Contrastive Learning's Two Leading Methods SimCLR And MoCo, And The Evolution Of Each (Representation Learning Of Images Summer 2020 Feature 2)
3 main points
✔️ Big Players Approach Contrastive Learning, Competing for its High Performance
✔️ The Need for and Avoidance of Large Negative Samples
✔️ Upgrade to incorporate improvements in countermeasures to further improve performance
Big Self-Supervised Models are Strong Semi-Supervised Learners (SimCLRv2)
written by Ting Chen, Simon Kornblith, Kevin Swersky, Mohammad Norouzi, Geoffrey Hinton
(Submitted on 17 Jun 2020)
Comments: Published by arXiv
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (stat.ML)
Paper Official Code COMM Code
Improved Baselines with Momentum Contrastive Learning (MoCo v2)
written by Xinlei Chen, Haoqi Fan, Ross Girshick, Kaiming He
(Submitted on 9 Mar 2020)
Comments: Published by arXiv
Subjects: Computer Vision and Pattern Recognition (cs.CV)
Paper Official Code COMM Code
The writer's special project entitled "Learning to Express Images Summer 2020" introduces various methods of unsupervised learning.
Part 1. Image GPT for domain knowledge-free and unsupervised learning, and image generation is amazing!
Part 2. Contrastive Learning's Two Leading Methods SimCLR And MoCo, And The Evolution Of Each
Part 3. SOTA With Contrastive Learning And Clustering!
Part 4. Questions For Contrastive Learning : "What Makes?"
Part 5. The Versatile And Practical DeepMind Unsupervised Learning Method
Having survived two AI winters and gaining expressive power with the massive image dataset ImageNet, AI in images blossomed in 2012 in a big way. However, this required significant costs for the human labeling of images. In contrast, BERT, which made such a huge social impact in 2018 that natural language processing became a concern for fake news, is also a major feature of the vast amount of data available as it is.
Contrastive learning is a form of unsupervised learning that uses a mechanism for comparing data to each other instead of costly labeling, and is capable of training large amounts of data as is. It has been successfully applied to images and has already surpassed the performance of ImageNet-trained models and, like BERT, is expected to have a future impact in the imaging field.
Contrastive Learning, In recent years, many papers have been submitted to the journal and it has become very active.
For example, see the leaderboard "Self-Supervised Image Classification on ImageNet " ( self-supervised learning on ImageNet) on Papers With Code (a well-known site that summarizes papers and their codes), which shows that the proposed 2020/2019 You can see that the top of the list is dominated by the methods used.
In this article, we'll take a look at the path to version 2 of SimCLR and MoCo, the de facto standard methods that are very often cited and cited for comparison among the methods that appear near the top, respectively.
What characteristics, innovations, and circumstances led to the accuracy of these papers?
First, I'd like to review the basic motivation, aims, and fundamentals of Contrastive Learning. (If you're in the know, please skip ahead.)
Why unsupervised learning of images?
There seems to be a widespread perception that machine learning of images is already a commonplace application and is performing well enough.
In my last article, " Image GPT for domain knowledge-free and unsupervised learning, and image generation is awesome too! ", I wrote about how we've been able to make this happen. ", I wrote about how we got to this point, but the impetus may be due to the fact that "BERT (Devlin et al., 2019 )" has been very influential in natural language processing (NLP).
For more information about BERT, see also this media outlet, " Google's Latest Technology in Natural Language Processing, Who is BERT?
As BERT led to improvements in the performance of various tasks and advances in NLP, the same unsupervised training of models for images was expected to improve performance. Also.
ImageNet trained → (transfer learning) → task applications such as image classification, object detection, and segmentation
With this usage well-established, a paper was written in 2018 that questioned the use of ImageNet trained models. It was shown that transition learning using ImageNet in object detection does not necessarily improve performance, but rather that there are cases where it is better to not use it.

"Rethinking ImageNet Pre-training" (He et al., 2018 ).
A breakthrough in the use of ImageNet trained models
In addition, it appears that the pre-learning methods already proposed at the time were not performing well enough to withstand evaluation, which raises questions.
Should we pursue universal expression? Yes, we believe that learning the universal expression is a goal worth striving for. Our results do not deviate from this goal. In fact, our study suggests that we should evaluate learned features (obtained in self-supervised learning) more carefully, just as we have shown that we can get better results when randomly initialized.
And He et al. who posed this question themselves produced the results below, showing that the MoCo self-supervised model performed better for object detection than the ImageNet-trained model.
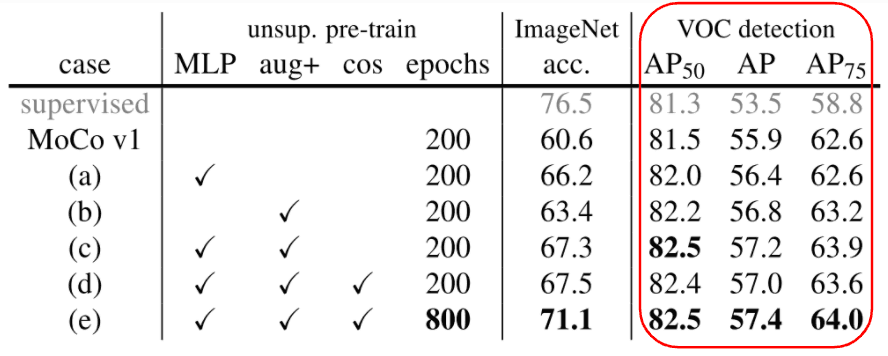
From Table 1 of the paper MoCo v2, the results of realizing the increase in performance
- VOC detection is the result of object detection, compared to "supervised", which shows that the result of pre-training in MoCo is more accurate.
- However, ImageNet's classification accuracy remains higher for supervised.
Also, like NLP, it is expected to make better use of the vast amount of data on the Internet, and the performance will increase as the amount of data increases. In fact, the use of vast amounts of data has already outperformed the performance of ImageNet trained models.
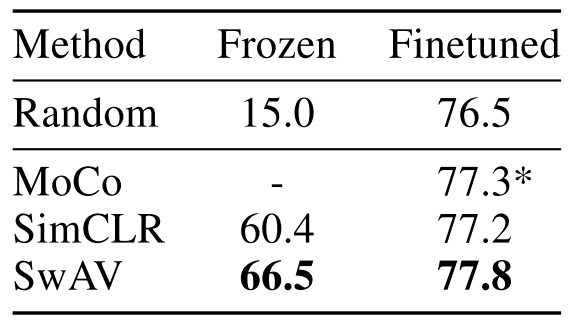 論文 Unsupervised Learning of Visual Features by Contrasting Cluster Assignments (Caron et al., 2020)、Figure 1よりImageNetのTop-1精度
論文 Unsupervised Learning of Visual Features by Contrasting Cluster Assignments (Caron et al., 2020)、Figure 1よりImageNetのTop-1精度
- Random is the result of the normal ImageNet training model, 76.5% (ResNet-50).
- Each of the methods, in contrast, all outperformed their results. → Results of unsupervised pre-training using a vast array of unscreened Instagram images.
There are several methods of unsupervised learning, but the one that delivers outstanding performance is Contrastive Learning.
To read more,
Please register with AI-SCHOLAR.
OR


Categories related to this article


![[Swin Transformer] T](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2024/swin_transformer-520x300.png)



