From then on, parameter updates on ith step are computed using gradients from the previous (i-1)th step allowing the GPU and CPU to work simultaneously. It was found that using DPU after a few dozen iterations does not significantly affect the accuracy of the model.
Experiment and Evaluation

ZeRO-Offload is significantly better than Pytorch, Megator, Zero-2, and L2L in terms of training throughput, and the biggest model size. Besides, DPU is shown to increase the throughput per GPU for a smaller batch size of 8.
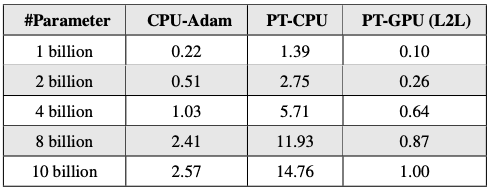
Adam Latency for PyTorch(PT) and CPU-Adam
CPU-Adam performs significantly better(up to 6 times better) than the default PyTorch Adam implementation on CPU. PyTorch-GPU Adam is faster but takes up a portion of GPU memory in return (an undesirable tradeoff).
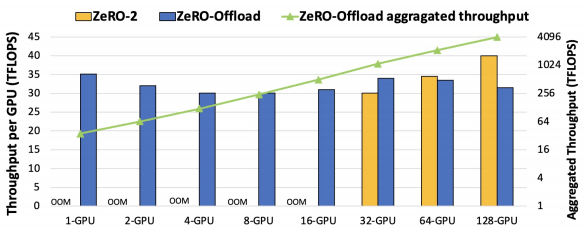
Learning throughput between ZeRO-Offload and ZeRO-2 in 10B parameter GPT-2
ZeRO-Offload retains the throughput per GPU even as the number of GPU increases(up to 128 GPUs). It is also observed that ZeRO-2 outperforms ZeRO-Offload for a higher GPU count.
Summary
I think little needs to be said about the wonderful ZeRO-Offload, as the experimental results speak for themselves. This paper has introduced some clever ideas to train Deep Neural Networks efficiently. In doing so, it has made training multi-billion parameter models accessible to thousands of enthusiastic data scientists and researchers all over the world. It is open-sourced and included in the DeepSpeed library, and you can easily integrate it into your projects. I would recommend that you go through the original paper to get more detailed information about the system. Here is the GitHub repository of DeepSpeed.



Categories related to this article






