Finally, A New Activation Function, Mish, Has Been Created That We Expect!
3 main points
✔️ A new activation function, Mish, was proposed after ReLU and Swish.
✔️ It overwhelmed ReLU and Swish with MNIST and CIFAR-10/100.
✔️ The GitHub report of the paper author's implementation is very easy to use.
Mish: A Self Regularized Non-Monotonic Neural Activation Function
written by Diganta Misra
(Submitted on 23 Aug 2019 (v1), last revised 2 Oct 2019 (this version, v2))
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Neural and Evolutionary Computing (cs.NE); Machine Learning (stat.ML)
Paper Official Code COMM Code
All images used in this article are taken from the paper.
Introduction
Neural networks are widely used in image recognition and natural language processing. It can also be used for such a neural network's strength lies in its ability to represent nonlinear functions, and the activation function is what makes the nonlinear function possible. Typical activation functions include Sigmoid and ReLU (2011), among others, in 2017 as the successor to ReLU. Swish. is now available. But as you know, ReLU still reigns as the de-facto standard. Mish, introduced in 2019 to put an end to that trend in the world of activated functions, has surpassed ReLU and Swish in a variety of tasks, and its implementation is available on GitHub so you can easily try it out.
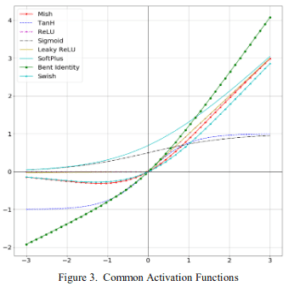
This article will explain the paper in the following sequence.
- Mish Commentary
- Results of Mish's experiment
- Conclusion.
1. Mish
Expressing the Mish function as an expression, $f(x)=x\cdot \mathrm{tanh}(\mathrm{softplus}(x))$
and where $\mathrm{softplus}(x)=\ln{(1+e^x)}$. The following is represented in the diagram.
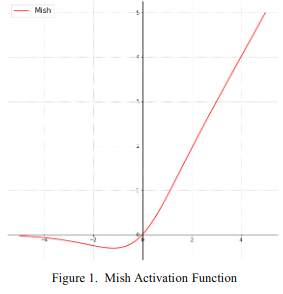
When you use it, just put the Mish function in place of the one you are using, such as ReLU. It's easy. However, they say it's better to use a slightly smaller learning rate than ReLU. There are five properties of the Mish function that are listed in the paper
- No limit
- Sigmoid, for example, is saturated at 1 and its slope is zero, which slows down the learning process, but Mish does not saturate, which avoids slowing down the learning process.
- with a lower limit
- We can apply strong regularization.
- Negative value.
- Unlike ReLU, negative values also remain
- ∞Functions are continuous up to infinite derivative
- ReLU is not continuous after differentiation, which may cause unexpected problems for the optimizer with gradients, but Mish is continuous up to infinite derivative, so it will be fine.
- Smooth output landscape by Mish
- The loss function is also smoother and easier to optimize.
2. the results of Mish's experiment
2.1 MNIST
We are experimenting a lot, so I'll give you a quick explanation. Basically, it compares performance to Swish (and ReLU). It says that the network uses a normal CNN with 6 layers.
2.1.1 Layer depth
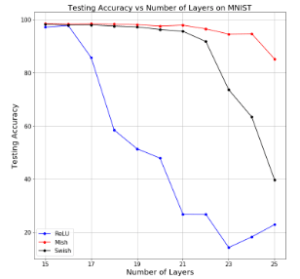
This is the accuracy when the layer of the model is deepened (without using a skip connection). You can see that Mish(red) is stable even if the model layer is deepened.
2.1.2 Robustness
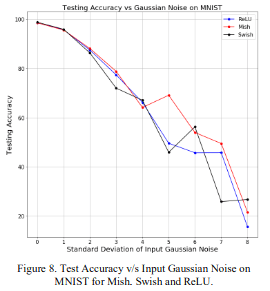
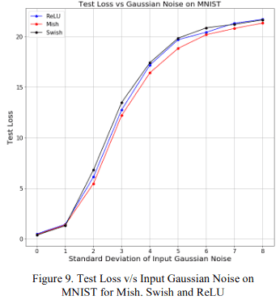
The top panel is the accuracy and the bottom panel is the loss. The horizontal axis is the standard deviation of the Gaussian noise to be added to the input, the larger the noise, the greater the value that can be taken. Even as the noise increases, Mish shows high accuracy and low loss.
2.1.3 Various optimization algorithms
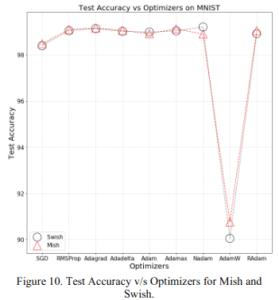
This is the accuracy when using various optimization algorithms such as SGD and Adam; it's not as good when using Nadam, but otherwise Mish performs about the same or better than Swish in every optimization algorithm.
2.1.4 Learning Rate Dependence
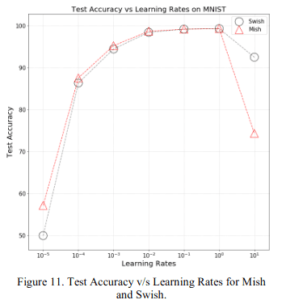
These are the accuracies for various learning rates. For learning rates of $[10^{-5}, 10^{-1}]$, Mish has the same or better accuracy than Swish. Mish is better than Swish, especially when the learning rate is small.
2.1.5 Various initial values
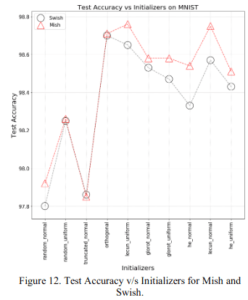
These are the accuracies for various initial values such as random initial values and the initial values. Again, Mish achieves about the same or better accuracy than Swish.
2.1.6 Various regularizations
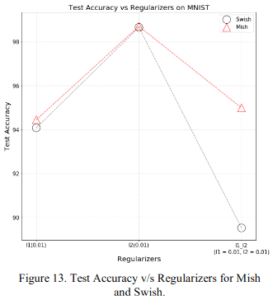
These are the accuracies when using L1 regularization, L2 regularization, and L1-L2 regularization. Again, as before, Mish performs as well or better than Swish.
2.1.7 Dropout Rate Dependence
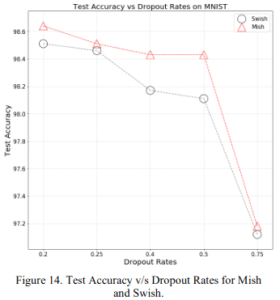
It shows the difference in accuracy relative to the dropout rate. You can see that Mish is better than Swish in both cases.
2.1.8 Layer width
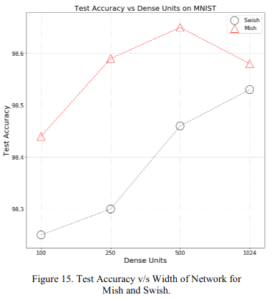
The number of neurons per layer, i.e., the accuracy relative to the width of the layer, Mish is significantly better than Swish.
2.2 CIFAR-10
From here, we use CIFAR-10 as a dataset. The network is an ordinary 6-layer CNN as well as MNIST.
2.2.1 Various optimization algorithms
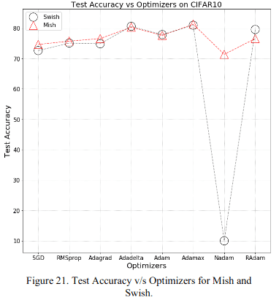
This is the result of using various optimization algorithms. As usual, Nadam doesn't perform well to begin with, but you can see that Mish is as good or better than Swish.
2.2.2 Learning Rate Dependence
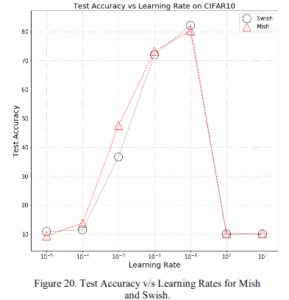
Mish performs as well or better than Swish in terms of learning rate.
2.2.3 Various initial values
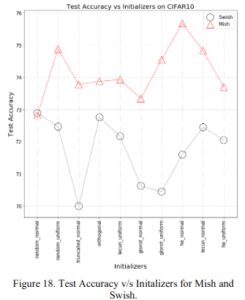
You can see that Mish is significantly better than Swish at every initial value, except for random_normal.
2.2.4 Various regularizations
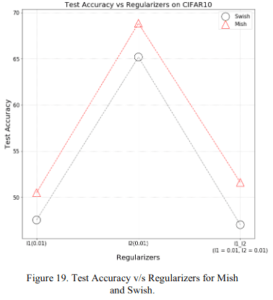
Mish nicely dominates Swish in regularization as well.
2.2.5 Dropout Rate Dependency
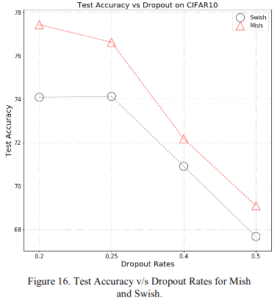
I prefer Mish at any dropout rate.
2.2.6 Layer width
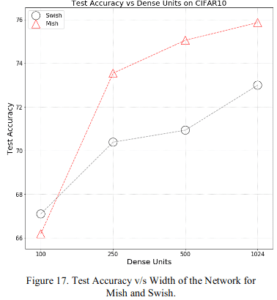
Mish outshines Swish when it comes to the breadth of the more expressive layers
2.2.7 Cos Annealing and One Cycle Policy
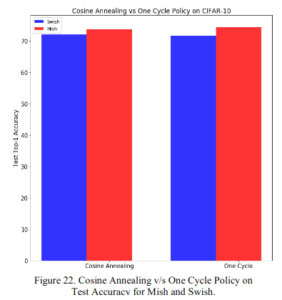
I see that Mish is more accurate than Swish using both the learning rate scheduler, Cosine Annealing, and the One Cycle policy.
2.2.8 Mixup
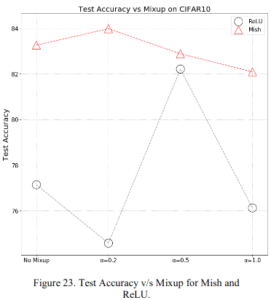
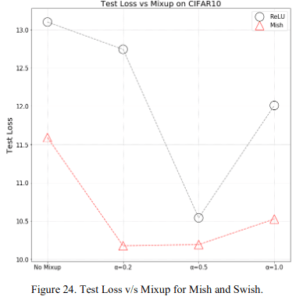
Here are the accuracies for the hyperparameter $\\alpha$ of one of the data augmentation methods, MixUp (2017) (description ). The top figure is the precision and the bottom figure is the loss. For some reason, we are comparing it to ReLU here, but it beats ReLU in both cases.
2.3 Other experiments
In addition to the experiments mentioned above, we have conducted several other experiments and will introduce them here.
2.3.1 Different activation functions
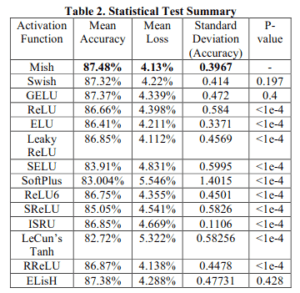
For the network, we use SENet, with Mish showing the highest accuracy, low loss, and low (accuracy) variance.
2.3.2 Different networks
We will look at the accuracy of Mish for various networks. We'll introduce them all at once at the table.
2.3.2.1 CIFAR-10
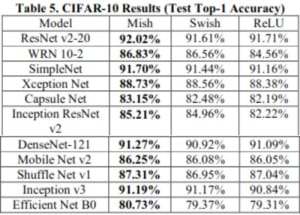
It has shown high accuracy on a wide range of models from ResNet v2-20 to EfficientNet B0 and MobileNet v2. Amazing!
2.3.2.2 CIFAR-100
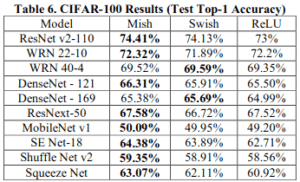
In the CIFAR-100, Mish has lost only two to Swish, but other than that, Mish has won everything else. It's amazing too!
2.3.3 Learning Speed
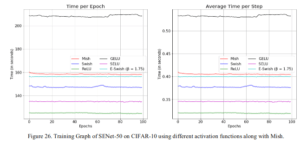
Here's the only drawback of Mish, which is the speed of learning. You can see that it's not as fast as ReLU, which has a simple mechanism. However, you can decide whether to use it or not based on the improved accuracy with Mish that we have seen so far.
3. Conclusions
Mish has surpassed ReLU and Swish, and in the paper, they show the next prospect of expanding it to ImageNet and NLP. It's very easy to use because you just turn the activation function into Mish. If you want to improve the accuracy of your models, try the implementation by the author of the paper!



Categories related to this article






