
Kubric简介,一个大规模的数据生成库
三个要点
✔️ 机器学习模型的质量就是数据的质量。
✔️ 数据合成可以避免一些问题,如详细的注释分配、消除抽样偏差和合法安全的数据收集。
✔️ Kubric是一个Python库,可以进行对许多任务有用的数据生成。
Kubric: A scalable dataset generator
written by Klaus Greff,Francois Belletti,Lucas Beyer,Carl Doersch,Yilun Du,Daniel Duckworth,David J. Fleet,Dan Gnanapragasam,Florian Golemo,Charles Herrmann,Thomas Kipf,Abhijit Kundu,Dmitry Lagun,Issam Laradji,Hsueh-Ti(Derek)Liu,Henning Meyer,Yishu Miao,Derek Nowrouzezahrai,Cengiz Oztireli,Etienne Pot,Noha Radwan,Daniel Rebain,Sara Sabour,Mehdi S. M. Sajjadi,Matan Sela,Vincent Sitzmann,Austin Stone,Deqing Sun,Suhani Vora,Ziyu Wang,Tianhao Wu,Kwang Moo Yi,Fangcheng Zhong,Andrea Tagliasacchi
(Submitted on 7 Mar 2022)
Comments: 21 pages, CVPR2022
Subjects: Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR); Machine Learning (cs.LG)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
概述。
近年来,你听说过 "数据驱动 "这个词吗?这意味着 "数据驱动 "或 "数据驱动和驱动",表明 "数据的质量比机器学习方法更能决定结果"。由于机器学习的爆炸性增长以及大学和公司开展的各种研究和开发工作,数据质量对于模型的准确性至关重要,这一点已经变得很明显。
然而,要收集和储存高质量的数据是很困难的,也就是说,数据要详细准确地注释,没有偏见,组织良好,并具有法律保障。
相比之下,数据合成是一种可以解决上述问题的技术。另一方面,与训练和设计机器学习模型的工具相比,数据合成的工具还不成熟。
因此,本文提出了一个名为Kubric的Python框架,它可以与PyBullet和Blender一起工作,生成逼真的图像并对其进行细节注释。此外,它可以分布在数以千计的机器上,允许大规模的数据生成被部署。
在本文中,通过生成13种针对关键任务的数据,测试了Kubric的有效性。
介绍。
大规模、高质量的数据对深度学习至关重要。数据的数量和质量与模型设计和训练方法同样重要,甚至更重要。然而,即使是简单的基于图像的任务,收集和管理足够的高质量数据也是一项具有挑战性的任务。
数据合成已被用于基准评价,因为它很容易注释(真/假),并能控制图像的复杂性。它也可以用来系统地评估不符合模型假设的数据,甚至通过合成模型设计中没有假设的数据。同样,它也被用来训练模型,合成数据也被证明是令人惊讶的有效。
然而,数据生成的工具还不是很成熟。本文提出了Kubric,一个用于数据生成的工作框架,它可以为视觉任务生成各种格式的数据集(见下图),并可以进行详细的注释。此外,Kubric可以在数以千计的机器上运行大型数据生成工作。在本文中,生成了13个不同的数据集,并根据各种基准对它们进行了验证。
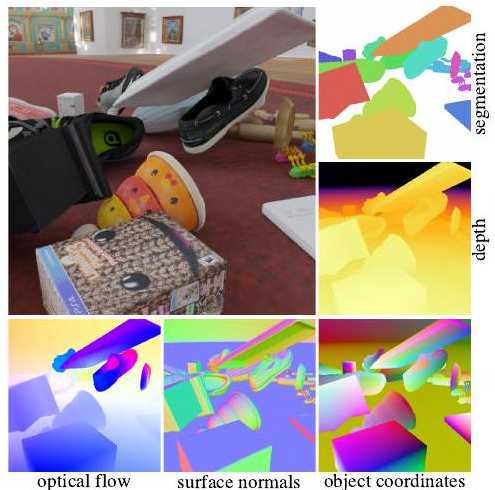
上图是用Kubric创建的一个场景(注意:在论文中自然是静止的图像,但在GitHub上可以看到是视频)。物体碰撞等是在PyBullet中模拟的,并在Blender中渲染。输出的图像(上图)包含丰富的注释,包括分割、深度图、光流和法向量。
相关研究
合成数据为许多图像任务提供了高质量的标签;CLEVR、ScanNet、SceneNet RGB-D、NYUv2、SYNTHIA、虚拟KITTI和Flying things 3D已被报道为数据合成工具,但这些都是特定的任务。在许多情况下,没有留下任何数据,例如相机设置、照明条件等。
也有使用Blender和Unity的数据合成管道,但这些也往往是为特定任务设计的。更重要的是,如果没有对渲染引擎的深入了解,就很难给数据分配新的属性。
ThreeDWorld被称为像Kubric一样的通用数据合成引擎。
ThreeDWorld有一个灵活的Python API和一个基于Unity3D的引擎,NVIDIA Flex物理模拟器,并通过PyImpact全面输出到声音生成。另外,与Kubric最接近的是BlenderProc,但BlenderProc与Kubric的区别在于,Kubric允许在数千台机器上进行作业,并且与TensorFlow的整合程度更高。
数据集和问题
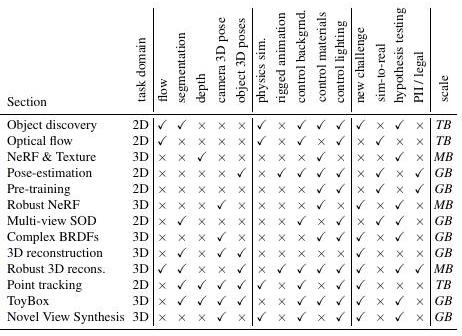
为了证明Kubric的性能和多功能性,描述了一系列使用Kubric生成的数据的挑战(如下表所列)。
视频上的物体发现(物体发现)。
对象发现是指从视频中发现对象分割掩码。数据集是一个叫做MOVi的视频,按照难度分为A到E。在SAVi和SIMONe之间进行比较,它们目前是SOTA。

上图显示了MOVi数据集,其中D和E显示有一些物体(如前景的鞋子)没有被提取出来。
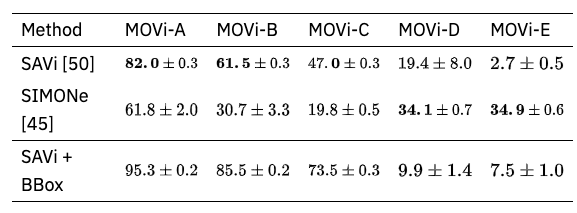
上述结果表明,随着视觉和动态复杂性的增加,对象发现是困难的。这个实验表明,Kubric产生的数据对评估现有的架构很有用。
光流
光流是视频中像素从一个特定帧到下一个帧的移动。众所周知,在由人类进行注释时,光流不是高质量的数据。

如上图所示,FlyingChairs是一个数据集,里面的椅子简直是漂浮在空中,并被用于光流数据集。Kubric解决了这些问题。
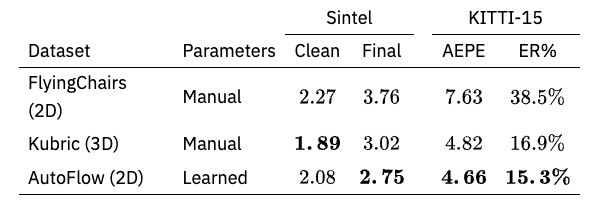
在已知的光流模型中,PWC-net、RAFT和VCN,RAFT被用来训练Kubric。结果显示,与FlyingChairs相比,性能有明显的提高。
与AutoFlow的比较要复杂一些,因为AutoFlow涉及到Sintel模型的超参数优化,而AutoFlow和Kubric不能简单比较。然而,如下表所示,它们的表现同样出色。根据超参数的设置,预计比AutoFlow有更高的性能改进。
NeRF中的纹理组成。
神经辐射场(NeRF)本质上是一种体积表示方法,但常用于物体表面的建模。通过比较真实的表面和NeRF重建的表面来衡量NeRF的性能,仍然是一个未开发的领域。

在本文的NeRF基准测试中,合成了一个由上图所示平面组成的物体。该物体的表面属性(纹理)是由蓝色噪声(Azure噪声)程序化生成的。然后为每个像素设置一个截止频率,作为注释数据使用。然后分析频率和深度方差之间的相关性(这就是任务),并测量与实际值设置的误差。

结果显示,颜色预测的准确性(PSNR)随着频率的降低而增加,而表面特性的准确性(深度方差)则降低。
姿势估计
姿势估计的互动体验(例如Kinect)使用人类姿势作为特征,但是当照片被用作数据集时,对好看的姿势有明显的抽样偏见。因此,不那么好看的姿势可以通过图像生成而不是照片来补充。

用于姿势估计的图像如上所示。
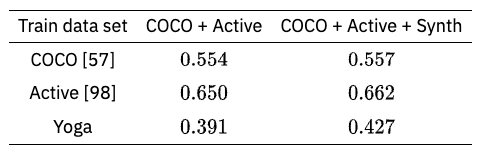
通过添加人体模型生成的图像,平均准确度(mAP)得到了提高,这些图像不在现有的数据集中(COCO)。
其他任务。
除了上述任务,Kubric生成的数据还被用于预训练视觉表征、Robust NeRF、突出物体检测(SOD)、复合BRDFs(双向反射率分布函数(BRDFs)、单视图重建、基于视频的重建、点跟踪、语义分割和封顶的新视点合成任务。库布里克生成的数据还可用于以下任务。
摘要
Kubric是一个Python库,具有丰富的注释支持和导出格式,可以直接向学习管道添加数据。
在本文中,Kubric的有效性在11个案例研究中进行了测试。结果显示,Kubric大大减少了生成必要数据所需的努力,并促进了重复使用和协作。
作者希望Kubric能够降低数据生成的障碍,防止数据碎片化。Kubric也有其挑战,并不完全支持Blender和PyBullet的功能。在未来,Kubric将支持摄像机效果,如雾和火焰、景深和运动模糊。



与本文相关的类别






