
ControlNet Revolutionizes Diffusion Modeling By Allowing Stable Diffusion's AI Characters To Be Directed Into Specific Poses!
3 main points
✔️ ControlNet is a neural network used to control large diffusion models and accommodate additional input conditions
✔️ Can learn task-specific conditions end-to-end and is robust to small training data sets
✔️ Large-scale diffusion models such as Stable Diffusion can be augmented with ControlNet for conditional inputs such as edge maps, segmentation maps, key points, etc.
Adding Conditional Control to Text-to-Image Diffusion Models
written by Lvmin Zhang, Maneesh Agrawala
(Submitted on 10 Feb 2023)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Graphics (cs.GR); Human-Computer Interaction (cs.HC); Multimedia (cs.MM)
code:

The images used in this article are from the paper, the introductory slides, or were created based on them.
What's so great about it compared to previous studies?
This paper was published on February 10, 2023, and a few days later, an extension for WebUI for Stable Diffusion was implemented on GitHub and quickly became a worldwide phenomenon. This paper is a great success because it makes it easy to have characters assume specific poses when generating images with AI.
AI Illustration has completely changed the game with the introduction of Controlnet. The ability to color from line drawings is a really great feature! The key is that you can either "just keep your lines as they are" or have the AI correct them.
- Io Kenki @Studio Masakaki (@studiomasakaki) March 5, 2023
This one doesn't specify colors, but if you specify "red hair, black clothes, yellow eyes" pic.twitter.com/V0flFRYmqp
Introduction
This paper introduces ControlNet, an end-to-end neural network architecture that controls a large-scale image diffusion model to learn task-specific input conditions.
ControlNet clones the weights of a large diffusion model into trainable and locked copies and connects them using a unique type of convolution layer called "zero convolution". In this paper, we demonstrate that ControlNet, even when trained on a small dataset on a personal computer (a single Nvidia RTX 3090 Tl), can produce competitive results for a specific task that are comparable to commercial models trained on a large computational cluster with terabytes (TB) of GPU memory and thousands of GPUs We have demonstrated that our models can produce competitive results comparable to commercial models trained on large computational clusters with terabytes (TB) of GPU memory and thousands of GPUs for certain tasks.
Large-scale text-to-image models can be used to generate visually appealing images by simply entering simple text prompts. However, this raises the question of whether this method is effective for specific image processing tasks with a well-defined problem set, such as understanding object shape and orientation. The paper suggests that certain tasks often have small data sets and may require fast learning methods and pre-trained weights to optimize large models within the available time and memory space. Furthermore, a variety of image processing problems involve diverse forms of problem definition, user control, or image annotation, which may require learning solutions rather than procedural human-directed methods. This is where ControlNet is proposed.
ControlNet divides the weights into learnable and locked copies, with the locked document retaining the original weights and the learnable copy learning conditional controls on task-specific data sets. to learn on datasets of different sizes and can learn as fast as fine-tuning a diffusion model using a unique type of convolutional layer called ZERO CONVOLUTION.
Proposed Method
1. ControlNet Details
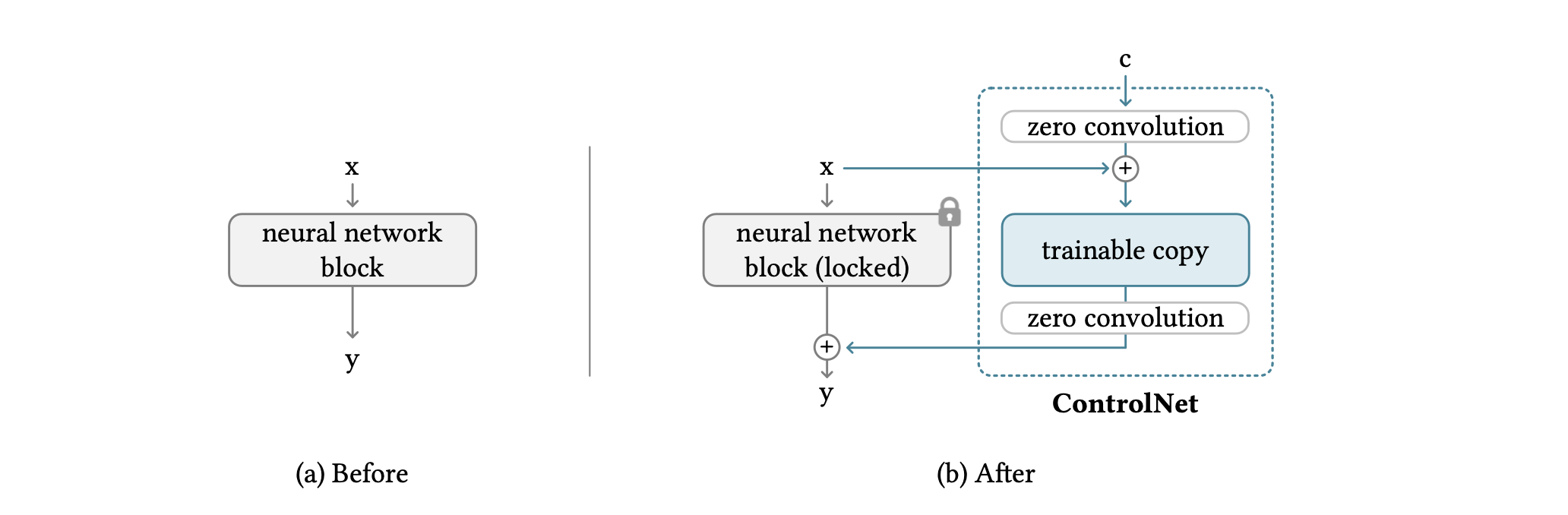
ControlNet allows you to manipulate the input conditions of a neural network block to control the behavior of the entire neural network. In this context, a "network block" is commonly used to construct neural networks. For example, a "resnet" block or a "transformer" block.
The network blocks are connected by a particular convolutional layer called "zero convolution," which allows for a higher degree of control while still preserving each layer of the neural network. Zero convolution is a 1 × 1 convolution initialized with zero layers, with a structure containing both trainable copies and the original parameters. Also, the gradient computation of zero convolution is straightforward: the gradients of the weights and biases of the neural network blocks are unaffected because the gradients for a given input are zero. This makes zero convolution a uniquely connected layer that grows from zero to optimal parameters through learning. (1) is the equation before the ZERO CONVOLUTION connection and (2) is the equation after the connection.

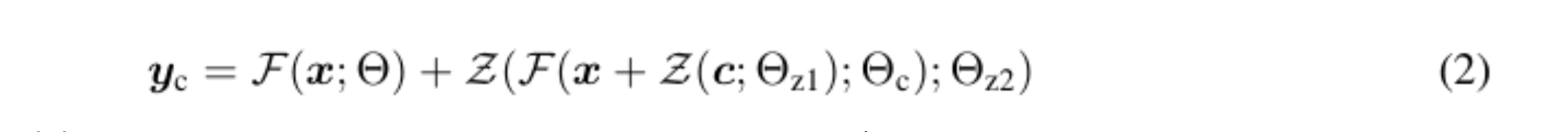
2. ControlNet in the image diffusion model
We will discuss the use of ControlNet to control a large text-to-image diffusion model called Stable Diffusion, which is 25 blocks in a U-net. The model uses OpenAI CLIP to encode text and positional encoding to encode the time steps of the diffusion. To train the model efficiently, the entire dataset of 512x512 images is preprocessed into 64x64 "latent images" like VQ-GAN. This requires ControlNet to transform the image-based conditions into a 64x64 feature space to match the convolution size.
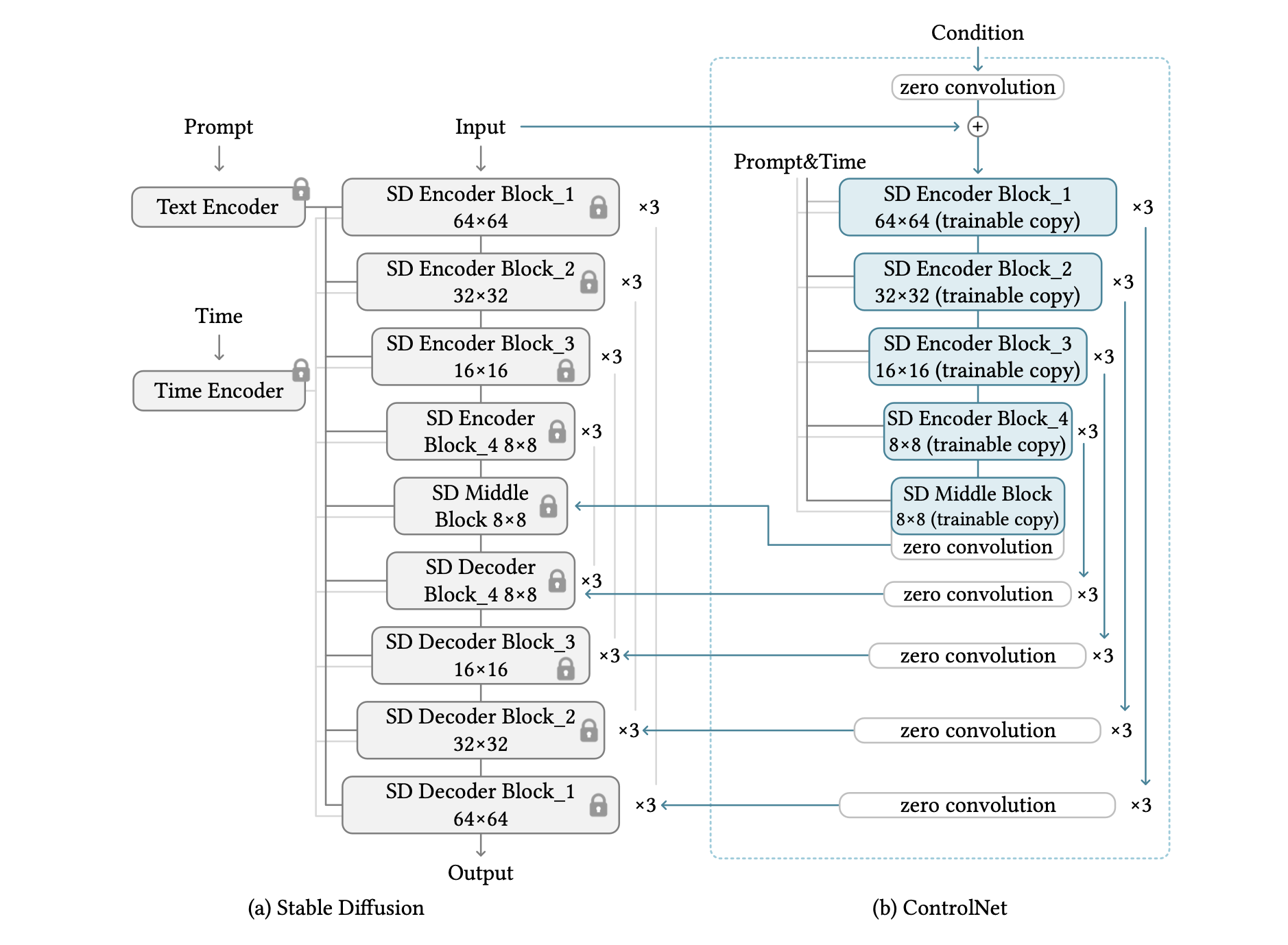
The figure above shows ControlNet being used to control each level of the U-net. This architecture is computationally efficient, saves GPU memory, and can likely be used for other diffusion models. Because the original weights are locked, no gradient computation of the original encoder is required during the learning process. This speeds up training and saves GPU memory by avoiding half of the gradient calculations of the original model. (tested on an Nvidia A100 PCIE 40G).
3. Learning the model
Image diffusion models progressively noise an image by adding noise to the pixel or latent image space; Stable Diffusion uses latent images for training. These models learn to predict the noise that will be added to an image based on conditions such as time steps, text prompts, and task-specific conditions.
During training, 50% of the text prompts are randomly replaced with empty strings to improve the model's ability to recognize semantic content from input control maps such as Canny edge maps and human scribbles. This is to allow the model's encoder to learn more semantic content from the input control map as an alternative when no prompt is displayed.
experimental results
Experimental setup
In this experiment, all results were obtained with the CFG scale set at 9.0. DDIM is used as the sampler. By default, 20 steps are used. Three types of prompts are used to test the model.
- No prompt: Use the empty string " for the prompt.
- Default prompt: Since Stable diffusion is inherently trained on prompts, an empty string is an unexpected input for the model, and SD tends to generate random texture maps if no prompt is provided. A better setup is to use a meaningless prompt such as "an image", "a nice image", or "a professional image". In this experiment, "a professional, detailed, high-quality image" is used as the default prompt.
- Automatic prompts: to test the maximum quality of a fully automated pipeline, generate prompts using the results obtained in the "default prompts" mode, using automatic image captioning methods (e.g. BLIP [34]). The generated prompts are diffused again.
- User prompt: The user gives the prompt.
Qualitative Results
In this paper, Figures 4~15 present qualitative results. We pick up a few results here.



causal inference
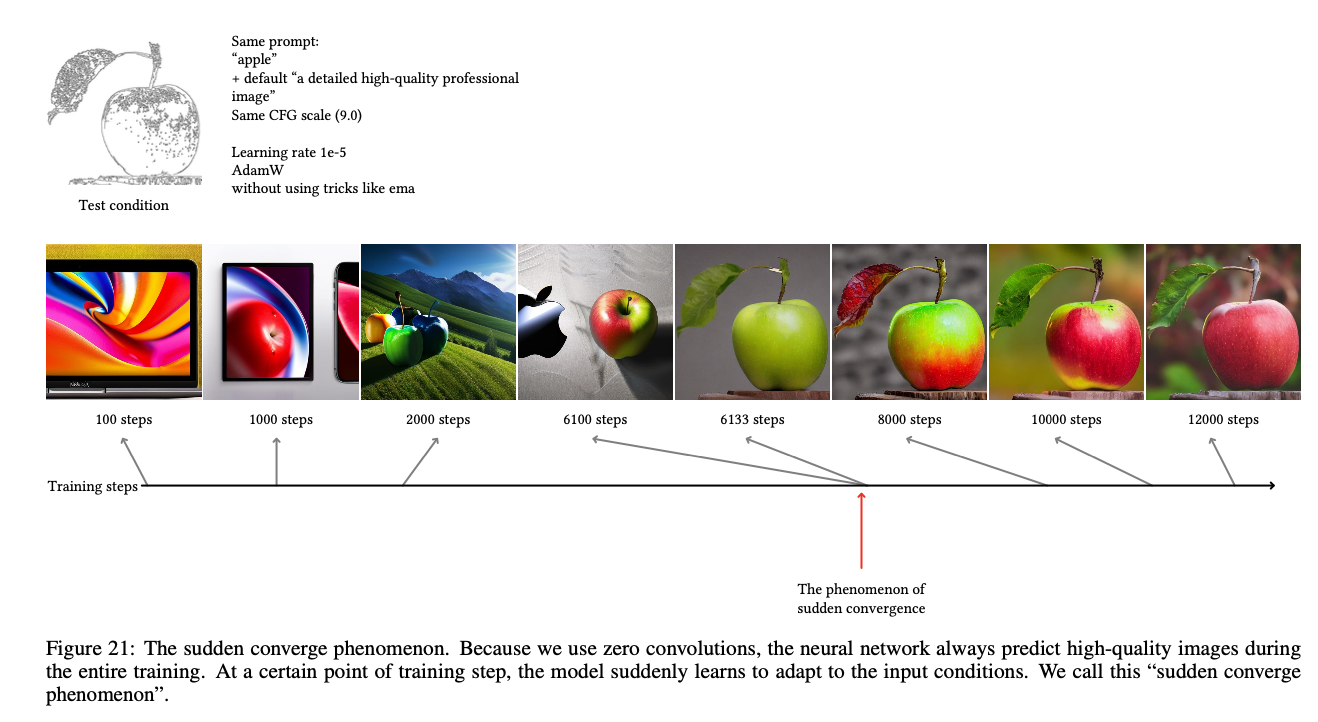
Figure 21 points out the "sudden convergence phenomenon" where the model suddenly follows the input phenomenon.
Are there any challenges?
If the model incorrectly perceives the meaning of the input image, it seems difficult to eliminate the negative effects even with strong prompting. In the image below, the prompt indicates "a view of a farm from overhead," but the AI model incorrectly recognizes the line drawing as "a glass of water.

summary
The paper proposed a neural network architecture, ControlNet, for controlling diffusion models; ControlNet supports additional conditions on diffusion models and can be robustly trained on small training data sets. ControlNet's learning rate is comparable to the fine-tuning of the diffusion model, and it can be trained on personal devices. In addition, ControlNet can be used to enrich methods for controlling large-scale diffusion models and potentially make related applications easier.



Categories related to this article

