去掉ReLU,在对抗性学习中使用平滑的激活函数!
三个要点
✔️ 对抗性学习通常会提高机器学习模型的鲁棒性,但会降低其准确性。
✔️ 发现激活函数ReLU的非平滑性质抑制了对抗性学习。
✔️ 通过简单地用平滑函数取代ReLU,可以在不改变计算复杂性或准确性的情况下提高鲁棒性。
Smooth Adversarial Training
written by Cihang Xie, Mingxing Tan, Boqing Gong, Alan Yuille, Quoc V. Le
(Submitted on 25 Jun 2020 (v1), last revised 11 Jul 2021 (this version, v2))
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Neural and Evolutionary Computing (cs.NE)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
概述
被添加了扰动的图像被称为对抗性例子,在人眼里与原始图像没有明显区别(注意:在对抗性例子的背景下,原始图像通常被称为干净的图像),但是分类改变了模型的推理结果。

上面的图像是敌对的例子,扰动是中间的图像,似乎是噪音,而敌对的例子是右边的图像。因此,尽管原始图像(左边)和敌对的例子几乎相同,但分类结果却从熊猫变成了长臂猿。
针对能够识别行人的车载人工智能或监视婴儿的人工智能摄像头的敌意攻击会故意造成意外行为。
通过事先在训练数据集中加入对抗性例子来对抗对抗性攻击的学习被称为对抗性学习。这使得模型即使在输入对抗性例子时也能正确分类,也就是说,它提高了鲁棒性。然而,另一方面,人们发现,模型本身的分类精度也会降低。因此,人们普遍认为,模型的稳健性和准确性是不相容的。
在本文中,对对抗性学习过程的分析所提供的结果推翻了上述的普遍信念。研究发现,由于ReLU的非平滑性质,广泛使用的激活函数ReLU抑制了对抗性学习,可以使用平滑函数代替ReLU,以实现准确性和稳健性。作者发现,使用平滑函数而不是ReLU可以同时实现准确性和稳健性。作者称这种方法为平滑对抗训练(SAT)。
背景
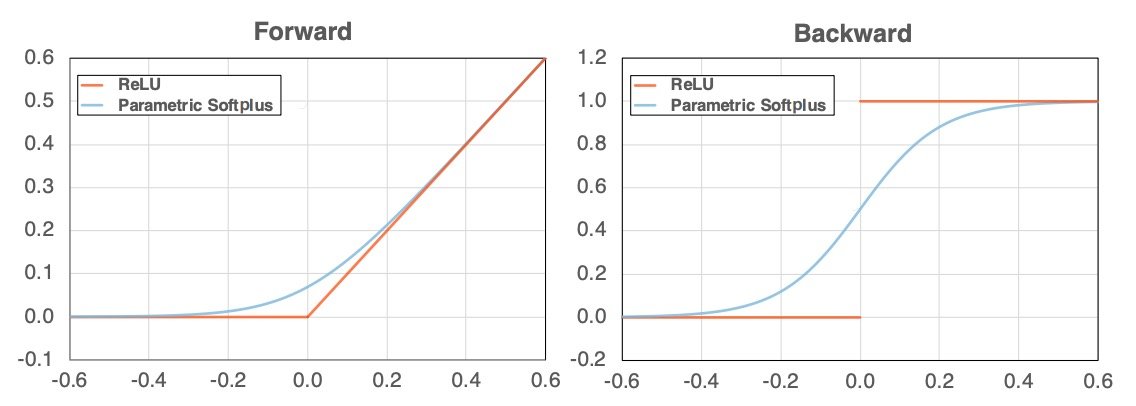
如上图所示,ReLU的图形(左图中的橙色)在x(横轴)为零之前和之后都会改变其角度。因此,如果进行分化,它就会变得不连续(右图中的橙色)。本文表明,由于这一特性,对抗性学习效果不佳,并提出了平滑对抗性训练(Smooth Adversarial Training,SAT),用平滑函数代替ReLU。
相关研究
对抗性学习通过在对抗性例子上训练模型来提高鲁棒性。在现有的研究中,提高对抗性鲁棒性需要牺牲源图像(干净图像)的准确性或增加计算成本,例如梯度遮蔽。这种现象被称为对抗性稳健性的 "无免费午餐"(注意:没有 "无好处的解决方案 "这种东西)。这就是所谓的 "没有免费的午餐"(注:没有只有利于对方的解决方案)。然而,在本文中,通过平稳的对抗性学习,可以免费提高鲁棒性(for free)。
除了通过对抗性例子学习之外,其他提高鲁棒性的方法包括防御性蒸馏、梯度离散化、动态网络架构随机变换,对抗性输入去伪存真/净化。然而,有人指出,这些方法改变了梯度的质量,梯度下降法可能效果不好。
通过ReLU弱化对抗性学习。
通过一系列实验,本节显示ReLU是否抑制了梯度计算(反向传播)路径中的对抗性学习,反之,平滑函数是否增强了对抗性学习。对抗式学习可以被认为是一个优化问题,由以下公式表示
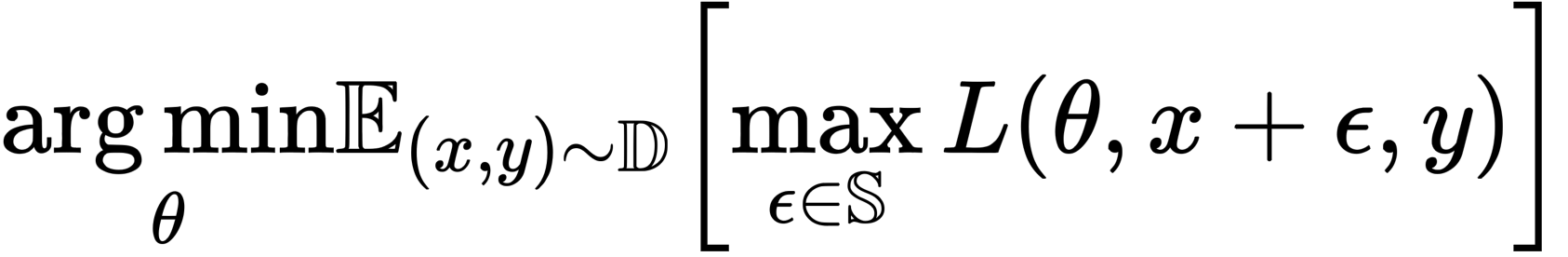
其中,D是数据分布,L是损失函数,θ是网络参数,x是训练图像,y是正确标签,ε是扰动,S是扰动范围。请注意,S被设置得尽可能小,以便使扰动不被人类感知。
如上式所示,对抗性学习分为两个部分:一个是将对抗性例子造成的损失最大化的方向(内部),另一个是更新参数以减少整体模型损失的方向(外部)。
在本研究中,ResNet-50被用作基础模型,默认使用ReLU作为激活函数。攻击方法是单步PGD攻击(投射梯度下降攻击器),这是一种计算成本低廉的方法,只产生一次对手,而不是通过学习逐渐产生更强大的对手。该PGD-1创建的对抗性例子是学习的。
PGD是一种用于计算扰动的优化技术。扰动产生对抗性例子,这些例子必须符合训练数据的分布,以便对抗性例子看起来自然。因此,需要进行约束性优化,以便在 "非自然 "范围内 "增加最佳扰动",而这是由PGD完成的(注意:PGD经常被认为是生成对抗性例子的方法,因为它经常被用于对抗性攻击的背景,但它是一种优化技术)。
接下来,PGD-200被用作评估方法(机器学习也被用来创建对抗性例子,更新扰动200次,使损失最大化)。请注意,更新攻击200次被认为足以作为验证。

以上是对结果的总结(表1)。如前所述,对抗性学习分为:(i)加强对抗性例子的学习(第2栏,针对对抗性攻击者)和(ii)减少整体模型损失的学习(第3栏,针对网络优化者)。
首先,在没有对抗性训练的情况下对ResNet-50进行PGD-200攻击,其准确率为68.8%,稳健性为33%。相比之下,在网络优化过程中用Parametric Softplus函数取代ReLU,显示出1.5%的稳健性改进。
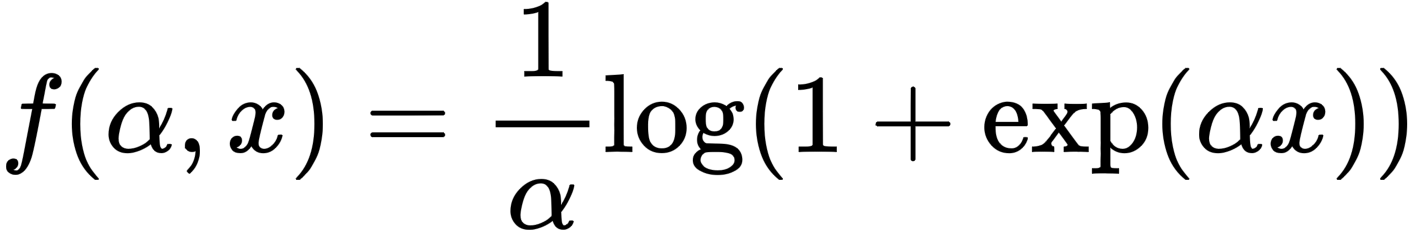
Parametric Softplus的功能如上所示。α是一个任意的数字。
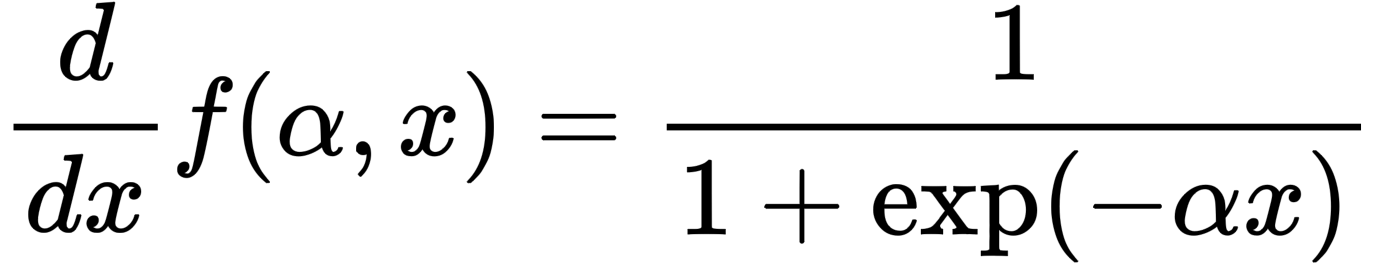
上图为微分版本;与ReLU不同,导数也是连续的(蓝色),如下图所示。
对抗性学习分为两部分:1)最大化对抗性例子造成的损失(产生强对抗性例子);2)最小化整个模型的损失(甚至不允许强对抗性例子被错误分类)。首先,关于(i)生成强对抗性的例子,作者指出ReLU是不合适的。
这是因为生成对抗性例子需要梯度计算,但ReLU的输出在x=0附近迅速变化。因此,ReLU破坏了学习更强的对抗性例子的过程,因为在扰动计算过程中,数值会发生显著变化。因此,作者提出了Parametric Softplus,一个近似ReLU的平滑函数。请注意,α是任意的,但根据经验定义为α=10,以更好地接近ReLU。
提高对抗性攻击者的梯度质量
我们先来看看梯度质量对(一)学习过程中对抗性例子计算(=内部最大化步骤)的影响。内部最大化的步骤是用下面的方程式表示的,不是吗?
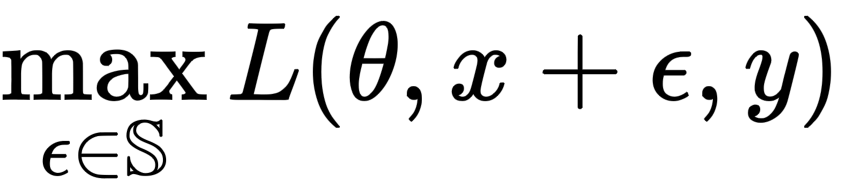
这一步产生了更强的对抗性例子,而对抗性例子的产生需要进行梯度计算。为此使用了Parametric Softplus函数,而不是ReLU。
准确地说,在学习生成对抗性例子时,ReLU用于前向传播,Parametric Softplus则用于后向传播。而对于整个模型的学习(对抗性学习),ReLU被用于正向和反向传播。这导致鲁棒性增加了1.5%,但准确性下降了0.5%(表1)。
平稳的对抗性训练
在上一节中,我们表明在反向传播过程中使用平滑函数可以提高鲁棒性。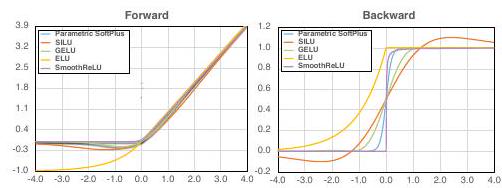
这里列出了几个平稳的功能,并分别进行了考察。
Softplus。
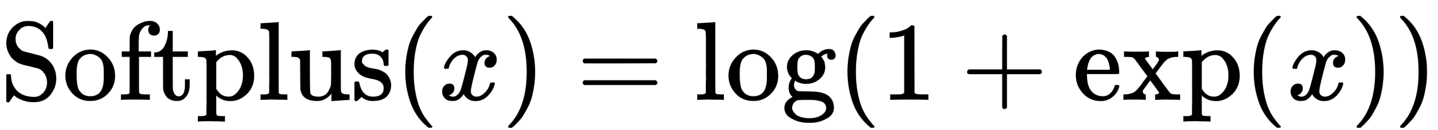
SILU
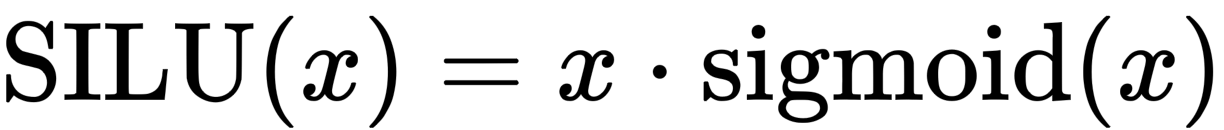
高斯误差线性单位(GELU)
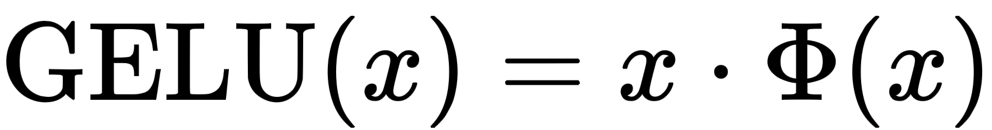
Φ是标准正态分布的累积分布函数。
指数线性单位(ELU)
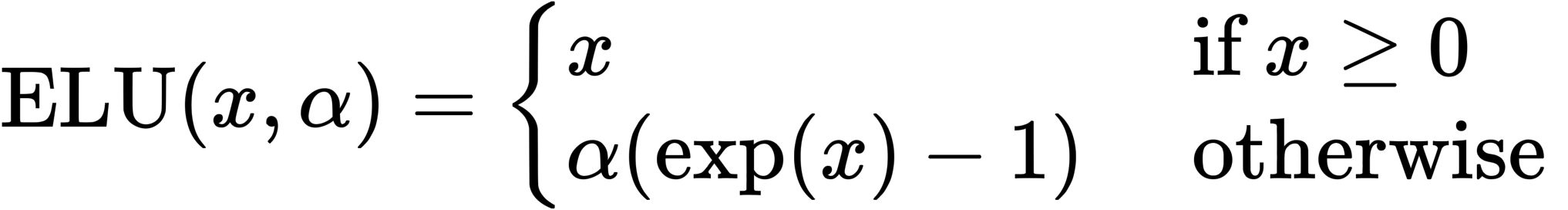
在这种情况下,α=1。这是因为当α不为1时,导数是不连续的。
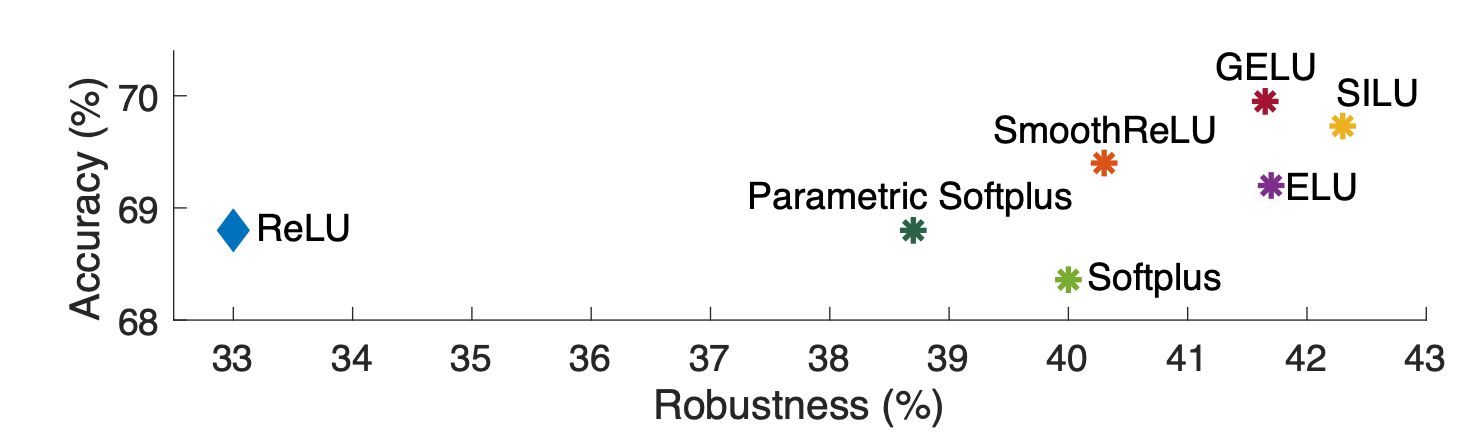
结果如上图所示(图3)。最稳健的是SILU,它的稳健性达到了42.3%,准确性达到了69.7%。可以假设,除本研究中使用的函数外,更好的平滑函数将进一步改善结果。
结论
本文提出了平滑对抗训练,在对抗学习中,激活函数被平滑函数所取代。实验证明了SAT的有效性,在准确性和稳健性方面明显优于现有研究。



与本文相关的类别