
Convolution Vs Transformer! To The Next Stage! Vision Transformer, A New Image Recognition Model
3 main points.
✔️ A new image classification model using the Transformer
✔️ The input is characterized by segmenting the original input image and creating patches
✔️ Records result equal to or better than state-of-the-art CNN models
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
written by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby
(Submitted on 22 Oct 2020)
Comments: Accepted at arXiv
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)


first of all
Most of the existing image classification models have used convolutional neural networks (CNNs). However, the model presented this time does not use CNN at all, and is a model constructed using only a Transformer. The name of the model is Vision Transformer (ViT).
The transformer has now become a fact standard in the field of natural language processing since it was first announced in 2017, but its application to the field of image processing has been limited. We summarize how we have successfully adapted Transformer to the image classification task and what its accuracy is of interest.
Transformer
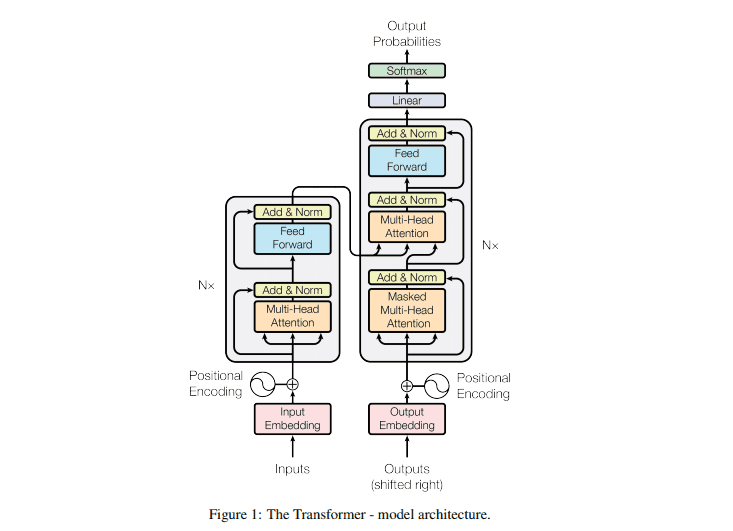
Source: Attention Is All You Need
Transformer originally attracted attention for its own scalability. Normally, when a model is enlarged, learning may not proceed, but the Transformer has the feature that it can learn even when the model is enlarged. In addition, various studies have been conducted to improve the computational power of the Transformer.
However, the Transformer is good at sequence data, i.e. data with continuity, such as text. Moreover, Transformer calculates the similarity between elements of the input sequence, so the disadvantage of Transformer is that the number of elements to calculate becomes huge if you use it for each pixel of an image. (For example, an image with 224x224 pixels would require (224x224 )2 = 2,517,630,976 calculations.
To read more,
Please register with AI-SCHOLAR.
OR


Categories related to this article


![[MusicLM] Text-to-Mu](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/musiclm-520x300.png)


