
Implicit Behaviral Cloning : A New Formulation Of Imitation Learning! Robot Complex Behavior!
3 main points
✔️ Proposed a new formulation Implicit Policy in Imitation Learning
✔️ Addresses multimodal and discrete cases that conventional Explicit Policy cannot handle
✔️ Demonstrates higher performance than conventional methods in real experiments
Implicit Behavioral Cloning
written by Pete Florence, Corey Lynch, Andy Zeng, Oscar Ramirez, Ayzaan Wahid, Laura Downs, Adrian Wong, Johnny Lee, Igor Mordatch, Jonathan Tompson
(Submitted on 1 Sep 2021)
Comments: Published on arxiv.
Subjects: Robotics (cs.RO); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:

The images used in this article are from the paper, the introductory slides, or were created based on them.
Introduction
In recent years, much research has been conducted on robot learning, and many results have been achieved. One of the most popular methods is imitation learning. This is a method to learn strategies from data obtained from actual robot operations by experts such as humans. The advantages of imitation learning include the fact that it does not require the design of a reward function and the fact that it does not need to consider modeling errors, which can be a problem in sim2real, because it can use data obtained by directly manipulating the robot. Due in part to these advantages, properly tuned imitation learning-based strategies have been shown to achieve successful behavior in the real world and are being actively studied.
Please watch this video, in which the author actually explains the contents of this study, for a better understanding.
Existing Research and Issues
Explicit Policy
A commonly used method for imitation learning is called Explicit Policy. This is a method for modeling the policy that generates the robot's behavior from an observation as a continuous function, represented as follows.  θ is obtained to minimize the error between, for example, the trajectory given by a human and the policy trajectory.
θ is obtained to minimize the error between, for example, the trajectory given by a human and the policy trajectory.
However, it is known that this Explicit Policy has difficulty in addressing the following two issues
Discontinuities
This refers to the characteristics of tasks that include discrete cases of action sequences, etc. The following image shows a task in which a blue block is inserted into a small box. The following image shows a task to insert a blue block into a small box. To realize this task, it is necessary to discretely switch action sequences by pushing the block from left to right and then from the back to the box side. However, Explicit Policy, which is continuous modeling, cannot express this. 
Multimodalities
This is the case when there are multiple means of achieving an objective. In the image below, the task is to separate the blue and yellow blocks and place them in two boxes, but to achieve the goal, the blocks to be moved can be either blue or yellow, making the task multimodal. This makes it difficult to deal with such a multimodal task. 
Proposed Method
In response to the challenges of existing research, this paper reformulates imitation learning in a different way, which is the Implicit Policy below.
Implicit Policy
Specifically, it introduces an energy-based model (EBM). In contrast to the conventional method of measuring the proximity to the target trajectory, Explicit Policy learns the EBM for observations and actions as follows.  In the EBM, the probability of selecting a certain action in a given state can be expressed as follows. The probability of choosing a certain action in a given state can be expressed as follows. where z ( x, θ ) is a normalization constant.
In the EBM, the probability of selecting a certain action in a given state can be expressed as follows. The probability of choosing a certain action in a given state can be expressed as follows. where z ( x, θ ) is a normalization constant.
 However, since it is difficult to compute z for all y, a sampling approximation is made as follows. The loss function is computed with the negative log-likelihood of this probability, and learning and inference are performed by these.
However, since it is difficult to compute z for all y, a sampling approximation is made as follows. The loss function is computed with the negative log-likelihood of this probability, and learning and inference are performed by these. 
Special characteristic
Let us review the properties obtained by the above formulation. First, the following results show that discreteness is addressed. The problem is to represent a discontinuous function in the form of teacher data correctly. 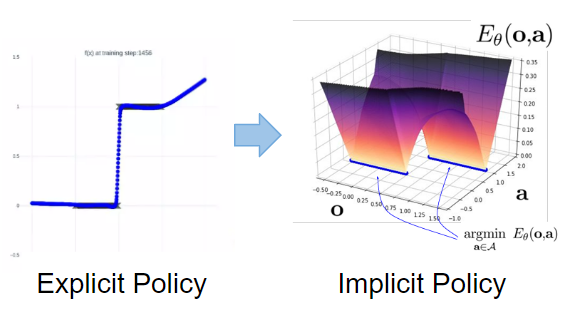 In the figure below, O represents the sample and the problem setup for learning the function. In this problem, there are multivalued and multimodal functions that are difficult to approximate with previous methods.
In the figure below, O represents the sample and the problem setup for learning the function. In this problem, there are multivalued and multimodal functions that are difficult to approximate with previous methods. 
Experiment
Implicit Policy is used to perform actual robot control tasks. Observations include image input, robot joint angles, angular velocity, and position and posture, and actions include position control commands for joint angles and velocity control commands.
For the results of the experiment, please click here to see the movie.
Simulation Experiment
Comparisons are made with conventional methods using a variety of simulation environments and tasks. Basically, the performance of the method significantly outperforms the conventional method in almost all tasks.
All of these tasks involve discreteness and multimodality, and the results seem to confirm the strength of Implicit Policy in dealing with these characteristics. 
Experimental equipment
The manipulators are used to perform several tasks to move blocks on the actual device. First, the task of placing the red and green blocks into either goal, as shown in the left image, achieved a success rate of approximately 90% with the new method, compared to only about 55% with the conventional method. This task has a strong multimodal nature, and we have confirmed that our method can cope with the multimodal nature inherent to Implicit Policiy. Next, in the task of inserting a block that needs to be adjusted by 1mm, as shown in the center of the image, it is necessary to switch action sequences discretely, as shown in the figure. In this task, too, the Implicit Policy feature outperforms conventional methods by a wide margin, recording a success rate of approximately 80%. Finally, we are experimenting with a task in which many blue and yellow blocks are prepared and placed into the goal separately, as shown in the image on the right. The success rate of approximately 50% was achieved even for such a complex combination of discrete and multimodal tasks, confirming that the robot is able to generate new actions by combining learned actions. In addition, the robot immediately responded to human intervention to move the block and put it back in the goal, confirming that the strategy obtained is very robust. 
Summary
In this paper, we focus on discreteness and multimodality that cannot be handled by the conventional formulation of imitation learning (Explicit Policy), and propose a new formulation (Implicit Policy) that can handle them. Experiments on both simulation and real machines showed that the new formulation significantly outperforms the conventional method and is very robust on real machines.
One area for improvement is that the computational cost has increased compared to the conventional Explicit Policy, so if the computational cost can be further reduced, it may be possible to perform more dynamic tasks.
For the author, it seems that a new door has been opened for imitation learning, and he is very much looking forward to its future development.



Categories related to this article




![[HumanoidBench] Simu](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/June2024/humanoidbench-520x300.png)

