![Brain2Music] Automatic Music Generation Based On Brain Information](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/December2023/brain2music.png)
Brain2Music] Automatic Music Generation Based On Brain Information
3 main points
✔️ Automatic music generation based on human brain activity
✔️ fMRI measurement of human brain activity listening to music
✔️ Using MusicLM architecture
Brain2Music: Reconstructing Music from Human Brain Activity
written by Timo I. Denk, Yu Takagi, Takuya Matsuyama, Andrea Agostinelli, Tomoya Nakai, Christian Frank, Shinji Nishimoto
(Submitted on 20 Jul 2023)
Comments: Preprint; 21 pages; supplementary material: this https URL
Subjects: Neurons and Cognition (q-bio.NC); Machine Learning (cs.LG); Sound (cs.SD); Audio and Speech Processing (eess.AS)
code:
The images used in this article are from the paper, the introductory slides, or were created based on them.
Introduction
In this joint research by Google, Osaka University, and others, Brain2Music, a "model for generating music based on brain activity," has been developed. The generated music can be listened to on the following GitHub page.
https://google-research.github.io/seanet/brain2music/
Specifically, the technique uses fMRI (functional magnetic resonance imaging) to measure "brain activity of subjects listening to music" and uses the brain activity data for music generation. This research is likely to be a stepping stone to the development of a model that can output imagined melodies in the future, as well as how the brain interprets music.

Incidentally, Google's Text-to-Music model, MusicLM, is used for Brain2Music in this study. First, let's briefly review MusicLM.
MusicLM Overview
MusicLM is a Text-to-Music model that takes such text as input and generates music according to that text. For example, as shown in the figure below, if you enter the prompt "Hip hop song with violin solo," it will generate "hip hop" music with a solo violin part.

https://arxiv.org/abs/2301.11325
The process of music generation by MusicLM is as follows
- MT generated by MuLan music encoder
- Generate S with decoder-only Transformer subject to MT
- Generate A with decoder-only Transformer subject to MT and S
- Pass A through the SoundStream (neural vocoder) decoder
The meanings of the symbols included above are also described below.
- MA: Token obtained by MuLan's music encoder
- MT: Token obtained by MuLan text encoder
- S: token representing the "meaning of music" obtained by w2v-BERT
- A: Token representing the "voice" obtained by SoundStream
The key here is a module called "MuLan". This is a text-music contrast learning model. The architecture of MuLan is shown in the figure below.
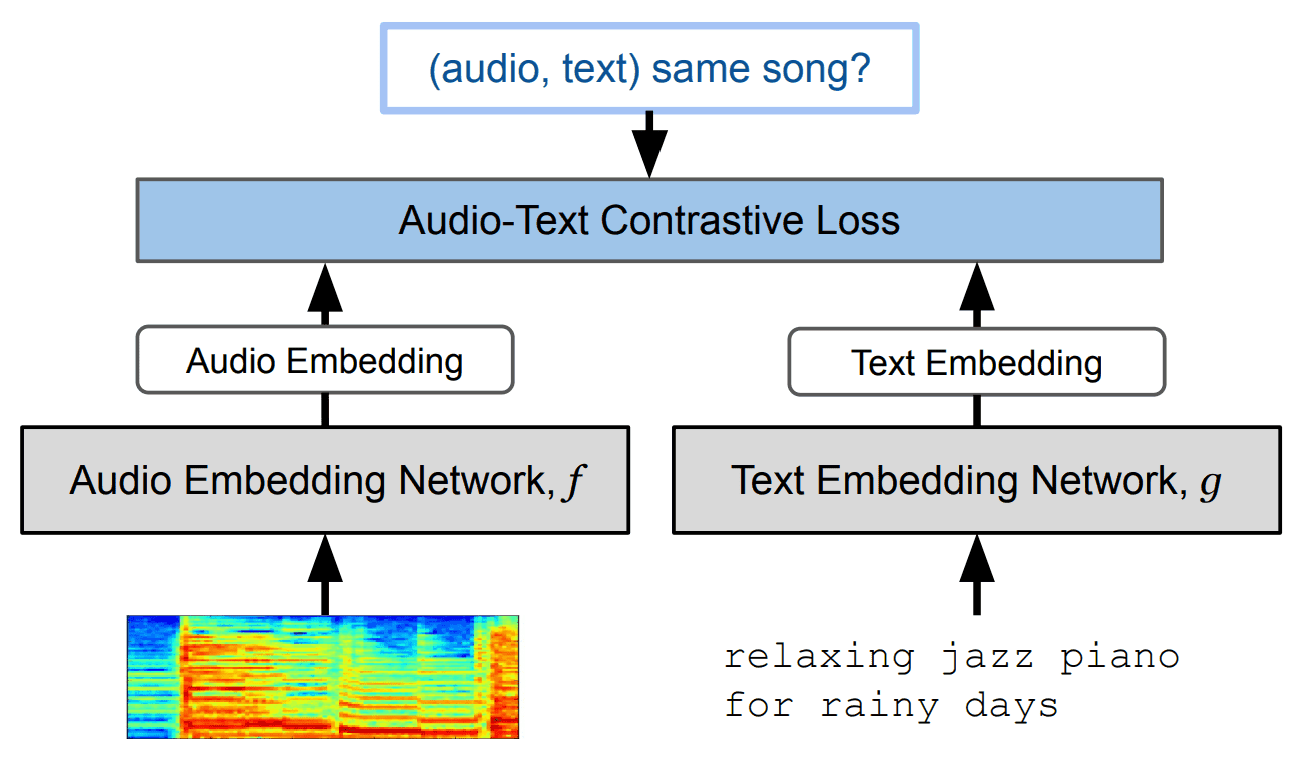
https://arxiv.org/abs/2208.12415
This model can be used to generate a "representation of music that most closely matches the content of the text" when the text is input. Here, in this study, "BERT" is used for MuLan's text encoder and "ResNet-50" is used for the audio encoder.
The reason for using a model for images in an audio encoder is that spectrogram image data is used as music data, which requires image processing.
A method of creating music from brain information
The architecture of Brain2Music is almost identical to that of MusicLM; it differs from MusicLM in that it uses fMRI-acquired brain information as input.
First, let's look at fMRI.
What is fMRI (functional magnetic resonance imaging)?
fMRI is a technique for non-invasively observing brain activity by detecting changes in blood flow in the brain. It uses a signal that depends on the oxygen level in the blood (BOLD signal) to visualize the spatial distribution of brain activity.

fMRI is widely used to study activity in regions of the brain associated with human emotion and cognitive function.
fMRI has played a particularly important role in studying responses to music. Music triggers a wide variety of processing in the brain and has been used for research in areas as diverse as emotional response, memory, and attention. This allows us to explore the relationship between brain activity and music perception and to better understand the brain's response to music.
Data-set
The dataset used in this study is the "Music Genre Neuroimaging Dataset" preprocessed from the work of Nakai et al. (2022). This dataset contains data on brain activity when randomly sampled music from 10 different genres (blues, classical, country, disco, hip-hop, jazz, metal, pop, reggae, and rock) was played.
In the end, 480 cases were included for training and 60 for testing.
Brain2Music Architecture
The Brain2Music architecture is shown in the figure below.
The new approach uses fMRI technology to capture brain activity while the subject is listening to music, and then uses that data to predict the embedding of the music and further reconstruct it.
The flow of music generation is as follows
- Receive fMRI response R as input
- Predicting MuLan's Music embedding with R as explanatory variable
- Music search or music generation based on music embedding
First, we take the fMRI response R as input and predict the MuLan music embedding. If the music embedding is T, then we predict T by L2-regularized regression with T=RW (W is the training parameter).
Music is created from brain information by using the above T to perform music search OR music generation.
・Music Search
In the music search, the music embedding for 106,574 songs in the music database (for the first 15 seconds) is calculated in advance. It then predicts the similarity between the T predicted earlier and the music embedding in the music database, and extracts the songs with the greatest similarity from the database.
・Music Generation
Music generation uses T to generate music through the following MusicLM-based architecture.

This one is almost identical to the conventional MusicLM. The difference is that the MuLan embedded T ("High-level (MuLan)" in the figure) is obtained using fMRI responses.
Evaluation experiment
Comparison of accuracy of music embedding predictions
As we saw in the Methodology section, generating music from fMRI data requires, as an intermediate step, the prediction of music embeddings. In doing so, comparative experiments were conducted to see which of the following four embeddings would perform better.
- SoundStream-avg
- w2v-bert-avg
- MuLantext
- MuLanmusic
In this experiment, we predict each of the above embeddings from fMRI in the regression equation T=RW and compare their performance. Results are as follows.

The results show that the best performance is obtained for MuLanmusic. Therefore, Brain2Music will use fMRI for " MuLanmusic prediction".
Music Search vs. Music Generation
The following figures are spectrogram images of real and retrieved/generated music for subjects to listen to. In short, the spectrograms of the real music and the retrieved/generated music should be similar.

The following figure shows a quantitative comparison of how accurately the music was reproduced using fMRI data. It assesses the actual prediction performance between a random prediction (Chance) and an ideal prediction (Oracle).

Each of a~c represents the following
- a: Accuracy in different music embeddings
- b: Degree of similarity between the original and reconstructed music
- c: Accuracy in each genre
From the above diagram, we can say the following
- Using MuLan as encoder is more accurate
- Music generation by MusicLM is more accurate.
- Brain2Music can generate all genres with the same degree of accuracy
fMRI signal prediction task from music embedding
This task is to predict the fMRI signal using different music embeddings occurring within MusicLM and compare their accuracy. A regression model with L2 regularization is used here.
・MuLanmusic vs w2v-BERT-avg
First, we build encoding models that predict voxel activity (brain activity) from music-derived embeddings ( MuLanmusic and w2v-BERT-avg) and compare how these are represented differently in the human brain.
MuLanmusic and w2v-BERT-avg are both models that take audio as input and output an embedding that represents the meaning of the music.
The above results show that both models predicted activity in the same brain regions. The region shown as active corresponds to the auditory cortex.
Thus, both embeddings are in the auditory cortex and have been shown to correlate to some degree.
・MuLanmusic vs MuLantext
We then build an encoding model that predicts the fMRI signal using music-derived MuLanmusic and text-derived MuLantext embeddings. To obtain the MuLan text embedding, the text caption corresponding to each music piece in the dataset is input to the MuLan text encoder.

The above results show that again, in both models, the response is predicted in the auditory cortex.
Generalization to other genres
Here we are testing how well the model generalizes to "music genres that were not used during training". The figure below shows the accuracy of the model trained using all data ("full") and the accuracy of the model trained with genres not included in the training data.

This comparison shows that the model has a certain generalization performance for music genres not used during training.
Summary
The following three issues have been identified as challenges in this study
- Limitations of the amount of information that can be extracted from fMRI data using linear regression
- Limitations of what music embedding (MuLan) can capture
- Limitations of music search or generation capabilities
In this study, we evaluated where and to what extent acoustic features of music are represented in the human brain.
In the future, it may be possible to generate music from pure imagination. Such technology, if realized, could, for example
- A new age music platform that embodies imaginary melodies
- Services that capture individual musical sensibilities and support a more sensory understanding of music
We will continue to keep an eye on the field of music generation with a biological perspective.



Categories related to this article
![Libra] A New Multimo](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2025/libra-520x300.png)




