![Qwen2.5-Coder] LLM Specialized For Code Generation, Completion, And Mathematical Reasoning Tasks](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2024/qwen2-5-coder.png)
Qwen2.5-Coder] LLM Specialized For Code Generation, Completion, And Mathematical Reasoning Tasks
3 main points
✔️ Qwen2.5-Coder is an LLM dedicated to code generation, completion, and mathematical reasoning tasks
✔️ Trained on large datasets of over 5.5 trillion tokens, it can complete partial code deficiencies using methods like Fill-in-the-Middle
✔️ Excellent performance for mathematical reasoning across multiple programming languages and long contexts
Qwen2.5-Coder Technical Report
written by Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Kai Dang, An Yang, Rui Men, Fei Huang, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, Junyang Lin
(Submitted on 18 Sep 2024)
Comments: Published on arxiv.
Subjects: Computation and Language (cs.CL)
code:

The images used in this article are from the paper, the introductory slides, or were created based on them.
Summary
This paper describes Qwen2.5-Coder, a new large-scale language model dedicated to code generation.
Qwen2.5-Coder is a significant evolution from its predecessor, CodeQwen1.5, and is specifically designed to provide superior performance in programming-related tasks such as code generation and code modification. The series includes two models with 1.5B (1.5 billion) and 7B (7 billion) parameters.
Proposed Method
Qwen2.5-Coder is a large-scale language model specialized for code generation, based on the "Qwen2.5" architecture and pre-trained on a large data set of over 5.5 trillion tokens.
A central feature of the model is its ability to handle a wide range of programming-related tasks such as code generation, inference, and editing. For example, benchmarks such as HumanEval and MBPP show superior performance against other large-scale models, and the model is highly versatile, especially with several programming languages, including Python. Furthermore, by introducing a technique called Fill-in-the-Middle (FIM), it has the ability to generate complements in situations where portions of code are missing. This allows for prediction and editing of missing code sections.
Qwen2.5-Coder performs pre-training on a per-file and per-repository basis and is efficient when working with long codes or entire repositories. In particular, to handle entire repositories, the maximum token processing length is extended to 32,768 tokens, allowing for larger context processing than previous models. Mathematical data is also incorporated into the training to handle mathematical problems, making it excellent for mathematical reasoning in addition to code generation.
Experiment
The experiments were designed to validate the performance of Qwen2.5-Coder and were conducted through several benchmarks. In particular, it has been evaluated using several key data sets to assess the accuracy of code generation, code inference, and editing tasks.
First, code generation performance is evaluated with benchmarks such as HumanEval and MBPP. HumanEval is based on Python programming tasks and provides 164 problems, each with a function signature and description. MBPP is more diverse, with 974 problems and multiple test cases to check the performance of the model. In these benchmarks, Qwen2.5-Coder achieves higher accuracy than the other models, especially in the 7B model. For example, it scored 61.6% on HumanEval, which compares very favorably with other models of similar size.
Next, the ability of code completion is also examined. Here, a technique called Fill-in-the-Middle (FIM) is utilized, which evaluates the ability of a model to complete a missing piece of code when it is missing. In this evaluation, Qwen2.5-Coder predicts missing parts with high accuracy in several programming languages (Python, Java, and JavaScript) and compares favorably with other large-scale models.
Code inference is also evaluated. Here, the "CRUXEval" benchmark is used to test whether the model can accurately predict the output and input of a given code. In particular, the "Input-CoT" task, which predicts the result of code execution, and the "Output-CoT" task, which predicts the input of a code from its output, were performed, and Qwen2.5-Coder performed better than other models of similar size.
Finally, the ability to perform mathematical reasoning was also evaluated. Here, datasets containing mathematical problems such as MATH and GSM8K were used, confirming that Qwen2.5-Coder is powerful not only for code generation, but also for solving mathematical problems. 7B models show a very high accuracy rate of 83.9% for GSM8K.
These results demonstrate that Qwen2.5-Coder has excellent capabilities not only in code generation, completion, and reasoning, but also in mathematical problem solving, with high performance on a wide range of tasks.
Explanation of Figures and Tables
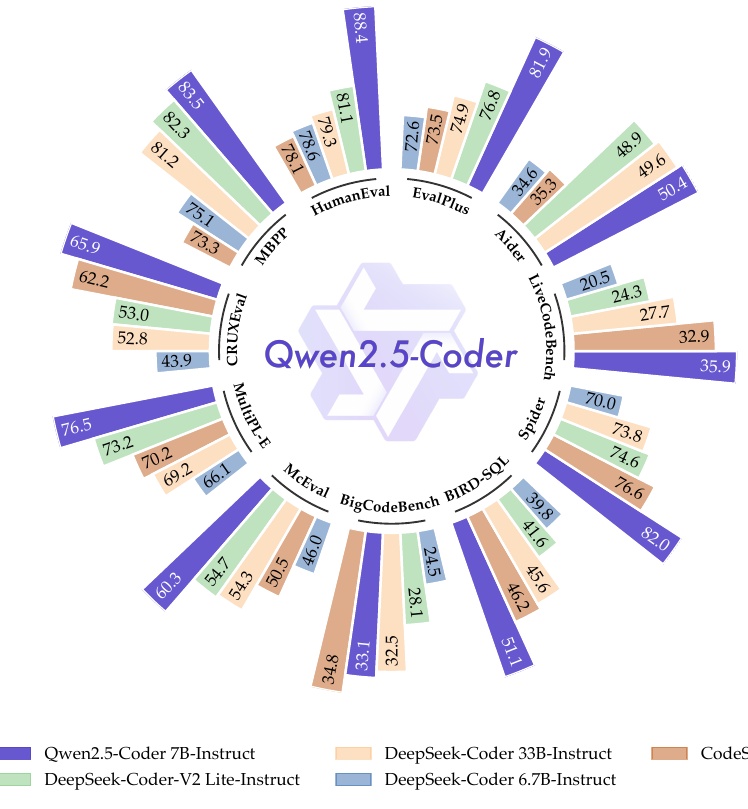
This figure shows the performance of the model Qwen2.5-Coder on various evaluation benchmarks. The Qwen2.5-Coder is in the center of the figure, surrounded by the results of the different tests arranged in a circle. Each test compares the performance of the Qwen2.5-Coder to other models.
Specifically, the Qwen2.5-Coder 7B-Instruct is shown in blue-purple, while other assessments include different models such as DeepSeek-Coder and CodeStral. Benchmarks measured include HumanEval, MBPP, CRUXEval, MultiPL-E, and LiveCodeBench, each measuring a variety of abilities related to programming tasks.
The numbers show the scores each model achieved in each benchmark, confirming that the Qwen2.5-Coder 7B-Instruct performs well in many assessments. For example, it has a high score of 84.1 in HumanEval, indicating its overall superior capability.
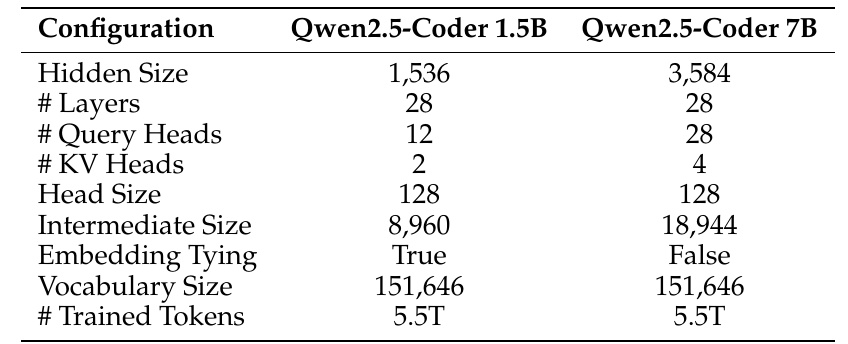
This table shows the configuration of the Qwen2.5-Coder model. Two models belonging to the same Qwen2.5-Coder series, 1.5B and 7B, are compared.
- The size of the hidden layer (Hidden Size) is 1,536 for the 1.5B model and 3,584 for the 7B model. The larger these numbers are, the more complex patterns may be learned.
- The number of layers (# Layers) is 28 for both models. In general, the higher the number, the more expressive the model, but also the more computationally demanding.
- Query Heads (# Query Heads) are 28 for the 7B model compared to 12 for the 1.5B model. Key Value Heads (# KV Heads) are 2 for the 1.5B model and 4 for the 7B model, related to the attention mechanism of the transformer model.
- The head size (Head Size) is 128, the same for both models.
- The Intermediate Size (Intermediate Size) is also shown: 8,960 for the 1.5B model and 18,944 for the 7B model. This difference appears as the model processes the information.
- Embedding Tying is "True" for the 1.5B model and "False" for the 7B model. This indicates whether or not the word embedding and output layers share the same matrix.
- The vocabulary size (Vocabulary Size) of words is standardized at 151,646 words for both models.
- The number of tokens used for training (# Trained Tokens) is 5.5 trillion tokens for both models, indicating that they were trained with a huge amount of data.

This chart shows information about the special tokens handled by the model, Qwen2.5-Coder. The model uses specific tokens to make the code easier to understand.
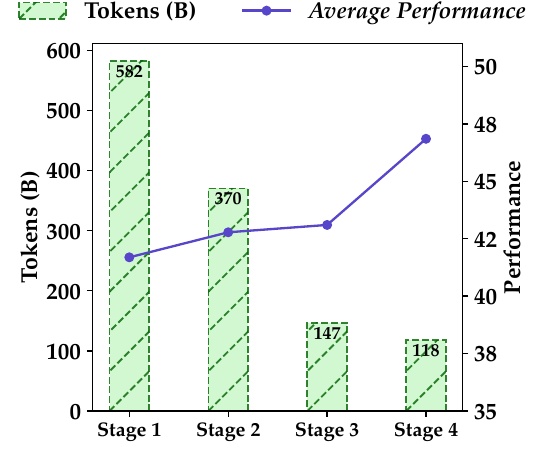
This figure shows the relationship between the number of tokens per stage of data filtering in Qwen2.5-Coder and the average performance of the model.
First, regarding the increase and decrease in the number of tokens, 58.2 billion tokens were used in Stage 1. On the other hand, the number of tokens in Stage 2 decreased to 37 billion tokens, and in Stages 3 and 4, 14.7 billion and 11.8 billion tokens, respectively, indicating that the data has been carefully selected.
Next, we look at changes in performance. From Stage 1 to Stage 4, the average performance of the model improved from 41.6 to 46.8. This implies that the model's performance improved as data was filtered and higher quality data was used.

This diagram shows how the model Qwen2.5 was developed and what stages it went through to reach its final form.
First, the Qwen2.5 model is pre-trained on a large data set. This step is called "File-Level Pretrain" and uses 5.2 trillion (5.2T) tokens. Here, the basic knowledge is acquired by learning from individual code files.
Next, a "Repo-Level Pretrain" stage takes place. Here, another 300 billion (300B) tokens are used to learn information from the entire repository. This process enhances our ability to understand the context of larger, more complex codes.
Then you will move on to the "Qwen2.5-Code-Base" phase. The model here builds on what you have learned and becomes more sophisticated in its ability to generate code.
Finally, the model is fine-tuned in the "Code SFT" step and released in its final form as Qwen2.5-Code-Instruct. The model in this stage requires flexibility for specific code tasks and is shaped with an eye toward practical application.
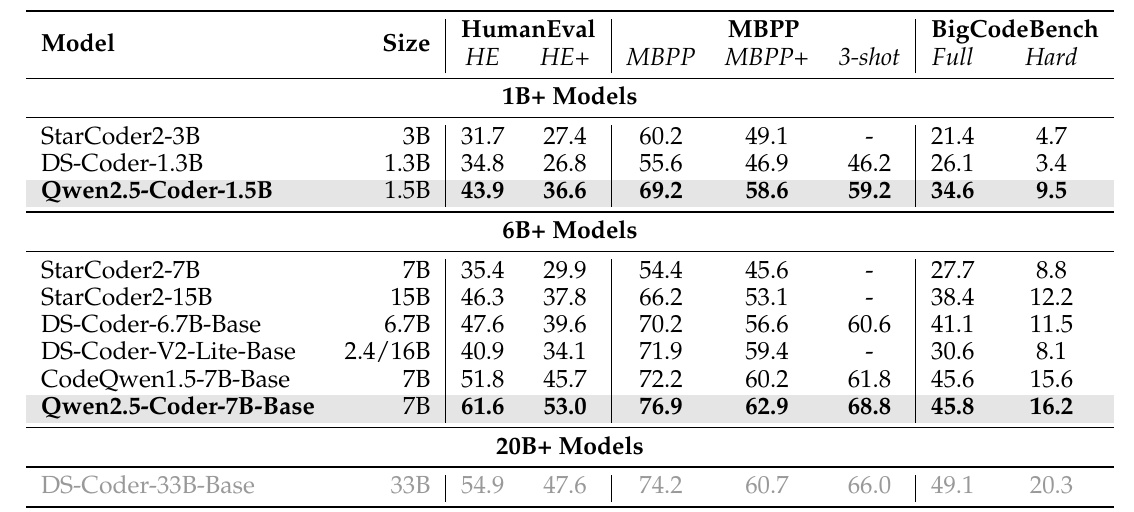
This chart shows how the different models performed on several metrics. Each model was evaluated on the HumanEval and MBPP, as well as on a benchmark called BigCodeBench.
First, the "Model" column lists the type of model being evaluated. For example, there are "Qwen2.5-Coder-1.5B" and "StarCoder2-7B". Those models have different parameter size variations.
Next, the "Size" column lists the number of parameters in the model, which is related to the "smartness" or processing power of the model. For example, "3B" means it has 3 billion parameters.
Then, "HumanEval" and "MBPP" are benchmarks for evaluating the ability to generate programming tasks. HE" and "HE+" are the names of their specific rating scales, and "MBPP+ 3-shot" likewise represents a rating scale.
And the "BigCodeBench" is rated on two difficulty levels in particular, "Full" and "Hard," with even different criteria.
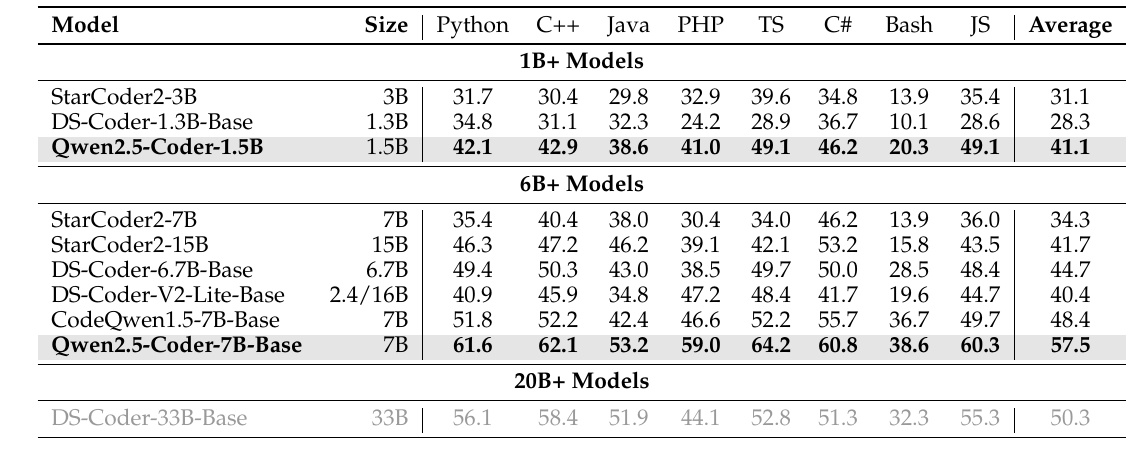
This figure compares the performance of the Qwen2.5-Coder code generation model with other models. Each model shows its performance in different programming languages.
First, the "size" of the model indicates the number of parameters in the model, for example, "1.5B" means it has 1.5 billion parameters. On the left side of the table are the model names, and on the right side are the scores in each language (Python, C++, Java, etc.). The scores reflect the performance of the model in each language.
The Qwen2.5-Coder-1.5B outperforms other 1B-sized models, earning an average score of 41.1. It performs particularly well in languages such as Python and C#. In addition, Qwen2.5-Coder-7B-Base is the top-scoring 7B size model with a score of 57.5, boasting high performance in a variety of languages.
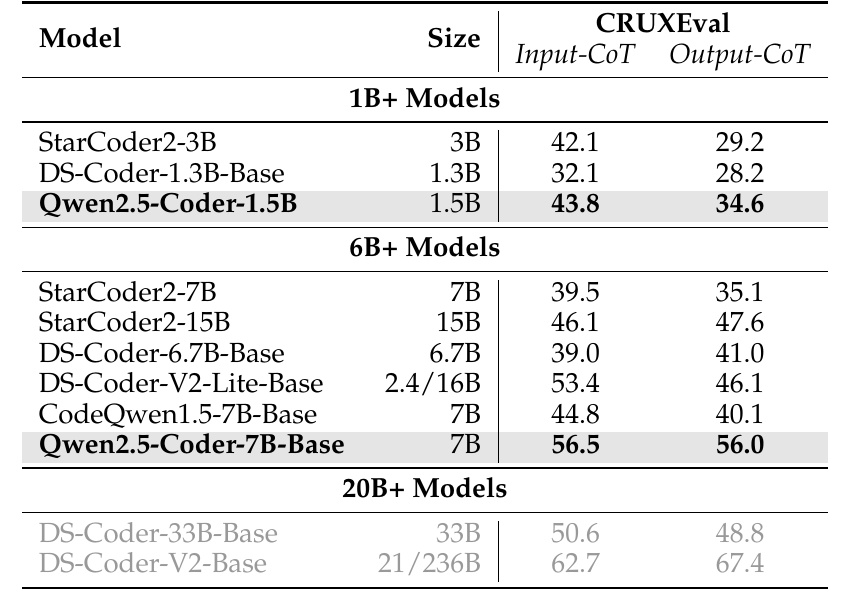
This figure shows the performance of various models in CRUXEval, a criterion that evaluates how a model performs inference when it receives code as input (Input-CoT) and when it treats it as output (Output-CoT).First, there is a column indicating the size of the model, where models with parameters ranging from 1B (1 billion) to 20B (20 billion) or more are listed.
The 1B+ models include StarCoder2-3B, DS-Coder-1.3B-Base, and Qwen2.5-Coder-1.5B. Qwen2.5-Coder-1.5B shows particularly good performance, achieving scores of 43.8 and 34.6 respectively.
The 6B+ model shows high performance with Qwen2.5-Coder-7B-Base scoring 56.5 and 56.0. These figures are higher than those of the other models.
The 20B+ model lists even larger models, but no direct comparison is made in context in this table.
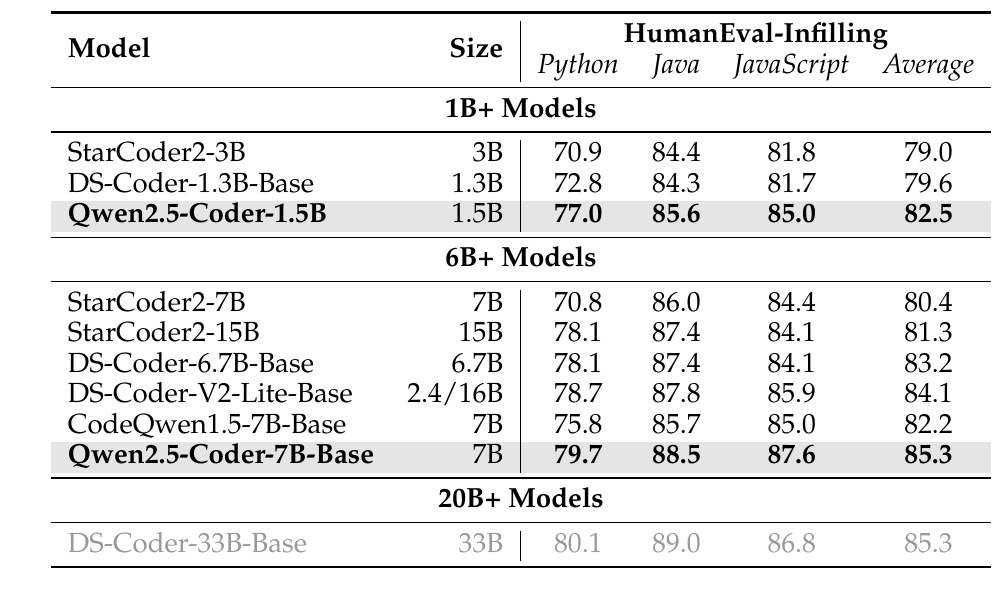
This table shows how well the various models perform on the code completion task. Specifically, it lists the results of evaluations on the HumanEval-Infilling task in the three programming languages Python, Java, and JavaScript. The evaluations show how accurately the models can fill in between codes.
Different model size categories, such as 1B+, 6B+, and 20B+, are separated, and within each category the model name, size, score per language, and average score are given. 1B+ models include StarCoder2-3B, DS-Coder-1.3B-Base, Qwen2.5-Coder-1.5B, and the 6B+ models include StarCoder2-7B and CodeQwen1.5-7B-Base.
The Qwen2.5-Coder-7B-Base achieves the highest score among the 6B+ models. It achieved a particularly high score of 88.5 in Java, and also excelled in other languages.
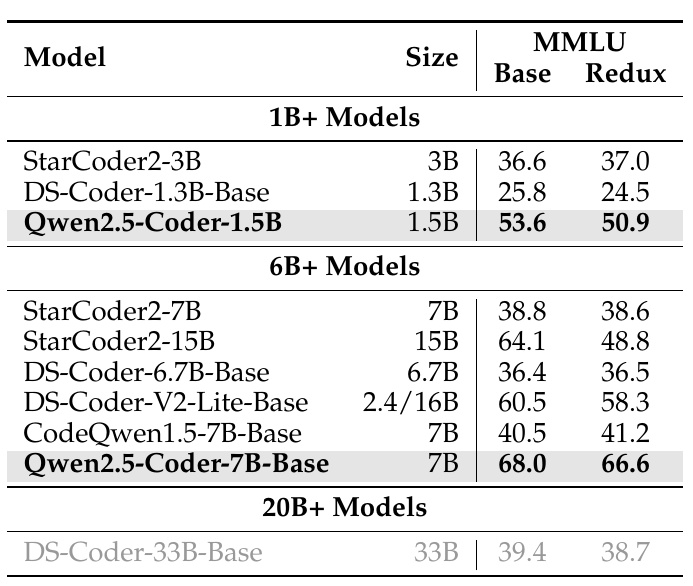
This table compares the performance of different code generation models on two criteria, MMLU Base and MMLU Redux. The evaluation results are shown for models of different sizes.
First, in the 1B+ model category, Qwen2.5-Coder-1.5B scores higher than the other models. This model scores 53.6 on MMLU Base and 50.9 on Redux. This performance is superior to the other 1B+ models.
Next, in the 6B+ model category, Qwen2.5-Coder-7B-Base stands out, with a very good score of 68.0 for MMLU Base and 66.6 for Redux. This compares favorably with the other 6B+ models.
On the other hand, the DS-Coder-33B-Base, featured as a 20B+ model, has relatively modest results of 39.4 (Base) and 38.7 (Redux), despite its large size (33B).
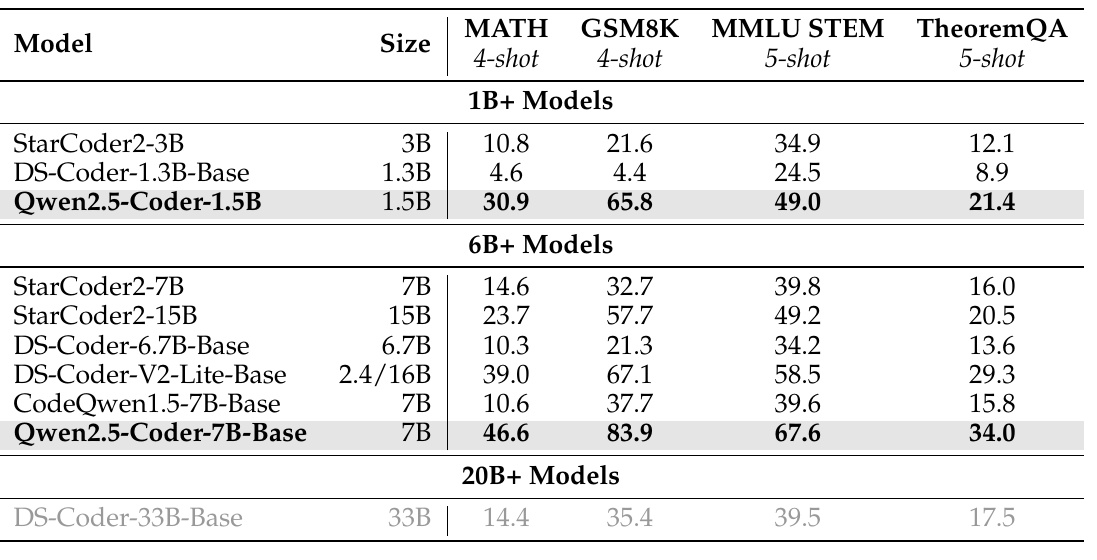
This table compares how different models perform against four math-related benchmarks. The specific benchmarks are MATH, GSM8K, MMLU STEM, and TheoremQA, and it shows how well each model achieves accuracy (score) on each benchmark.
First, let's look at the 1B models at the top of the table. The "Qwen2.5-Coder-1.5B" outperforms the other "StarCoder2-3B" and "DS-Coder-1.3B-Base" models. In particular, it achieved a high score of 65.8 in the "GSM8K" benchmark.
Next, looking at models in the 6B range, the "Qwen2.5-Coder-7B-Base" shows superior performance compared to other models of similar size. In particular, it outperforms other models, achieving 83.9 for "GSM8K" and 67.6 for "MMLU STEM".
Finally, we can see that the Qwen2.5-Coder-7B-Base shows competitive performance in many benchmarks when compared to the DS-Coder-33B-Base, a model in the 20B range.
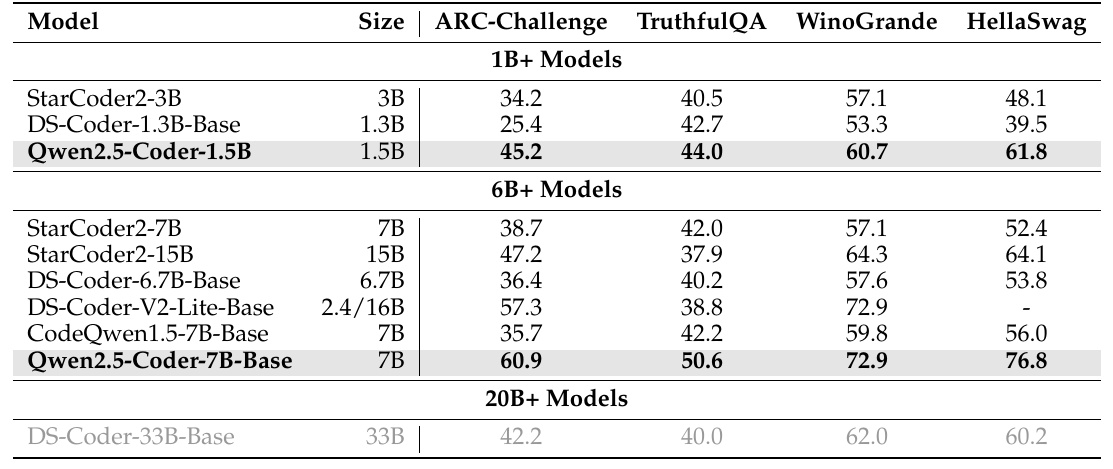
This figure shows a comparison of machine learning models. Specifically, it evaluates how well the Qwen2.5-Coder series and other models perform against various benchmarks. The benchmarks include the ARC-Challenge, TruthfulQA, WinoGrande, and HellaSwag.
Despite its 1.5B model size, Qwen2.5-Coder-1.5B scores high, especially in the "ARC-Challenge" and "TruthfulQA. It scores 45.2 on the "ARC-Challenge" and 44.0 on the "TruthfulQA."
Also notable is the Qwen2.5-Coder-7B-Base with a size of 7B. It scores a very high 60.9 on the ARC-Challenge, 50.6 on the TruthfulQA, 72.9 on the WinoGrande, and 76.8 on the HellaSwag. It also shows competitive performance against other larger 20B+ models, such as the DS-Coder-33B-Base.
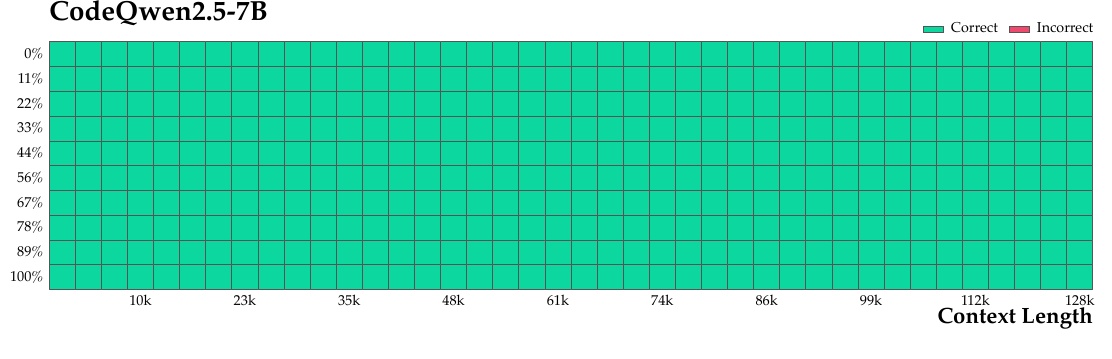
This figure shows the performance of the model "CodeQwen2.5-7B". As you can see, the vertical axis is shown as "percentage of correct answers" and the horizontal axis is a meter indicating "length of context".
Here, the accuracy of the model in some task is evaluated for a range of context lengths from 10k to 128k. The graph shows "Correct" in green and "Incorrect" in red.
Overall, the figure shows that all areas are painted in green, with no red visible at all. This indicates that CodeQwen2.5-7B is highly accurate for this particular task, for a variety of context lengths.
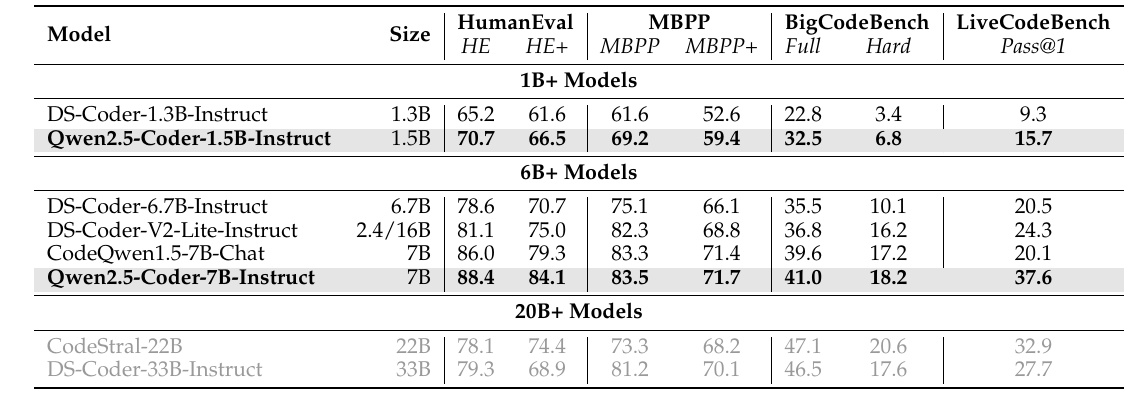
This chart compares how different models perform on benchmark tests related to various code generation. Specifically, the performance of the Qwen2.5-Coder series is highlighted. In the columns of the table, the model name and size (number of parameters included in the model) are given.
HumanEval and MBPP are indicators that test code generation capability, and the Qwen2.5-Coder-7B-Instruct model scores higher than other models in these tests. Specifically, the Qwen2.5-Coder-7B-Instruct model outperforms other models of its size in HumanEval and MBPP with scores higher than 80%, especially in HumanEval+ and MBPP+.
BigCodeBench evaluates the ability to handle more complex code generation tasks. Again, the Qwen2.5-Coder-7B-Instruct model outperforms other 6B-class models.
LiveCodeBench measures the ability to handle the latest coding problems. Again in this benchmark, Qwen2.5-Coder-7B-Instruct shows outstanding performance, recording 37.6% Pass@1. This means how well the model succeeds on the first attempt at a given task.
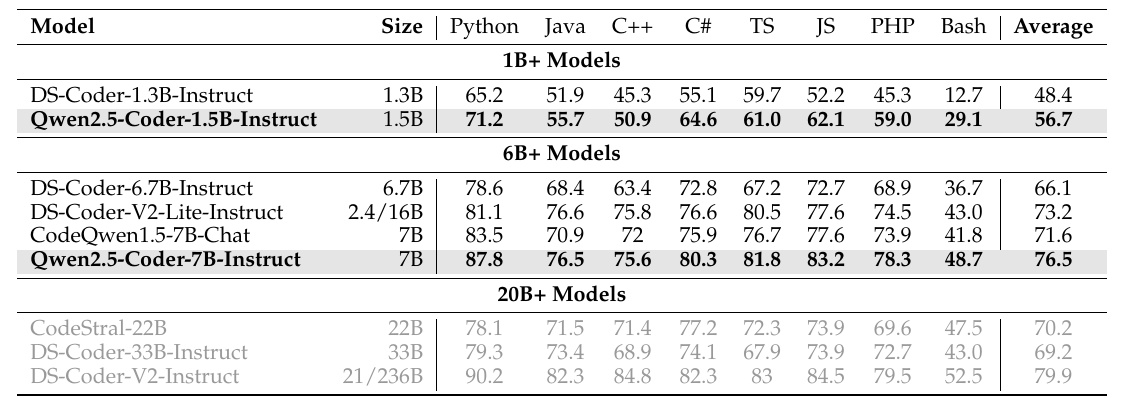
This table shows the performance of the models for different programming languages. The models are of different sizes and their performance is evaluated. For example, the 1.5B size Qwen2.5-Coder-1.5B-Instruct scores quite high for certain languages, including Python, Java, and C++.
Models are grouped into 1B+, 6B+, and 20B+ groups. Each group contains models of different sizes and how they perform in different languages is compared.
The model Qwen2.5-Coder-7B-Instruct shows excellent results in several languages, recording particularly high accuracy in major programming languages such as Python, Java, and C++. On average, this model also outperforms many other models with a score of 76.5, indicating that it is very powerful.
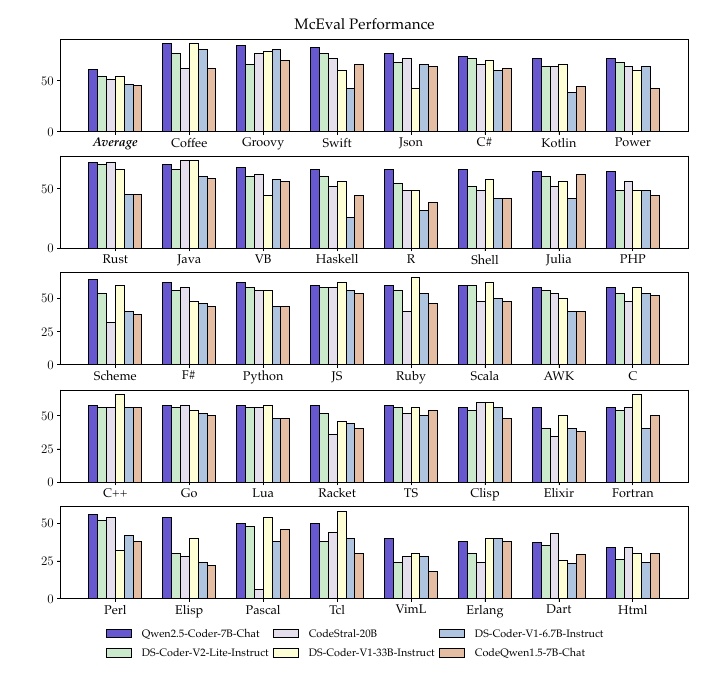
This graph compares the performance of programming languages based on the McEval evaluation criteria. Specifically, the performance of various code models is measured for different programming languages, which is visually represented in a bar graph.
The performance of different models is shown for each language, specifically Qwen2.5-Coder-7B-Chat, CodeStral-20B, and DS-Coder-V2-Lite-Instruct models are compared. The vertical axis of the graph represents the performance score, with higher numbers indicating better performance.
Programming languages shown include major languages such as Python, JavaScript, C#, and Java, as well as slightly more niche languages such as Perl and Fortran. Color coding for each model is shown in the legend, so you can see at a glance how well each model performed in each language.
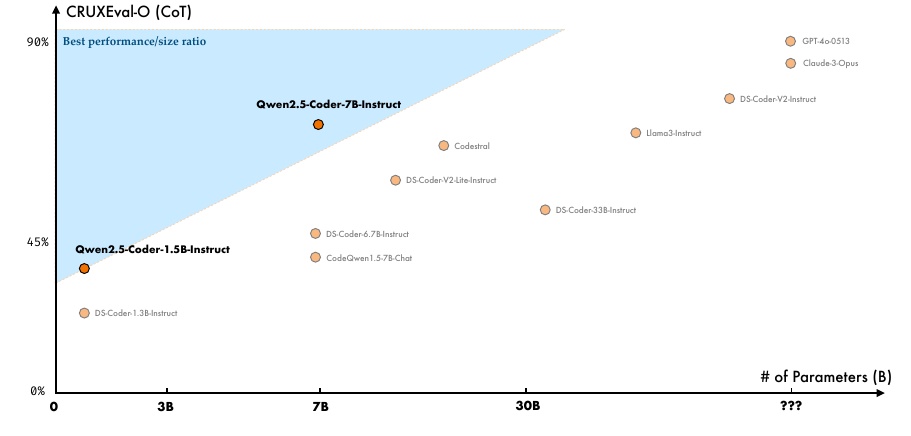
This figure shows the relationship between the CRUXEval-O (CoT) score and the number of parameters in the model. The vertical axis shows the CRUXEval-O (CoT) score, or code inference capability rating, with higher scores indicating better performance. The horizontal axis shows the number of parameters in the model, with the rightward direction indicating a larger model.
On the left side of the figure, the Qwen2.5-Coder series is shown as the model with the best performance to size ratio. In particular, we see that Qwen2.5-Coder-7B-Instruct achieves a high score despite its small number of parameters compared to other models. This indicates that it is more efficient than other large models with many parameters.
The area with the blue background is the area that achieves the most efficient performance-to-size ratio. The Qwen2.5-Coder series is located in this area and can be considered an efficient model design.

This chart compares the performance of one model, Qwen2.5-Coder-7B-Instruct, with another model, DS-Coder-V2-Lite-Instruct. It shows how well each model performed on the different benchmarks.
The table is divided into two parts, with the top part showing the evaluation scores on mathematical and mathematical tasks such as MATH and GSM8K. qwen2.5-Coder-7B-Instruct scored higher on almost all tasks.
The lower portion of the chart shows scores on benchmarks that measure general knowledge understanding, such as AMC23 and MMLU. Here, too, Qwen2.5-Coder-7B-Instruct performs better on all but a few items.
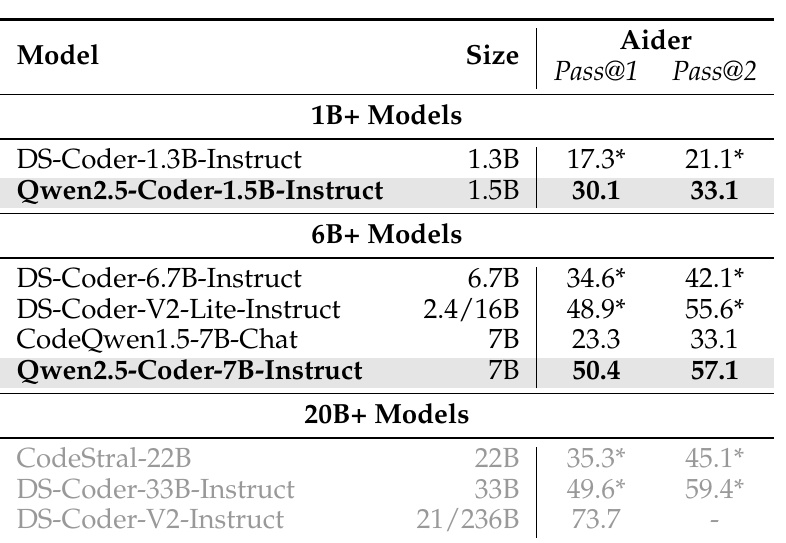
The table in the figure shows the results for measuring the code editing capabilities of different models. In particular, we use the benchmark Aider. The "Pass@1" and "Pass@2" scores for each model indicate the percentage of successful code edits on the first and second attempts.
1. about models and sizes
Each model is grouped into the categories "1B+", "6B+", and "20B+". This indicates scale based on the number of parameters in the model (1B is over 100 million).
The "Qwen2.5-Coder-1.5B-Instruct" and "Qwen2.5-Coder-7B-Instruct" are 1.5B and 7B in size, respectively, and are compared to other models.
2. performance comparison
The "Qwen2.5-Coder-1.5B-Instruct" has a score of 30.1 for "Pass@1" and 33.1 for "Pass@2," showing improved performance compared to the "DS-Coder-1.3B-Instruct" in the same group.
The "Qwen2.5-Coder-7B-Instruct" scored a very high 50.4 in "Pass@1" and 57.1 in "Pass@2," outperforming models in the same category.
3. special note
Compared to large groups of models, such as CodeStral-22B and DS-Coder-33B-Instruct, which are over 20B, the score of Qwen2.5-Coder-7B-Instruct is superior, showing efficient and high performance with fewer parameters The results show that Qwen2.5-Coder-7B-Instruct
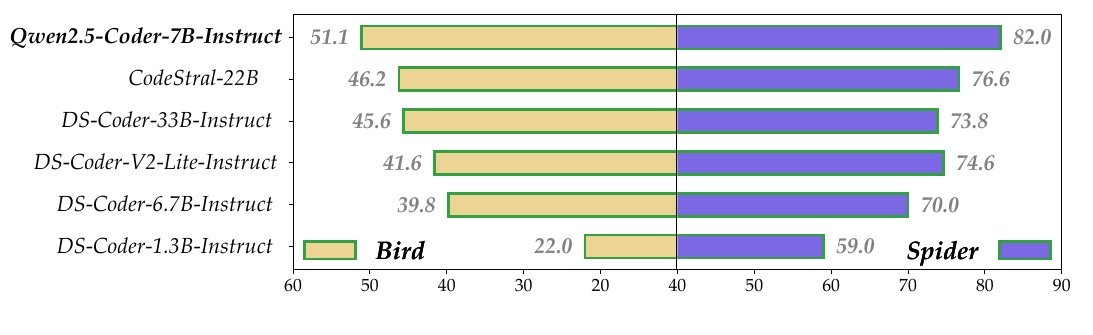
This figure compares the performance of several language models on two benchmarks, Bird and Spider. Specifically, it shows how Qwen2.5-Coder-7B-Instruct performs compared to the other models.
Listed on the left is the name of each model. The graph is a horizontal bar graph, showing how each model scored on the Bird and Spider benchmarks.
The "Bird" benchmark uses a yellow bar graph whose scores extend from left to right. The values exist from "51.1" to "22.0," with Qwen2.5-Coder-7B-Instruct showing the highest performance.
The "Spider" benchmark uses purple bars, with the highest score of 82.0 achieved by the Qwen2.5-Coder-7B-Instruct, which outperforms the other models.
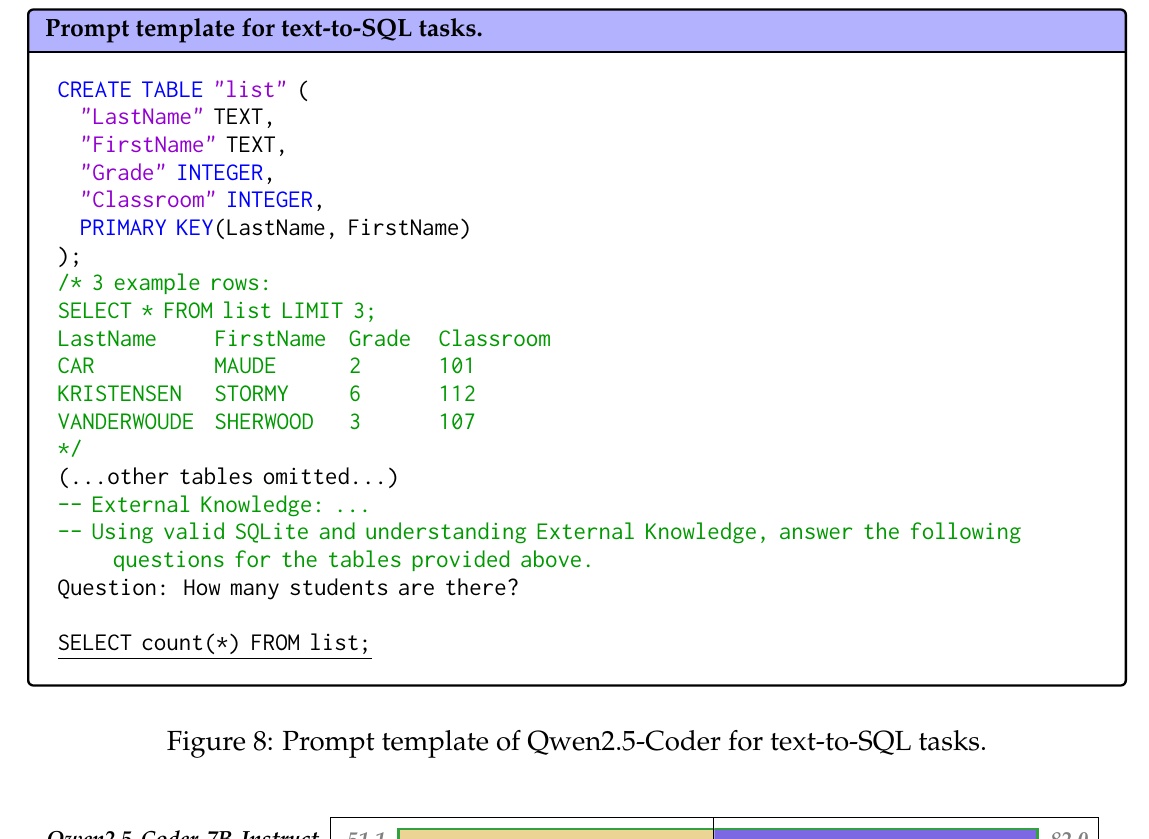
This figure shows a prompt template for Qwen2.5-Coder to use in the Text-to-SQL task, providing a framework for generating SQL statements and helping users understand how to create SQL queries from natural language against a specific database.
First, a table called "list" is defined by the CREATE TABLE statement. This table has attributes such as LastName, FirstName, Grade, and Classroom. Each of these attributes has a data type, with LastName and FirstName specified as the PRIMARY KEY. This key is designed to uniquely identify each student.
Next, data for three students are presented as examples in the table. For example, there is an example of a student whose last name is "CAR" and first name is "MAUDE". This gives the user a clear understanding of the structure and contents of the table.
The prompt template then guides the user to construct an SQL query while utilizing external knowledge in the operation. The question "How many students are there?" is presented and the query SELECT count(*) FROM list; is given as the answer in the SQL statement. This will calculate the number of students in the table.



Categories related to this article
![Libra] A New Multimo](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2025/libra-520x300.png)




