言語を抑制したトランスフォーマーは、非言語的なタスクにも役立つ!
3つの要点
✔️ 言語モデルを微調整して、視覚やタンパク質の折り畳み予測などの領域のタスクを実行
✔️ タスクに特化したデータセットでtransformerを完全に学習させるよりも、競争力のある、または優れた性能を発揮
✔️ 様々なドメインにおいて、ランダムな重みの初期化よりも効率的で、学習が速く、性能が良い。
Pretrained Transformers as Universal Computation Engines
written by Kevin Lu, Aditya Grover, Pieter Abbeel, Igor Mordatch
(Submitted on 9 Mar 2021)
Comments: Accepted to arXiv.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI)
code:
はじめに
Transformerアーキテクチャは、いくつかの分野で最先端の技術を推進してきました。Transformerは、視覚(物体検出、インスタンスセグメンテーション)、NLP(感情分析、言語モデリング)、視覚+NLP(視覚的な関連付け、視覚的な質問応答)など、さまざまなタスクに使用されています。最近では、単一のunified transfor(UniT)モデルが、細かく調整されたタスク固有のモデルと同等の性能を発揮することが示されています。
一般的な傾向としては、大規模なデータセットで大規模なモデルを学習し、その後、タスクに特化した小規模なデータセットに合わせてモデルを微調整する。例えば、巨大なテキストデータのコーパスで事前に学習したGPTモデルを、感情分析のデータセットで微調整することができます。大規模なテキストデータで事前学習したモデルを、異なるドメインのデータセット(例:視覚)を使って微調整しても、同じように機能するかどうかを確認するのは非常に興味深いことです。
Transformer 、特にself-attention層を、NLPのような教師なしの学習データが豊富な領域で事前学習し、その後、視覚のような異なる領域で非常によく機能するように微調整することができるという仮説を立てた。具体的には、事前に学習したGPT-2モデルを用いて、モデルの0.1%のみを微調整した場合(Frozen Pretrained Transformer)、完全に微調整されたtransformer やLSTMと同等の性能を発揮することができます。
モデル

GPT-2モデルを使用し、埋め込みサイズ/隠れた次元をndim、層数をnlayers、入力次元をdin、出力次元をdout、最大シーケンス長をlとします。self-attentionパラメータは凍結し、以下のパラメータのみをタスクに応じて微調整します。
1)出力層:出力次元は単純な線形層で、冷凍されたself-attention層が最も多くのタスクを実行していることを確認するために、最小にしています。分類タスクの場合、出力次元はクラスの数と等しくなります。例:CIFAR-10の場合は10で、線形層の重み行列は768x10の次元を持ちます。
2)入力層:入力データの次元は、データセットによって異なるため、微調整が必要となります。ここでも、単純な線形層を使用して、凍結したself-attention層がより複雑になるようにしています。線形層の重み行列の次元はninxndim、すなわちCIFAR-10の場合は16×768である。
3)層の正規化パラメータ:標準的な手法として、層の正規化層のスケールとバイアスのパラメータを微調整します。GPT-2では1ブロックあたり2つのレイヤーノルムがあり、合計で4 × ndim × nlayers パラメータ=4×768×12=36684となります。
4)位置情報の埋め込み:実験の結果、位置情報の埋め込みはモダリティ間で驚くほど似ていることがわかりました。しかし、それを微調整することは有益である。位置エンベッディングの次元はlxndimで、CIFARのベースモデルの場合、64×768=49512個のパラメータを持つ。
ベースとなるCIFAR-10モデルでは、これらのパラメータはGPT-2モデル全体の0.086%、GPT-2 XLモデルの0.029%に過ぎません。
評価
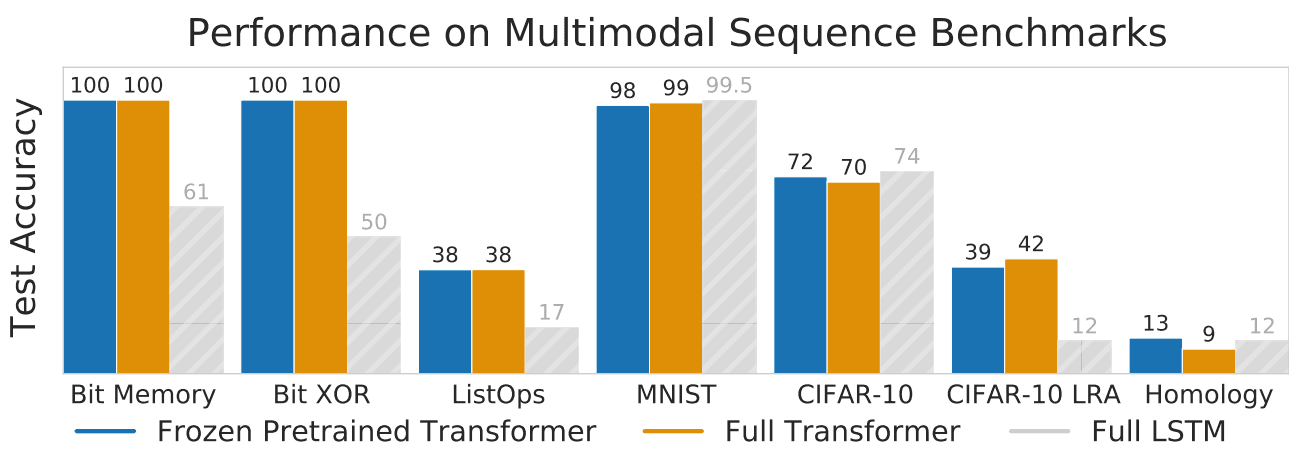
このモデルを様々な領域のタスクで評価されました。具体的には、ビットメモリ(1000ビットの長いビット列を記憶するタスク)、ビットXOR、ListOps(リスト演算の結果を予測するタスク)、MNIST、CIFAR-10、CIFAR-10 LRA(長距離アリーナベンチマークのCIFAR-10をより長い入力配列に変更したもの)、リモートホモロジー検出(タンパク質のフォールドを予測するタスク)などがあります。

凍結されたself-attentionパラメータで微調整されたモデルは、凍結事前学習済み変換器(FPT)と呼ばれます。これに加えて、タスク用のLSTMモデルと、完全に訓練された別の変換モデル(Full)を学習します。すべてのタスクにおける結果を上の表に示します。すべてのタスクにおいて、FPTはFull transformerおよびLSTMよりも優れた、あるいは同等の性能を達成しました。
Bit XORタスクとBit Memoryタスクでは、FPTはシーケンス長が5の場合に100%の精度を達成しました。つまり、シーケンスを完全に復元することができました。また、256という大きな配列長でも、正確なアルゴリズムを復元できることがわかりました。これは、LSTMとは対照的に、FPTがかなり大きなメモリを持っていることを示しています。
データセットが小さい場合、12層の変換モデルを完全に学習させることは、学習が不安定になったり、オーバーフィッティングが起こりやすくなったりして、難しいことがわかりました。CIFAR-10モデルでは、3層のモデルが適切であることがわかりました。 これにより、full transformerの場合、モデルサイズを調整するという追加の問題が発生します。対照的に,FPT の性能はモデルサイズの増加とともに向上することがわかりました。
事前学習モダリティの重要性
ここでは、事前学習のモダリティ(言語、視覚、ランダム、記憶)を変えることで、課題間でのFPTのパフォーマンスにどのような影響があるかを見ています。

モデルのself-attentionパラメータを1)ImageNetデータセットで事前学習したViT変換器のself-attentionパラメータ2)ランダム初期化,3)Bit Memory Taskで事前学習したモデルのself-attentionパラメータに固定する。上の表の結果は,言語の事前学習の有効性を示しています。FPTはMNIST(vision)データセットではViTに勝り、ランダムデータセットでは全てのタスクで大幅に勝るという驚きの結果が得られました。一方、ViTはVisionタスクのみでランダムな初期化にほとんど勝っており、ホモロジーでは最悪の結果となりました。
言語の事前学習による計算効率の向上

上の表にあるように、FPTはランダムな初期化よりも早く収束し、計算資源を節約できることがわかりました。
言語の事前学習でオーバーフィッティングを防止

他の2つのtransformer(Vanilla TransformerとLinformer)は、データセットに含まれるインスタンス数が少ない(上表のCIFAR-10 LRAでは50k)ためにオーバーフィットしているのに対し、FPTはオーバーフィットの傾向が少なく、検証データに対して良好に一般化していることが観察されました。また、FPTモデルはデータに対して過小適合する傾向があるため、モデルの容量を増やすことで性能を向上させることができます。

フィードフォワード層とアテンション層を微調整すべきか?
フィードフォワード層の微調整を行ったところ、CIFAR-10、Homology、MNISTの各データセットで性能の向上が見られたが、先行研究によると、トレーニング中に発散してしまう可能性があるという。attention層を微調整しても、attention層とフィードフォワード層の両方を微調整しても、効果はありませんでした。

まとめ
大規模な実験では、大規模なテキストデータのコーパスで事前に学習した言語モデルを微調整することで、さまざまなタスクでモデルの性能を向上させることができることが示された。言語学習によって、self-attention層が任意のデータ列で有用な表現を学習できることが明らかになった。これにより、高価で時間のかかるネットワーク全体の微調整の必要性から解放されます。より大きなデータセット(最近のWikipedia Image Text-WIT Datasetのような)が開発されているので、将来的には、他のデータが豊富なモダリティ(より大きな視覚データセット、視覚-テキストデータセット-WIT)についても調査することができます。




この記事に関するカテゴリー






