Two Transformers Can Work Together To Make One Strong GAN!
3 main points
✔️ The world's first pure transformer-based GAN
✔️ A memory-friendly generator and a new set of learning techniques for training transformed GANs
✔️ Achieved competitive results with CNN-based GANs and new SOTA on STL-10 benchmark
TransGAN: Two Transformers Can Make One Strong GAN
written by Yifan Jiang, Shiyu Chang, Zhangyang Wang
(Submitted on 14 Feb 2021 (v1), last revised 16 Feb 2021 (this version, v2))
Comments: Accepted to arXiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
First of all
Since their inception, Generative Adversarial Networks (GANs) have improved a lot because of the evolution of training methods, loss functions, and model backbone. Today's state-of-the-art GAN models are usually based on a Convolutional Neural Network (CNN) backbone. These models are able to generate rich and diverse images with more stable training than the earlier GAN models. CNNs have become the center of image GANs and although there has been some work done to integrate self-attention into the network, CNNs still remain at the core. On the other hand, transformers have found their way into a variety of tasks such as Natural Language Processing, computer vision, speech processing, and 3D Point Cloud Processing. So, it is natural to wonder: How would a transformer-based GAN, free of CNNs perform?
We try to explore the answer to that question in this paper and the results are pretty exciting. We train GAN models which are purely based on transformers. In order to make the performance of these models comparable to SOTA GANs, we use two new training methods: locality-aware initialization, and multi-task co-training along with data augmentation. Our model TransGAN was also able to set the new SOTA in the STL-10 benchmark.
Why Transformer Over CNN?
It is well known that CNNs work very well at the local pixel-level but are weaker when it comes to capturing global features. So, they need to be stacked to form deep networks to capture global features effectively. CNNs also exhibit spatial invariance because the same weight is shared throughout the image. On the other hand, transformers capture global features pretty well which is the reason why infusing them with CNNs was found to be beneficial in prior works. With their success in a variety of diverse tasks, transformers are potentially universal function estimators and could simplify the complex CNN-based pipelines in computer vision.
A Journey Towards GAN with Pure Transformers
At first, we will start with a simple model for both generator and discriminator. Based on the challenges faced by the model, we make changes accordingly.
Vanilla TransGAN
The TransGAN is made up of the Transformer Encoder made up of multi-headed self-attention followed by an MLP with GELU non-linearity. Layer normalization is used before both parts along with residual connections. One challenge with using transformers for images is that even a low-resolution image 32x32 can result in a long sequence of length 1024 which consumes a lot of memory.
![]()
In order to manage such large sequences in the generator, the input sequence is gradually upscaled and the dimension is gradually reduced until the target resolution is reached(32x32x3 in the above diagram). At each step, the 1D sequence is converted to a 2D feature map (HxWxC) on which we apply pixelshuffle converting the shape to (2Hx2WxC/4). So, the width and height double while the dimensions reduce to 1/4th at each upsampling step. Finally, when the desired shape is reached, the dimension is transformed to C=3 (HtxWtx3).
For the discriminator, we convert the input image(HxWx3) into 8x8 equal patches(Only 9 patches are shown in the figure as an example). Each of these 8x8=64 patches is flattened to form a sequence of 64 "words" (9 in the case of the above diagram) with embedding dimension 'C'. The [cls] token is appended at the beginning and the entire sequence is passed through transformer encoder layers. As shown in the figure, only the encodings corresponding to [cls] token are used by the classification head to predict if the image is real or fake.
Improving Vanilla TransGAN
The TransGAN was compared to the AutoGAN(CNN-based) by trying all types of combinations of discriminator(D) and generator(G) from the two models. The results on CIFAR-10 are shown below:
![]()
The pure transformer GAN is still behind although the transformer generator and CNN discriminator combination work very well. From the results, the transformer discriminator still seems to be confused, so we decided to help it by increasing the training data with data augmentation. The following shows the results of TransGAN, and other SOTA models before and after data augmentation trained on CIFAR-10.
![]()
TransGAN seems to benefit more from data augmentation than CNN-based GANs. But it is still not good enough. Let us furnish TransGAN some more with the following techniques.
Multi-Task Co-Training (MM-CT)
![]()
The above diagram shows multi-task co-training(MM-CT). MM-CT is a self-supervised task that allows stabilizing GAN training. In this method, we take the training images and downsample them to form low-resolution images (LR). These LR images are passed in the intermediate(2nd) stage of the network and the model is trained to obtain a high-resolution image. In addition to the standard GAN loss, we add another loss λ ∗ LSR to it where LSR is the mean-squared error loss (λ was empirically found to be 50). Although the two tasks are unrelated, it helps the generative model to learn image representations.
Locality-aware Initialization
CNNs are inherently good at capturing local image features and thereby generating smoother images due to their inductive image biases. Transformers have more learning flexibility and the challenge is to get them to learn the convolutional structures in images like CNNs can. This can be done by modifying the training procedure as follows.
![]()
In order to enable self-attention to learn lower-level image structure, we use locality-aware initialization. As shown in the above diagram, we begin training by masking most of the pixels and allowing only a few unmasked neighboring pixels to interact at first. Then as training continues, the receptive field is slowly increased until no pixel is masked at all. This allows the generator to pay attention to local detail and form finer images. Therefore, the local details are prioritized earlier in training, followed by broader non-local interactions in the later stage of training.
MM-CT and locality-aware initialization greatly improve the performance of TransGAN as shown in the following table.
![]()
TransGAN. Scale-up and Evaluation
Finally, the vanilla TransGAN trained with the other techniques mentioned above is ready to be scaled up. The results of the model with different depths (number of encoder blocks in each step) and embedding sizes are shown below.
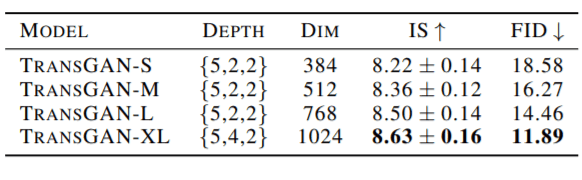
TranGAN was also able to set the new state of the art on the STL-10 dataset. Results are shown below:
![]()
TranGAN was able to show new ground on the STL-10 dataset as well. The results are as follows.
![]()
In case you are wondering how the generated images look like. Here is a sample of TransGANs trained on three different datasets.

Conclusion
TransGAN works very well and is another example of the simplicity and universality of transformers. This work could be a beginning to several interesting future works on pure transformer GANs: generating higher-resolution images, pretraining the transformers, using stronger attention forms and conditional image generation are only a few of them. For further information refer to the original paper. Long Live Transformers!
Video explanation is recommended here.



Categories related to this article



![[MusicLM] Text-to-Mu](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/musiclm-520x300.png)


