
简单而有力!AugMix来了,这是一种数据扩展方法,可以提高模型的通用性和不确定性!
三个要点
✔️ 提出了一种数据扩充方法AugMix,以提高模型的鲁棒性和对不确定数据的评估
✔️ AugMIX通过凸组合经过数据扩充的多个转换图像,生成与原始图像偏差不大的数据,并利用它们进行训练,以提高了模型的鲁棒性
✔️ 证实了CIFAR-10和CIFAR-100以及ImageNet的损坏图像的决策误差分别从28.4%降到12.4%、54.3%降到37.8%和57.2%降到37.4%。
AugMix: A Simple Data Processing Method to Improve Robustness and Uncertainty
written by Dan Hendrycks, Norman Mu, Ekin D. Cubuk, Barret Zoph, Justin Gilmer, Balaji Lakshminarayanan
(Submitted on 5 Dec 2019 (v1), last revised 17 Feb 2020 (this version, v2))
Comments: Published on arxiv.
Subjects: Machine Learning (stat.ML); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
自从基于深度学习的方法在图像识别中表现出高性能以来,许多使用卷积神经网络的模型已经被提出来用于图像分类。
如果训练数据的分布和测试数据的分布完全相同,许多这样的模型可以达到很高的精度,但在现实世界的应用中,训练数据和测试数据的分布并不总是匹配的,如果它们不匹配,模型的估计精度可能会大大降低。
事实上,在以前的研究中,最先进的模型对常规ImageNet数据集的分类误差为22%,而在ImageNet-C数据集(见图1)中,它的分类误差上升到64%,该数据集由ImageNet数据集中的图像组成,这些图像通过应用各种处理而被破坏。据报道,这一比例已增加到64%。
此外,在训练数据中包括损坏的图像,可以使模型在测试时对训练数据中的损坏图像类型进行正确分类,但它只能对训练数据中的损坏进行分类,而不能针对未知的损坏进行正确分类。
这些结果表明,该模型不能推广到与训练数据分布不同的图像上,而且目前几乎没有技术可以提高该模型在这种情况下的稳健性。
因此,本文提出AugMix作为一种方法来提高模型的稳健性及其对不确定数据的评估。
AugMix是一种数据扩展方法,它通过对经过数据扩展的多个转换图像进行凸式组合,生成与原始图像没有太大偏差的数据,同时保持多样性。并且实验表明,它极大地提高了模型的稳健性和对不确定数据的评估,在某些情况下,最佳性能与传统方法的差异减少了一半以上。
图1:ImageNet-C数据集中的图像实例。
在接下来的章节中,在对作为先验知识的数据增强进行简要描述后,将解释所提出的方法、实验细节和结果。
什么是数据扩展?
数据扩张是一种通过对图像进行某种变换来伪装增加数据数量的方法,如图2所示。
除了图2中显示的那些,还有无数其他类型的变换,比如擦除(Erasing),它可以填充图像的一部分,以及高斯模糊(GaussianBlur),它应用高斯滤波器。
众所周知,使用这些不同的扩展方法训练的模型比只在原始数据上训练的模型更具有普遍性,但有时它们会降低性能或引起意想不到的偏差。
因此,为了提高模型的泛化率,需要根据领域手动寻找有效的数据扩展方法。
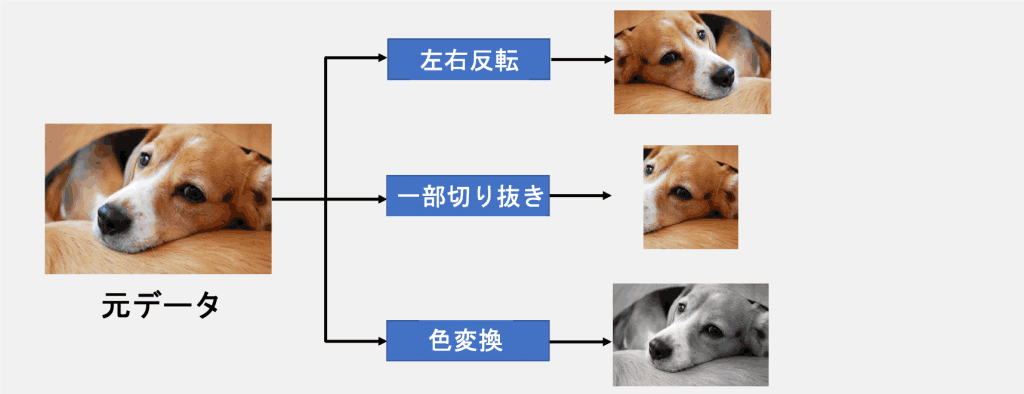
图2:数据扩展概述。
建议的方法
从这里,本文提出的方法AugMix得到了解释。
AugMix是一种数据扩展技术,通过利用简单的数据扩展操作,提高模型的稳健性和对不确定数据的评估。
之前的研究表明,深度模型在测试时对训练数据中的损坏图像类型是可以分类的。
因此,通过混合所有的数据扩展操作,产生了对稳健性很重要的各种转换图像,并用于训练。
以前的方法试图通过直接构建多个数据扩展操作的链条来增加多样性,但这样做会迅速降低图像的质量,如图3所描述的那样,转换后的图像可能与原始数据相差太远,导致彼此的特征不一致,学习不充分。
因此,所提出的方法以凸的方式结合多种数据扩展操作,以产生一个复合图像,最大限度地减少图像退化并保留图像多样性。

图3:由于多个数据扩展的组合而导致的失败实例
搅拌器
图4显示了AugMix的操作概要图。
在AugMix中组合几个数据增殖操作时,每个数据增殖操作都使用AutoAugment中的一个操作。
与ImageNet-C中的损坏重叠的操作被排除在外,以确保所提出的方法可以普遍适用于损坏的图像。
具体来说,对比度、颜色、亮度、锐度、剪裁、图像噪声和图像模糊等操作都被去除,这样,所提出的方法的数据扩展操作就与ImageNet-C中的腐败脱钩了。
根据上述条件,将随机选择的数据增强操作应用于原始图像并进行组合。
这样的组合被称为扩增链,一个扩增链由一至三个扩增操作的组合组成。
所提出的方法对这些增强链中的$k$进行随机抽样(默认为$k=3$),并使用元素-明智的凸组合来合成抽样的增强链。
最后,使用 "跳过连接 "将合成的图像与原始图像结合起来,产生一个图像多样性得到保留的图像。
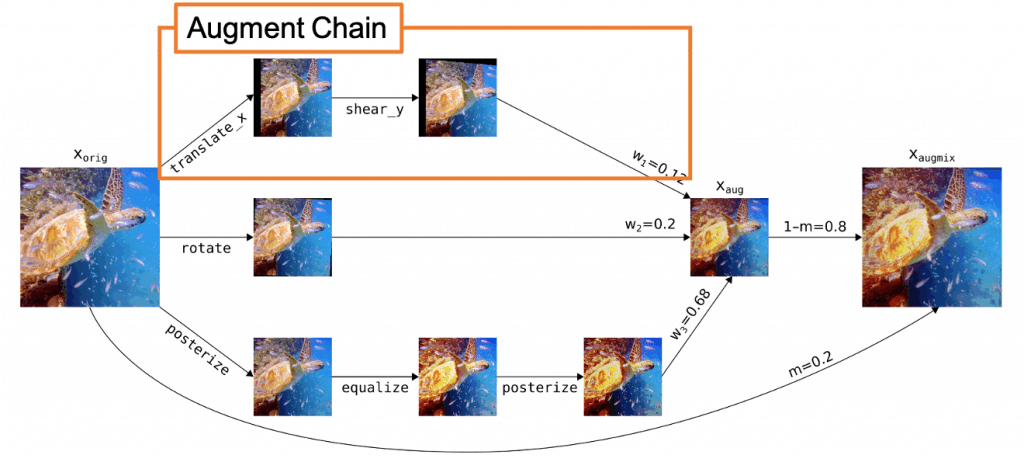 图4:AugMix操作概述 。
图4:AugMix操作概述 。
实验装置
实验中,我们使用CIFAR-10-C、CIFAR100-C和ImageNet-C数据集,分别是CIFAR-10、CIFAR100和ImageNet中每个数据集的损坏情况,比较了所提方法对模型的鲁棒性的影响。
此时,训练阶段的设置是为了避免学习与-C数据集中相同的腐败。
实验采用全卷积网络、DenseNet-BC(k=12,d=100)、40-2 Wide ResNet和ResNeXt-29(32×4)作为模型架构。
结果和讨论
CIFAR10-C。
图5总结了以ResNeXt-29为网络结构的CIFAR-10-C使用各种方法的分类误差。
从图5来看,与基线(标准)相比,提议的方法AugMix实现了16.6%的决策误差。
此外,与之前的其他方法相比,所提出的方法减少了误差,并接近于清洁误差,证实了所提出的方法的有效性。

图5:每种方法的CIFAR10-C分类误差
CIFAR10-C和CIFAR100-C
图6显示了CIFAR-10-C和CIFAR-100-C在几个架构的损坏数据集上的分类误差汇总。
所提方法AugMix的分类误差超过了以前的性能。
特别是,与基线(标准)相比,CIFAR10-C的分类误差成功减少了一半以下,CIFAR100-C的分类误差平均减少了18.3%,再次证实了所提方法的有效性。
 图6:CIFAR10-C和CIFAR100-C图像分类任务 的分类误差
图6:CIFAR10-C和CIFAR100-C图像分类任务 的分类误差
ImageNet-C。
图7总结了ImageNet-C中各种方法的Clean Error、Corruption Error(CE)和mCE(对损坏图像的平均分类误差)。
拟议的方法AugMix实现了68.4%的mCE,低于基线(标准)80.6%的mCE,再次证实了拟议方法的有效性。

图7:ImageNet-C中不同方法的清洁误差、破坏误差(CE)和mCE
摘要
本文提出了一种数据增强方法,即AugMix,以提高模型的稳健性,解决模型不能泛化到与训练数据分布不同的图像的问题。
所提出的方法AugMix将多个转换后的图像与数据扩展处理相结合,生成与原始图像偏差不大的数据,同时保持多样性,可用于训练以提高模型的稳健性。
为了证实所提方法的有效性,我们进行了实验,检查了CIFAR-10-C、CIFAR100-C和ImageNet-C数据集的分类误差,这些数据集分别是CIFAR-10、CIFAR100和ImageNet的损坏。
结果显示,与基线和其他方法相比,所提出的方法在所有三个数据集上都减少了分类误差。



与本文相关的类别






