灾难性遗忘是什么原因造成的?
3个要点
✔️ 灾难性遗忘的机制研究
✔️ 发现神经网络的深层影响灾难性遗忘
✔️ 发现了任务的相似性和灾难性遗忘之间的关系
Anatomy of Catastrophic Forgetting: Hidden Representations and Task Semantics
written by Vinay V. Ramasesh, Ethan Dyer, Maithra Raghu
(Submitted on 14 Jul 2020)
Comments: Accepted to ICLR2021.
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (stat.ML)

code:.
dataset:.

首先
灾难性遗忘是指当一个训练好的模型被进一步训练时,现有任务的性能会显著下降,这是深度学习模型的一大挑战。
在本文介绍的论文中,神经网络的表示方法和各种抑制灾难性遗忘的方法,发现灾难性遗忘是在接近输出的层中引起的。他们还研究了所执行的多个任务的相似性与灾难性遗忘之间的关系。
实验
作为对灾难性遗忘的研究,他们使用各种任务模型架构进行实验。
任务
实验中使用了以下任务。由于在实验中依次学习了多个任务,所以每个任务都由几个(两个)任务组成。
- 拆分CIFAR-10:他们使用一个10类的数据集,分成两个任务,每个任务有5个类。
- 输入分布偏移CIFAR-100:任务是区分CIFAR-100的上层阶级,但输入数据是同一上层阶级内的不同分布集,导致分布偏移。
- CelebA属性预测:预测两个任务的输入数据是男性或女性,以及微笑或张嘴。
- ImageNet上级预测:这与上述CIFAR100的任务相同。
模型
在图像分类任务中,利用了三种常见的架构,具体如下
当这些模型依次对两个任务进行训练时,灾难性遗忘的例子如下所示。

在上述任务中,实验中采用了分体式CIFAR10/输入分布转移CIFAR-100。
当任务2在任务1完成后进行训练时,我们可以看到任务1的性能明显下降。
灾难性遗忘与隐藏层的表示方法
首先,他们研究神经网络内隐藏层的特征表示与灾难性遗忘之间的关系。它旨在回答以下问题:
- 网络中的所有参数和层级是否也会造成灾难性的遗忘?
- 网络中的特定参数或层级是灾难性遗忘的主要驱动力吗?
通过下面描述的一系列实验,他们发现,灾难性遗忘的原因在最接近输出的那一层(上层)。
冻结特定层
为了研究网络中特定层对遗忘的影响,他们进行了冻结特定层权重的实验(冻结:固定参数不更新)。具体来说,在任务1中训练完后,他们从最底层(最接近输入的那层)开始冻结到特定的层,在任务2中只训练剩下的层。
实验结果如下:

横轴上的数字越大,权重越是被冻结,直到更接近输出的那一层(上层)。从这张图可以看出,即使固定下层的权重,任务2的准确率也不会降低很多。
因此,他们期望下层的特征表示可以在任务1和2之间不更新地重用,上层是灾难性遗忘的主要来源。
如果该层没有冻结
如前所述,下层的特征表示可以在任务1和任务2之间重复使用(即使下层的特征表示按原样使用,也只能通过更新上层来获得良好的性能)。
那么,即使在不冻结层权重的情况下进行正常训练,下层的特征表示是否会有明显变化呢?为了研究这个问题,我们使用了中心核对齐(CKA),这是一种衡量神经网络表征相似性的方法。CKA通过一个从0到1的标量值来显示两个层的表示的相似度。
具体来说,对于由($n$)数据点和($p$)神经元组成的层激活矩阵$X \in R^{n×p},Y \in R^{n×p}$,CKA的计算公式如下: 1.
$CKA(X,Y)=\frac{HSIC(XX^T, YY^T)}{\sqrt{HSIC(XX^T, XX^T)}\sqrt{HSIC(YY^T, YY^T)}}$
HSIC是Hilbert-Schmidt Independence Criterion的缩写。
下图显示了学习任务2前后CKA计算出的层表示的相似度。
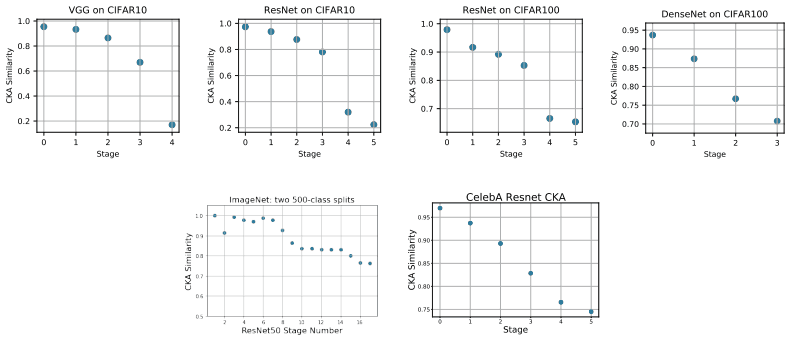
如图所示,学习任务2前后下层的相似度较高,而上层的相似度明显降低。
重新设置图层
他们还进行了更多的实验,揭示了上层对灾难性遗忘有显著影响。具体来说,在依次学习任务1和2之后,他们将$N$连续的层数从底层或顶层倒退到学习任务2之前的状态(就在学习任务1完成之后)。
其结果如下图所示。
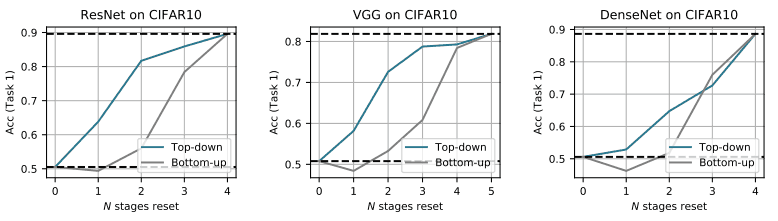
自上而下显示了从顶层(靠近输出端)重置N层时的性能,自下而上显示了从底层重置N层时的性能。一般来说,重置靠近顶部的图层比重置靠近底部的图层性能更高。
这说明上层对灾难性遗忘的影响很大。
重用特征表示和消除子空间。
通过分析子空间相似性,进一步研究任务顺序学习过程中表征的变化。
子空间相似度$X \in R^{n×p}$,通过PCA(主成分分析)计算,使用矩阵$V_k$,列从第一到$k$主成分,$U_k$以同样的方式得到$Y \in R^{n×p}$,如下。
$SubspaceSim_k(X,Y)=\frac{1}{k}||V^T_kU_k||^2_F$
在这里,分别计算以下三个条件的子空间相似度。
- (1)X:任务1上训练的模型,Y:任务2上训练的模型。
- (2)X:在任务1上训练的模型,Y:在任务1上依次训练的模型,然后再训练任务2。
- (3)X:在任务2上训练的模型,Y:在任务1上依次训练的模型,然后再训练任务2。
这种情况下的子空间相似度如下图所示。
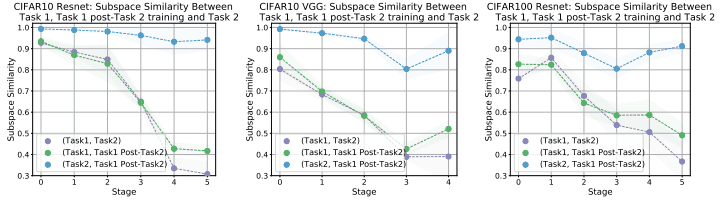
从学习任务2前后的对比可以看出(2:显示为绿色),学习任务2前后,上层的相似度明显降低,说明子空间发生了显著变化。
和使用CKA进行分析一样,他们可以看到下层表征在任务1和任务2之间变化不大,但上层表征变化明显。
遗忘缓解方法和特征表示
迄今为止的实验表明,灾难性遗忘主要是由上层的影响造成的。
那么,当然他们使用一种防止灾难性遗忘的方法(持续学习)时,上层是如何变化的呢?
事实上,他们在下面展示了使用Replay Buffer、EWC(Elastic Weight Consolidation)和SI(Synaptic Intelligence)等方法时的子空间相似性。
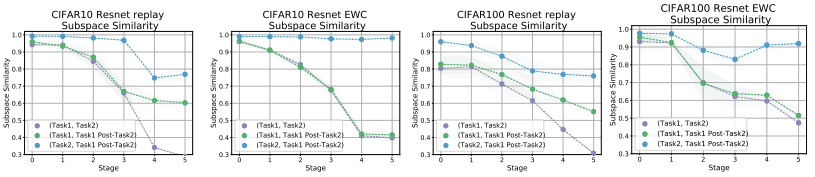
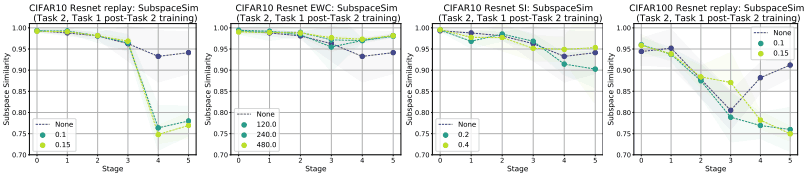
上图为各种放松方法的情况,下图为改变放松方法强度的情况(Task2、Task1 Post-Task2)。
由于重放法在训练Task2时使用了Task1的数据,所以(Task2、Task1后Task2)上层的相似度降低,而EWC/SI的相似度仍然很高。这可能表明EWC/SC鼓励重用特征表示,而重放方法使用正交子空间。
CKA值也比较如下。
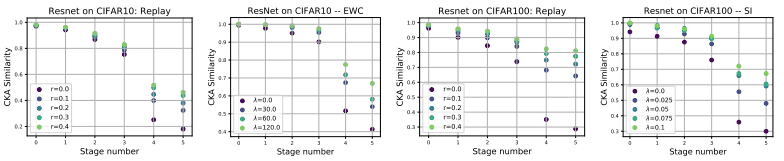
在该图中,显示了前面提到的三种松弛方法在不同强度($r$或$\lambda$)下的CKA值。
从图中可以看出,松弛技术应用得越强,相似度提高得越多,尤其是上层(上层的变化被抑制了)。
然而,上层相似度的提高是由于上层特征表示的重用,还是因为任务1和任务2的表示分别存储在正交子空间中,这是一个悬而未决的问题。
任务间相似性与灾难性遗忘的关系
在之前的实验中,他们研究了灾难性遗忘和网络中特征表示之间的关系。在随后的实验中,他们将研究连续任务之间的关系对灾难性遗忘的影响。
它旨在回答以下问题:
- 任务之间的相似度越高越能减少灾难性遗忘吗?
为了回答这个问题,他们试验了任务之间的相似性与灾难性遗忘的关系,结果如下图所示。
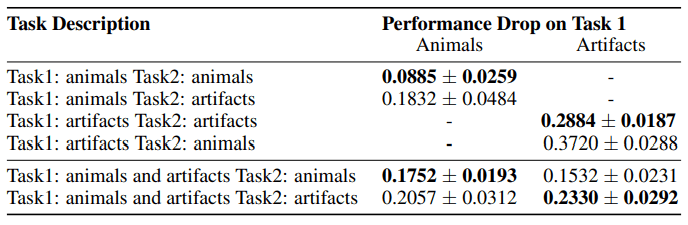
在这个表中,他们显示了使用ImageNet的Task1和Task2由工件和动物类组成时的性能下降。
例如,在Task1:动物Task2:动物中,在学习了10个动物图像分类任务(Task1)后,它执行10个不同的动物图像分类任务(Task2)。
如果假设任务之间的相似性可以减轻灾难性遗忘,应该期望当两个任务相似时(动物-动物或工件-工件),性能下降应该较小。但实际上,Task1:artifacts Task2:artifacts的性能下降要严重得多,这与上述假设相悖。同样,基于物体或动物构建的任务实验的学习曲线如下图所示。
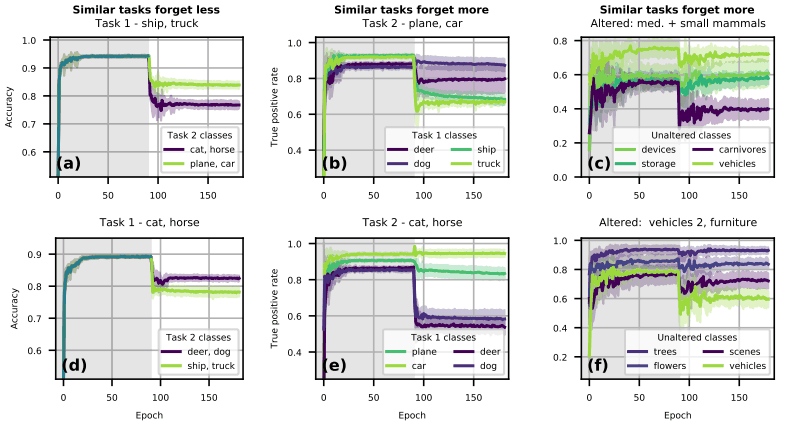
例如,在图中(a),任务1包含船舶和卡车类。在这种情况下,当我们用两种类型的任务2(猫、马或飞机、汽车)进行实验时,在与任务1(飞机、汽车)相同的对象上进行训练时,性能更高。
换句话说,当学习类似的任务时,灾难性遗忘会被削弱。这与(d)中的结果类似。
另一方面,在(b)中,当在Task1中训练两类物体和动物(船、卡车、鹿、狗),然后再训练物体(飞机、汽车)时,同样是物体的船和卡车的准确率会变差。
换句话说,由于类似任务的学习,灾难性遗忘相当严重。这与(e)中的结果相同。
(c,f)也是如此,在CIFAR-100上进行实验,输入分布发生变化的类(Altered)和类似类(分布没有发生变化:Unaltered)的性能会下降。因此,我们发现,当任务相似时,性能有提高的时候,也有降低的时候。
那么,任务间相似性与灾难性遗忘之间有什么关系呢?在不深入探讨过程细节的情况下,本文定义并测试了任务之间相似性的测量方法,并表明当相似性适中时,灾难性遗忘最强。
如下图所示。
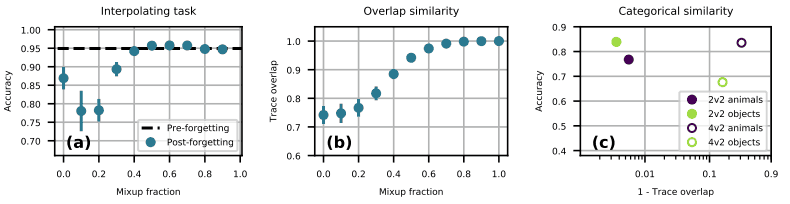
在图(a)中,他们首先训练二进制分类任务,然后显示在一个混合了其他任务的数据集和固定分数(mixup fraction)的数据集上训练时的准确性。
如图所示,当混频分数在0.1~0.2之间时,性能会有特别的下降。
图(b)显示了两组数据混合比的任务相似度(痕迹重叠),并显示任务相似度随着混合比的变化而单调变化。
图(c)显示了上述任务1和2的相似性(由a到f组成)。这里,●对应图中的(a),○对应图中的(b)。
实际的结果是,黄绿/紫色●和黄绿/紫色○中的黄绿表现低于其他颜色。
其原因可解释如下:
- 与黄绿色和紫色●相比,紫色的准确率较低,任务之间的相似度较低。
- 与黄绿圈和紫圈相比,由于黄绿圈的相似度中等,所以黄绿圈的精度较低。
因此,基于任务相似度适中时,灾难性遗忘最容易减少的发现,我们可以解释前面所述任务(由a-f组成)的结果。
摘要
在本文介绍的论文中,研究了灾难性遗忘的机制、神经网络的表示方法、持续学习方法以及与任务的关系,得到了以下两个主要结论。
- 灾难性遗忘主要是由上层(接近输出的那一层)贡献的
- 当任务间相似度适中时,灾难性遗忘最强(基于本文定义的测量方法)
虽然这些结果并不能为灾难性遗忘提供直接的解决方案,但却为遏制灾难性遗忘的方法研究提供了非常有意义的智慧。



与本文相关的类别






