アンサンブルとデータ増強の併用には落とし穴がある?
3つの要点
✔️ アンサンブル・Data Augmentationを組み合わせた時、キャリブレーションが低下する場合があることを発見
✔️ 上記の問題について調査し、キャリブレーション性能低下の要因を特定
✔️ 上記の問題を回避する、新たなデータ増強手法"CAMixup"を提案
Combining Ensembles and Data Augmentation can Harm your Calibration
written by Yeming Wen, Ghassen Jerfel, Rafael Muller, Michael W. Dusenberry, Jasper Snoek, Balaji Lakshminarayanan, Dustin Tran
(Submitted on 19 Oct 2020)
Comments: Accepted to ICLR 2021.
Subjects: Machine Learning (cs.LG); Machine Learning (stat.ML)
code:
はじめに
複数のモデルの予測平均を用いるアンサンブル手法や、学習に用いるデータを増やすData Augmentationは、モデルのキャリブレーションやロバスト性を向上させるために多く用いられています。
しかし、本記事で紹介する論文では、これらの二つの手法を組み合わせたとき、モデルのキャリブレーションに悪影響を及ぼしうることが示されました。また、こうしたキャリブレーションの低下現象について調査し、これを回避するための手法であるCAMixupが提案されました。
事前準備(キャリブレーション、アンサンブル、データ増強)
アンサンブル・データ増強を組み合わせた際の悪影響について解説する前に、いくつかの事前知識について紹介します。
・キャリブレーション(calibration)
キャリブレーション誤差(calibration error)は、モデルの予測の信頼性評価に役立ちます。本記事で紹介する論文では、モデルの信頼性評価のための指標として、以下にて説明するECEを利用します。
・ECE(Expected Calibration Error)
分類器のクラス予測と信頼度(confidence:モデルの予測確率を示す)を、$(\hat{Y},\hat{P})$と表します。このときECEは、信頼度と精度の期待値の差$E_{\hat{P}}[|P(\hat{Y}=Y|]\hat{P}=p)-p|]$)の近似値となります。
これは、[0,1]の予測値を$M$個の等間隔にbinning(ヒストグラムで行われるように、一定区間(bin)内の値を中心値などの特定の値に置き換える量子化処理)し、各binごとの精度/信頼度差の加重平均を求めます。
ここで$B_m$を、予測された信頼度が区間$(\frac{m-1}{M},\frac{m}{M}]$に入る$m$番目のビンの集合とすると、ビン$B_m$の精度と信頼度は以下の式で表されます。
$Acc(B_m)=\frac{1}{|B_m|}\sum_{x_i \in B_m} I(\hat{y_i}=y_i)$
$Conf(B_m)=\frac{1}{|B_m|}\sum_{x_i \in B_m} \hat{p_i}$
$hat{y_i},y_i$はそれぞれ予測ラベルと真のラベルを、$\hat{p_i}$は$x_i$の信頼度を示します。$n$個の例が与えられると、ECEは$\sum^M_{m=1}\frac{|B_m|}{n}|Acc(B_m)-Conf(B_m)|$となります。
・アンサンブル(Ensemble)手法
アンサンブル手法は、複数のモデルの予測値を集約する手法です。実験では、BatchEnsemble、MC-Dropout、Deep Ensemblesの三つのアンサンブル手法と、データ増強手法との相互作用に焦点を置いて調査を行います。
・データ増強(Data Augmentation)手法
データ増強(Data Augementation)は、入力データセットを様々な変換(画像のクリッピングなど)によりデータを拡張し、一般化性能を向上させる手法です。実験では、以下の二つの手法について検証します。
Mixup
ある例$(x_i,y_i)$が与えられたとき、Mixupは以下の式で表されます。
$\tilde{x}_i=\lambda x_i+(1-\lambda)x_j$
$\tilde{y}_i=\lambda y_i+(1-\lambda)y_j$
ここで、$x_j$はtrainセット(ミニバッチから得られた)からのサンプルであり、$\lambda \in [0,1]$はベータ分布$\beta(a,a)$($a$はハイパーパラメータ)からサンプリングされます。
AugMix
データ増強操作集合を$O$、$k$をAugMixイテレーション数とします。このとき、画像に施す増強操作$op_1,...,op_k$とそれぞれの重み$w_1,..,w_k$(ディリクレ分布(a,...,a)からサンプリングされる)について、augmixによる増強は以下の式で表されます。
$\tilde{x}_{augmix}=mx_{orig}+(1-m)x_{aug}$
$x_aug=\sum^k_{i=1}w_iop_i(x_{orig})$
実験
以下の実験では、アンサンブルとデータ増強を組み合わせた場合のキャリブレーションについて調査を行います。はじめに、CIFAR-10/100上でのアンサンブルにMixupを適用した場合の結果は以下の通りになります。
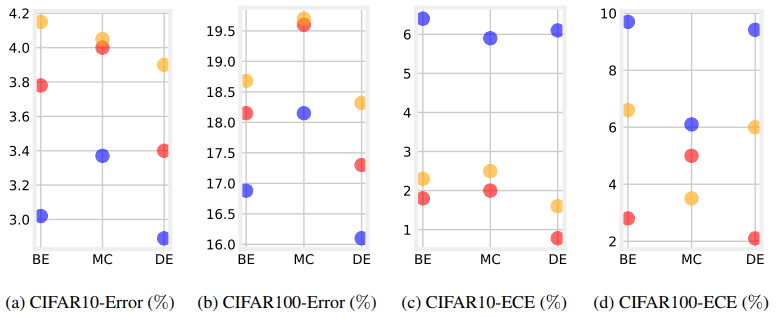
これらの結果は、5つのランダムシードについて実行した結果の平均を示しています。赤はアンサンブルのみ、青はMixup+アンサンブル、橙はどちらもなしの場合となります。図の(a),(b)では、Mixupとアンサンブルを組み合わせることで、テスト性能は向上している(Errorが減少している)ことがわかります。
一方、図(c),(d)では、Mixupとアンサンブルを組み合わせることで、キャリブレーションは悪化している(ECEが増大している)ことが示されました。
なぜMixupアンサンブルがキャリブレーションを悪化させるのか?
アンサンブルとデータ増強を組み合わせた場合のキャリブレーション低下現象について、より詳細な調査を行います。以下の図は、BatchEnsembleとMixupを組み合わせた場合に、異なる信頼度区間について計算された平均精度と平均信頼度の差を示しています。
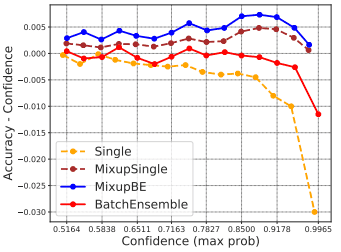
精度と信頼度の差(縦軸)の値が正であれば、精度に対して信頼度が低く(信頼度が過小評価されている)、負であれば信頼度が高い(信頼度が過大評価されている)ことを示しています。
この図を見ると、単一ネットワーク(Single)の場合と比べ、BatchEnsembleのみを用いた場合・Mixupのみを用いた場合それぞれについて、精度-信頼度差が大きくなり、全体としてゼロに近づいています。
そして、Misup+BatchEnsembleの場合、精度-信頼度差が全体として正方向に偏っており、精度に対して信頼度が過小評価されていることがわかります。つまり、データ増強・アンサンブル手法には信頼度の過大評価を防ぐ効果があるものの、両方を同時に用いる事によって、むしろ信頼度が過小評価されてしまうことがキャリブレーション悪化の原因であるとみられます。
さらなる可視化例として、五つのクラスタからなるシンプルなデータセットで、3層のMLPを学習させた場合の信頼度(ソフトマックス確率)は以下のようになります。
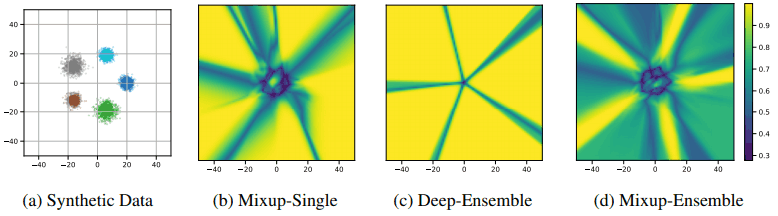
Mixup/アンサンブルなしの場合(c)では、全体として高い確率(黄色)が予測されています。これはMixupの導入により緩和され、さらにアンサンブルをも同時に用いることで、全体として信頼度がかなり低く(緑色)予測されていることがわかります。
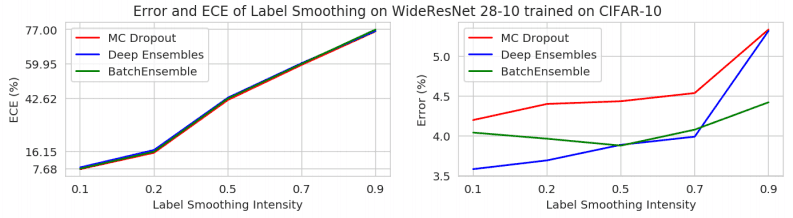
また、信頼度の過大評価を抑制する効果がある手法としてラベルスムージングが挙げられますが、このラベルスムージングをアンサンブルと同時に用いた場合にも同様の現象が生じます。これは以下の図で示されており、ラベルスムージングを強力に適用すればするほど、ECEが非常に大きく増加します。
Confidence Adjusted Mixup Ensembles(CAMIXUP)
論文では、このような信頼度の過小評価によるキャリブレーション低下を抑止する手法としてCAMixupを提案しています。CAMixupの根底にある考えは、分類タスクにおいて、クラスごとに予測の難しさが変化しうるというものです。このとき、予測が簡単なクラスでは信頼度が高まるように、難しいクラスでは信頼度が高まりすぎないようにすることが望ましいと考えられます。
CAMixupはこの考えのもと、クラスごとにMixupの適用度を変化させ、特にモデルの信頼度が過大評価されやすい(予測が困難な)クラスに対してMixupを強く適用します。これは以下の図で示されます。
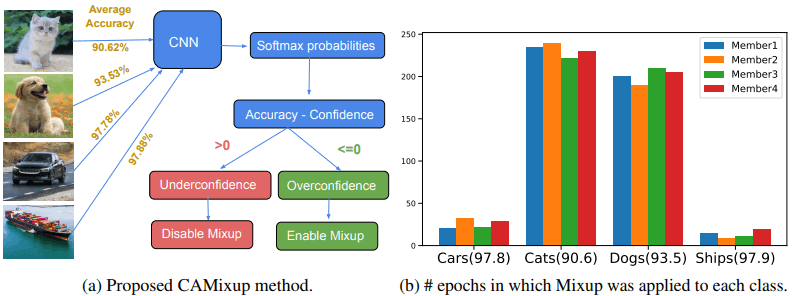
左図の通り、Accuracy-Confidence差が正であればMixupは適用せず、負であればMixupを適用します。右図では、250エポック実行時のクラスごとのMixup適用回数が示されています。この場合では、予測が難しいクラス(犬・猫)に対して、非常に多くMixupが有効にされていることがわかります。
CAMixupを利用した場合の結果は以下の通りです。
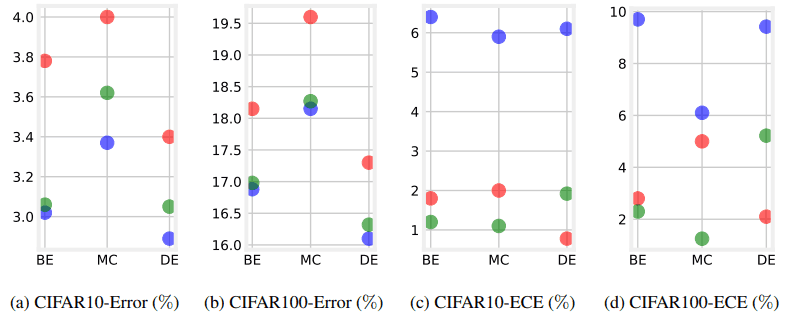
赤はアンサンブルのみ、青はMixup+アンサンブル、緑はCAMixup+アンサンブルの結果を示しています。図(a),(b)を見るとテスト精度は通常のMixupと比べて少し減少していますが、ECEは大幅に減少させられることがわかりました。また以下の表では、ImageNet上での結果を示しています。
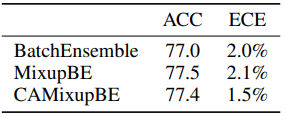
精度の低下はごくわずかながら、ECEは大幅に改善できることが示されました。
・分布シフト時の性能について
CIFAR-10-C/CIFAR-100-C(Cはcorruptionを示す)にて評価を行った場合の結果は以下の通りです。
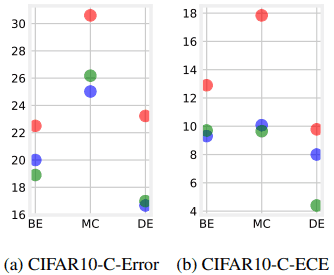
図の通り、分布シフトが生じるタスク設定においても、CAMixupは有効であることが示されました。またCAMixupは、最先端のデータ増強手法であるAugMixに対しても有効に機能することも示されています。結果は以下の通りです。
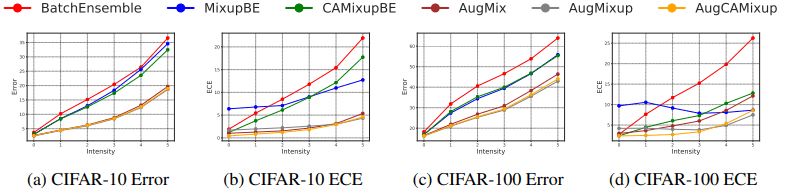
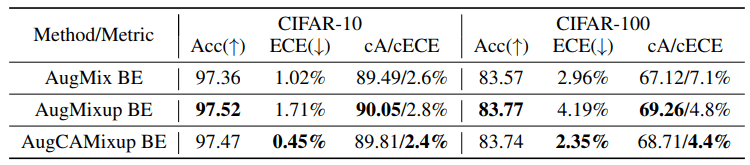
AugMixupはAugMixとMixupを組み合わせた手法となっています(詳細は省略します)。AugMixとCAMixupを組み合わせた修正版(AugCAMisup)についても、通常のCAMixupの場合と同様、ECEを大幅に改善できることが示されました。
まとめ
本記事で紹介下論文では、アンサンブルとデータ増強を組み合わせた場合にキャリブレーションが低下しうることが示されました。これは、アンサンブルとデータ増強により、信頼度が過小評価されてしまうことに起因するとみられます。これを回避するため、クラスの予測の難しさに応じてMixupを適用するかを変化させるCAMixupを提案しました。
データ増強・アンサンブルはどちらも性能向上のために有効な手法でありながら、これらを組み合わせることにより弊害が生じうる現象の発見、並びにその解決策を示した重要な研究であると言えるでしょう。





この記事に関するカテゴリー






