RCURRENCY,股票预测的一种新可能性
三个要点
✔️提出了一个基于RNN的股票预测模型
✔️增加LSTM层,提高时间序列的通用性
✔️对各种数字资产有用
RCURRENCY: Live Digital Asset Trading Using a Recurrent Neural Network-based Forecasting System
written by Yapeng Jasper Hu, Ralph van Gurp, Ashay Somai, Hugo Kooijman, Jan S. Rellermeyer
(Submitted on 13 Jun 2021)
Comments: Published on arxiv.
Subjects: Artificial Intelligence (cs.AI)
code:
本文所使用的图片要么来自论文件,要么是参照论文件制作的。
简介
自17世纪现代金融市场出现以来,专家们已经ǞǞǞ商品和服务金融工具股票我们已经做了为了使证券交易的利益最大化,已经做出了各种努力。在过去的几十年里,已经对人工智能在传统市场上交易股票的潜力进行了多项研究,并取得了一些成功。
此外,现代机器学习算法能够发现数据中的模式,而这些模式由于数据的数量和复杂性,是人眼看不到的。
在这篇文章中,我将总结 "RCURRENCY:使用基于递归神经网络的预测系统进行实时数字资产交易 "这篇论文,它介绍了RCURRENCY,一个基于RNN的交易引擎,用于预测实时环境中波动的数字资产市场数据。基于网络的预测系统"。
相关工作
几十年来,利用历史数据来预测股票价格一直是一个活跃的研究课题。
早期的方法采用了纯粹的分析方法,应用了基本的数学和统计学,但从那时起,就出现了许多不同的预测股价的方法,以及对结果好坏的不同看法。
例如,如果随机漫步策略准确地反映了现实,那么经验证据表明,所有的(股票)市场预测模型都没有意义。如今,越来越多的变量被添加到预测模型中,如市场容量、推特情绪、投资者情绪和媒体新闻内容。
基本面分析描述了以宏观经济变量为重点的数据研究,而技术分析则侧重于提取投资工具的价格、数量、范围和交易活动的趋势和模式。
本文提出和分析的方法侧重于技术分析,但我们也打算在未来处理基本面分析。
随机漫步...假设金融工具的价格变动没有规律性,而且不受过去波动的影响。详见下文。
基本面分析...一种分析方法,根据世界经济、经济指标和各国政治发展的信息,预测汇率的中长期变动。
RCURRENCY实时交易系统
为了给加密货币市场提供可靠的预测,我们使用的模型是RCURRENCY系统,它由三个独立的组成部分组成。
第一部分的作用是及时收集和预处理一系列的数据。
第二个组件将这些数据送入一个神经网络,然后对其进行训练,以识别处理过的数据中的模式。这两个组成部分使该系统有能力预测时间序列数据中的单一步骤。
第三部分允许你进行单一预测以及交易决策。
它允许你在精确分析趋势和模式的基础上做出交易决定,不仅是基于单一的预测,而且是基于对趋势的精确分析。这个组件包括各种交易策略,每个策略都根据预先确定的规则计算出买入和卖出信号。包含所有这些组件的RCURRENCY系统的流程图如下所示。
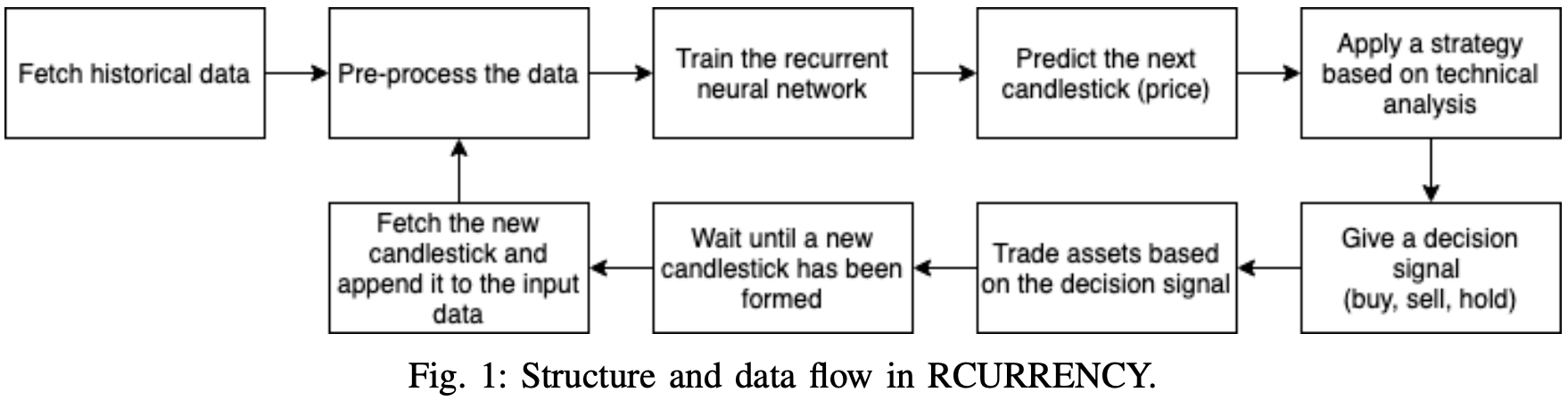
学习数据
该系统通过调用CryptoCompare提供的API检索原始比特币学习数据。CryptoCompare为超过3000种数字资产提供服务,并有能力检索历史价格数据。
这种数据由一分钟时间范围内的烛台(四个价格变动的时间序列:开盘价(OPEN)、高点(HIGH)、低点(LOW)和收盘价(CLOSE))数据点组成。
原始数据要经过预处理。不幸的是,数据集的前30%包含许多接近零的值,这往往会降低网络的预测能力。数据集的前30%包含许多接近零的值,这会降低网络的预测能力。这些值不包含足够的方差,无法让误差函数的梯度下降收敛。因此,我们已经手动删除了截至2013年5月的所有数据。
然后,技术分析被用来从价格数据中提取趋势和模式,并创建技术指标。每个指标都根据自己的公式计算,每个公式使用部分或全部数据集作为输入。
RCURRENCY实施金融技术指标。计算出的指标值被添加到训练数据中。这种额外的训练数据使神经网络能够获得更多的市场信息,并获得更高的预测精度。最后,对数据集进行基于行的规范化处理,使其在-1~1范围内。这能带来更好的效果并减少训练时间。
新的行规范化矩阵在数学上定义如下给出一个尺寸为m×n的矩阵x然后对于一个新的矩阵y和以下公式为真
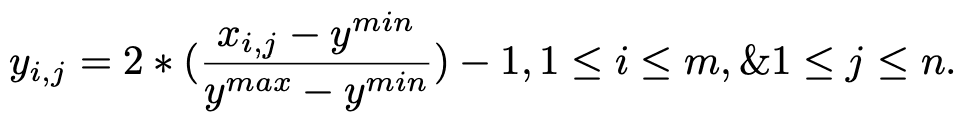
递归神经网络
我们使用一个递归神经网络作为RCURRENCY的预测器。循环神经网络是一种可以随着时间的推移表现出动态行为的神经网络。
该网络将各层节点之间的连接建模为沿连续时间的有向图:RCURRENCY的递归神经网络的输入数据由烛台组成。烛台的价值取决于前一个烛台的价值,因此不构成随机行走。
在传统的递归神经网络中,梯度下降在学习长时间的依赖关系时是一个问题,但在递归神经网络的架构中使用LSTM层解决了梯度爆炸和消失的问题。递归神经网络由三层组成。
1) 线性层
线性层是使输入层的节点与隐藏层的节点数相对应所需的层。线性层是一个全连接层,其中每条边都有一个单独的权重。它是一个全连接层。
2) 快速LSTM层
FastLSTM层是传统LSTM层的一个特殊、甚至更快的版本。FastLSTM层是传统LSTM层的一个特殊的、更快的版本。快速LSTM层是传统LSTM层的快速版本:它在一个步骤中计算输入、遗忘和输出门以及隐藏状态。由于实现了FastLSTM层,而不是传统的LSTM层,所以合成函数略有修改。
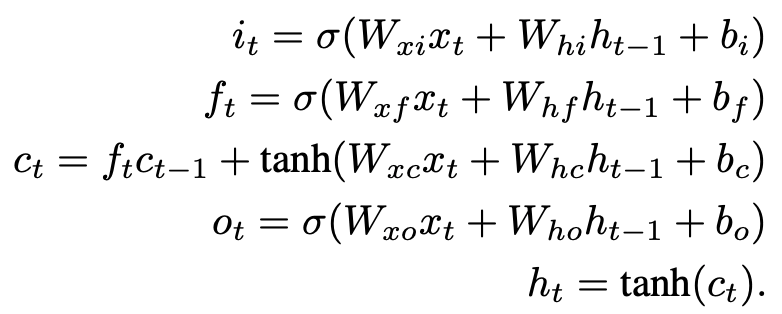
关于快速LSTM层的更多信息,请点击这里。
3) 输出层具有平均平方误差(MSE)性能函数
当神经网络被用于学习目的时,输出层对其进行评估。MSE函数被用来评估网络。
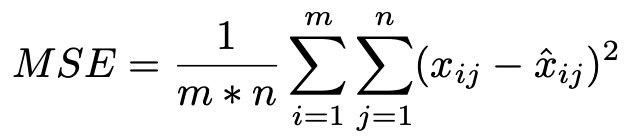
xij是实际值,xˆij是第i行和第j列的预测值
第i行和第j列的预测值,m是行的总数。
n是列的总数
更新参数的表达式是
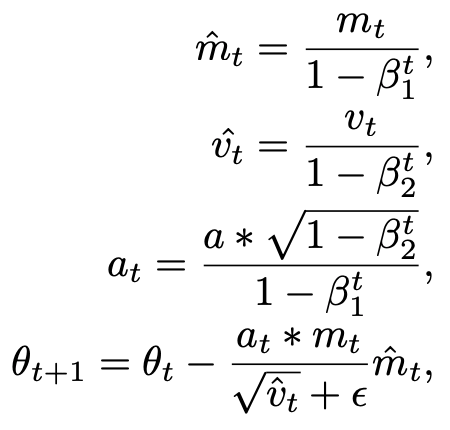
交易策略和预测
关于交易策略究竟有多大用处,有一个长期的论述。
基于时间序列模式分析的常见交易策略,如动量和逆向思维,以及其他技术分析策略,已经被用于不同程度的成功。因此,我们在实验性AI中加入了这一元素除了我们决定将这一元素添加到实验性人工智能中,使其能够应用基于技术指标的四种不同的交易策略。下面是对每种交易策略的简要描述。
动量是一种用来描述市场势头的表达方式。
逆势者是指跟随市场趋势相反方向的投资者。他们也被称为逆向投资者。
变化率 (ROC)
ROC策略考虑的是预测值相对于最后实际值的变化。
它考虑到预测值相对于近期实际值的变化。如果变化低于、介于或高于较低和较高的阈值,它就决定是卖出、买入还是持有。
相对强弱指数(RSI
它确定了资产价值上升或下降的趋势。如果RSI的值在足够长的时间内变化,则被认为是超买(应该卖出)。
双指数移动平均线(DEMA)
DEMA是一种使用两条移动平均线来决定是否购买、持有或出售资产的策略。当两条移动平均线交叉时,资产的长期和短期价值之间的势头发生了变化,使得买入或卖出的时机到来。
移动平均收敛/背离 (MACD)
MACD是一个著名的策略,基于两条不同长度的移动平均线之间的差异,称为慢速移动平均线和快速移动平均线。然后将这一差异与称为信号线的移动平均线进行比较。当差值超过信号线时,就会做出买入、持有或卖出的决定。
随机漫步
一个有争议但广受赞誉的投资理论,即有效市场假说,指出不存在持续盈利的交易策略,因为所有可用的信息都会立即反映在资产价值上。
实施
RCURRENCY是用C++实现的,其核心是各种库。首先,使用CryptoCompare提供的API获得历史数据。通过创建与交易所(Binance)的WebSocket连接,实时获取实时数据,并在蜡烛形成后获取。
在获得历史数据后,对其进行预处理并提供给神经网络。在这个过程中,我们使用了两个库,Armadillo和TA-Lib。
Armadillo库具有操作常规数据集所需的高度优化的矩阵计算能力,而TA-Lib具有从股市数据中有效计算技术指标所需的功能。
递归神经网络是用MLPack实现的,它是一组MLPack是一个一个快速而灵活的C++机器学习库MLPack是一个快速而灵活的C++机器学习库,提供了MLPack是一个快速而灵活的C++机器学习库,实现了广泛的可配置的神经网络和机器学习方法。
实验评估
考虑到数据的时间依赖性,我们应用了时间序列的K-折交叉验证。训练数据集分为由p个样本(80%)组成的训练部分和由q个样本(20%)组成的验证部分,其中每个样本代表一个时间单位值。k代表验证步骤中使用的样本数,或者说在每个训练和评估周期中预测了多少个时间单位。
然后,为了方便这种验证方法,我们在样本1,...,p上连续训练模型,并对下一个时间p+1产生预测,用验证样本p+1来验证预测。 ,p来生成下一个时间p+1的预测,然后用验证样本p+1来验证这个预测为了方便起见,我们在样本1,...,p上不断训练模型,以产生对下一个时间p+1的预测,然后用验证样本p+1来验证预测。样品1, ... ... , p + 1.
将k的值设为1意味着要进行q个周期来完成一系列的交叉验证;增加k的值可以减少学习和验证周期的数量。在每个周期后,误差被计算和存储。最后,用误差函数来衡量性能。
图2显示了所选折页数的平均均方根误差,但为了获得最小的误差,对k的一系列值进行了测试。
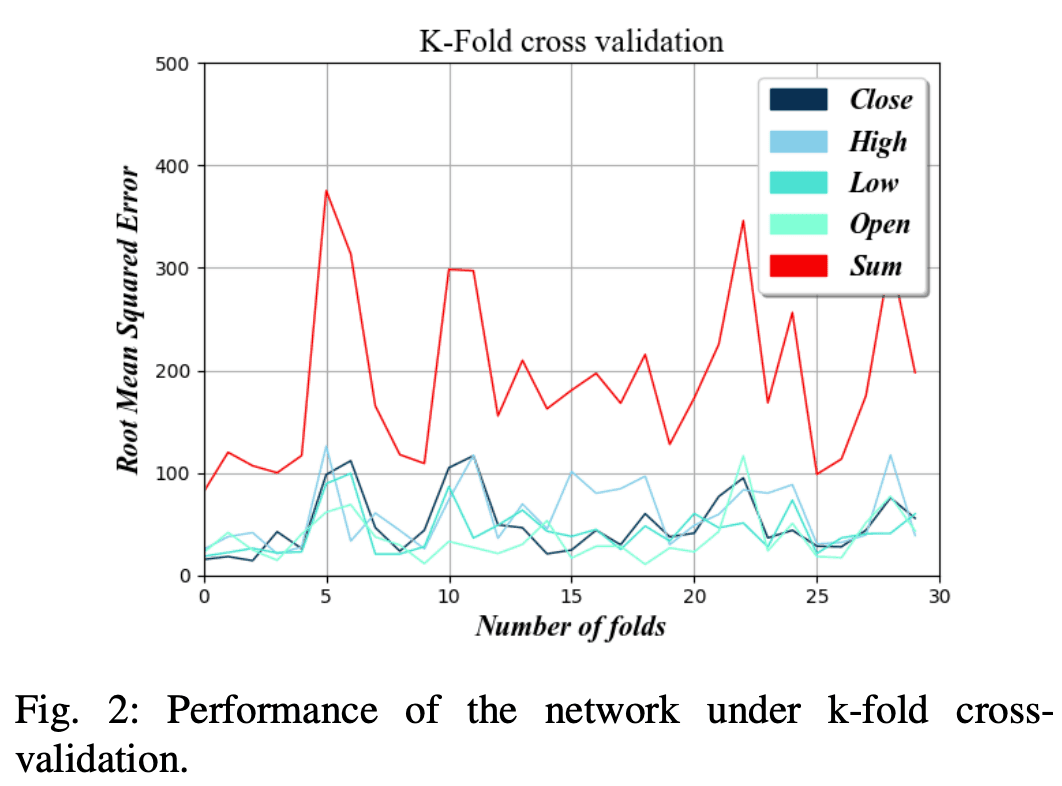
k的值越低,人工智能的预测错误就越少。这是因为褶皱的数量越多,在预测周期之前用于训练网络的数据就越少。
我们还可以看到,对于较低的k值,OPEN、HIGH、LOW和CLOSE四个部分的预测误差要比50美元低很多。
这意味着系统可以准确地预测上升和下降的趋势,因为每个区间的绝对变化平均来说大于预测误差。
参数优化
为了优化超参数,我们应用上一节的验证方法,寻找最小的RMSE,逐一改变参数。
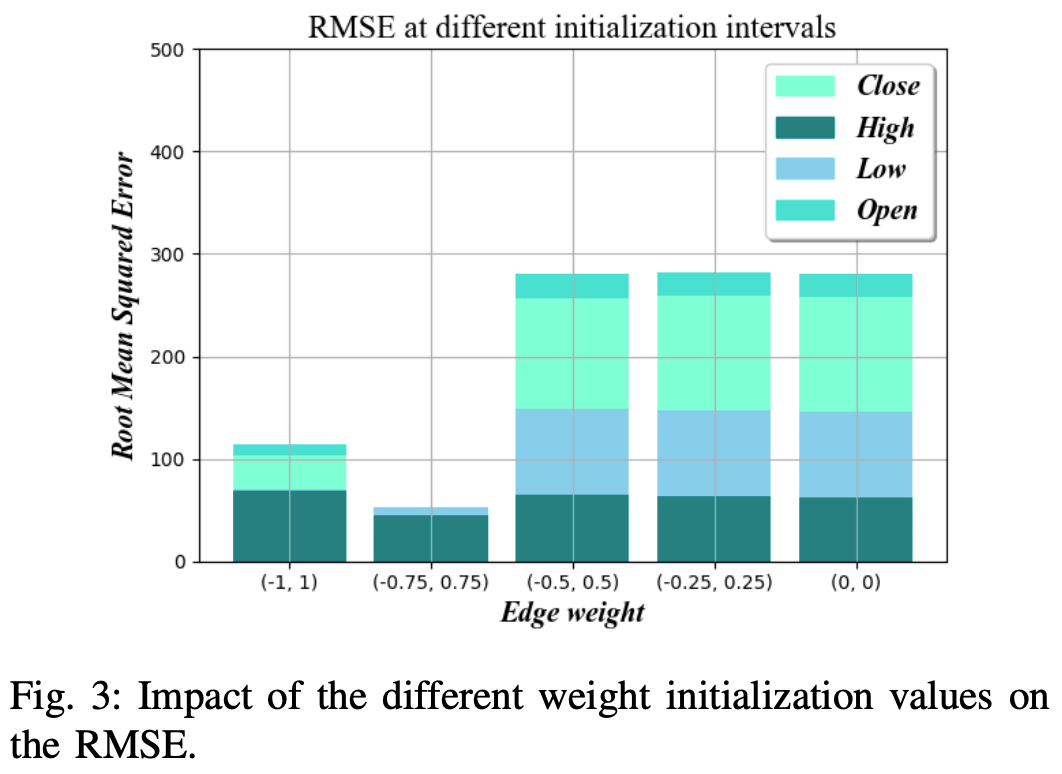
边缘权重的初始化
边缘的初始化值对神经网络的训练时间有很大影响。
通过更优化地设置初始权重,最终权重值的收敛速度会更快,学习时间可以大大减少。
如图3所示,在事实证明,在比特币数据集的不同折叠中,-0.75和0.75范围内的随机数的RMSE最低。
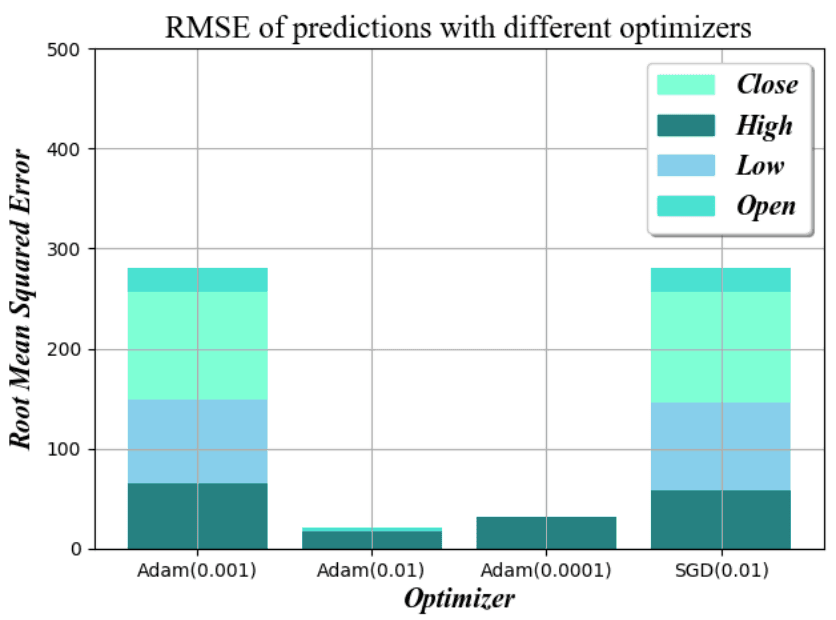
优化算法
优化算法的作用是在网络的每次训练迭代中调整权重,影响收敛的速度和预测的准确性。
随机梯度下降法(SGD)是最常用的优化算法,与亚当优化器相比,在用不同的步长进行测试后,我们发现SGD在学习率为0.01的情况下,在速度和准确性之间有最佳平衡。与Adam优化器相比,我们测试了不同的步长,发现SGD在学习率为0.01的情况下,在速度和精度之间有最好的平衡。
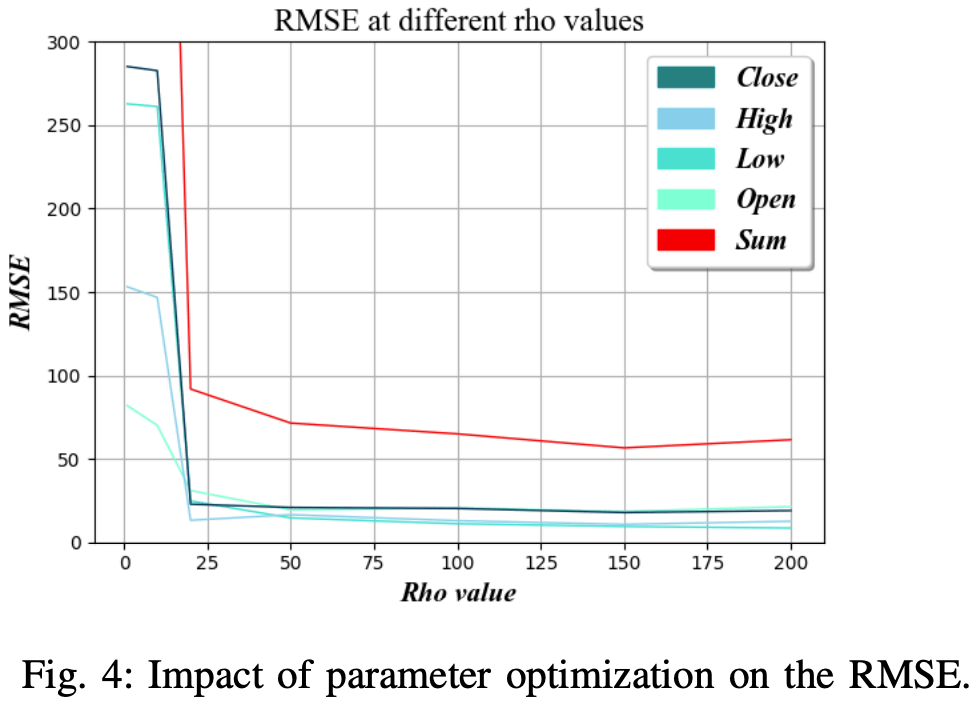
Rho值
Rho值为的价值。设置用于训练网络的BPTT(Back-Propagation Through Time)的长度。
在实践中,这决定了在时间序列的下一步中应该使用多少个最近的数值来预测输出。如图4b所示,我们发现,最佳值约为150。
隐藏层的复杂性
隐藏层的复杂性是FastLSTM层中使用的隐藏节点的数量。
增加节点的数量有可能训练出更复杂的规则,但也会增加训练所需的数据量。此外,当网络用于稍有不同的数据集时,过度拟合和丧失通用性的风险增加,从而导致不准确的结果。
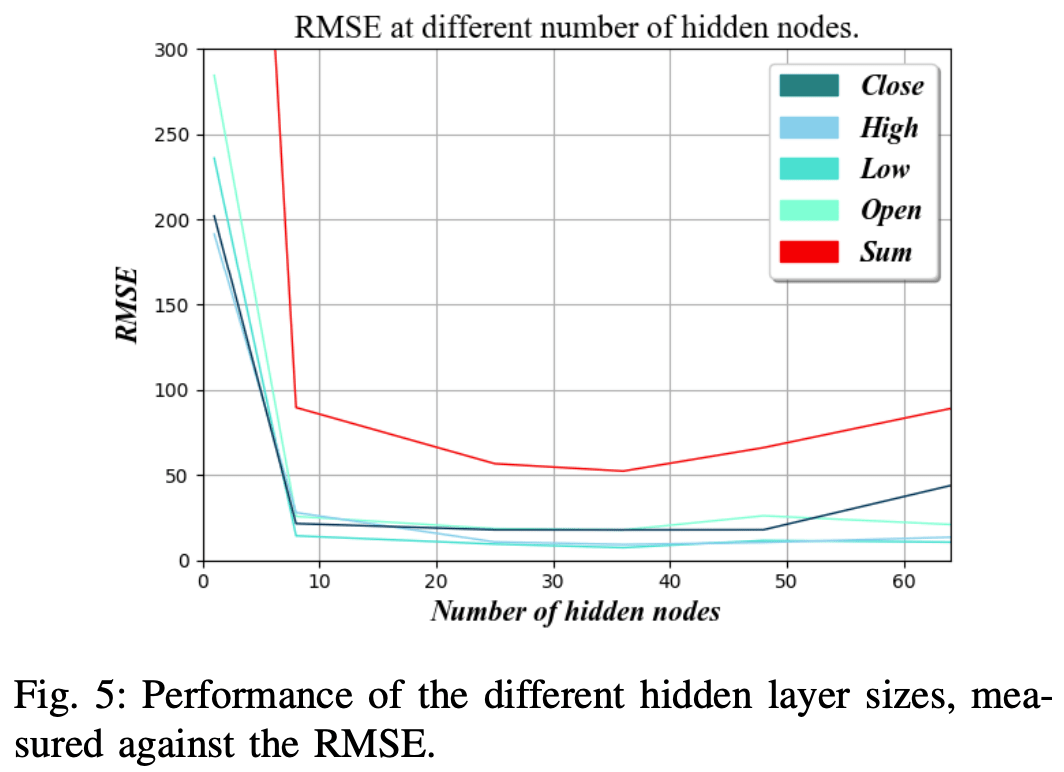
图5显示,当隐藏层的节点数约为36时,RMSE最低。
评估你的交易策略的结果
本节介绍了交易引擎和迄今为止描述的五种交易策略中每一种策略的验证结果,使用的是历史数据。
历史数据作为实时输入的模拟,通过执行假设的交易来更新投资组合。每种交易策略在减少投资组合损失方面的表现,不仅取决于策略本身的质量,而且还取决于用于确定行动方案的预测质量。
这些实验中的递归神经网络利用了上一节所述的优化参数设置,以最大限度地提高预测精度。
每个实验都涵盖了BTC/USDT对的交易,以BTC为基础货币,USDT为报价货币。总价值是通过每期将投资组合转换为所报货币来计算的。然而,如果交易者的表现超过了市场本身,仅实现较高的货币价值并不意味着交易成功。如果BTC/USDT的价值在一定时期内持续上升,那么该交易员就会在不需要做任何事情的情况下获利。这是一种被称为 "买入并持有 "的策略。在这种策略中,你只买入并持有特定数量的资产,不再进行任何交易。从 "与阿尔法比较 "的意义上说,这一战略是一个适当的比较基础。这种比较和实验的结果显示在图6中。
BTC...比特币
USDT...Tether发行的稳定币
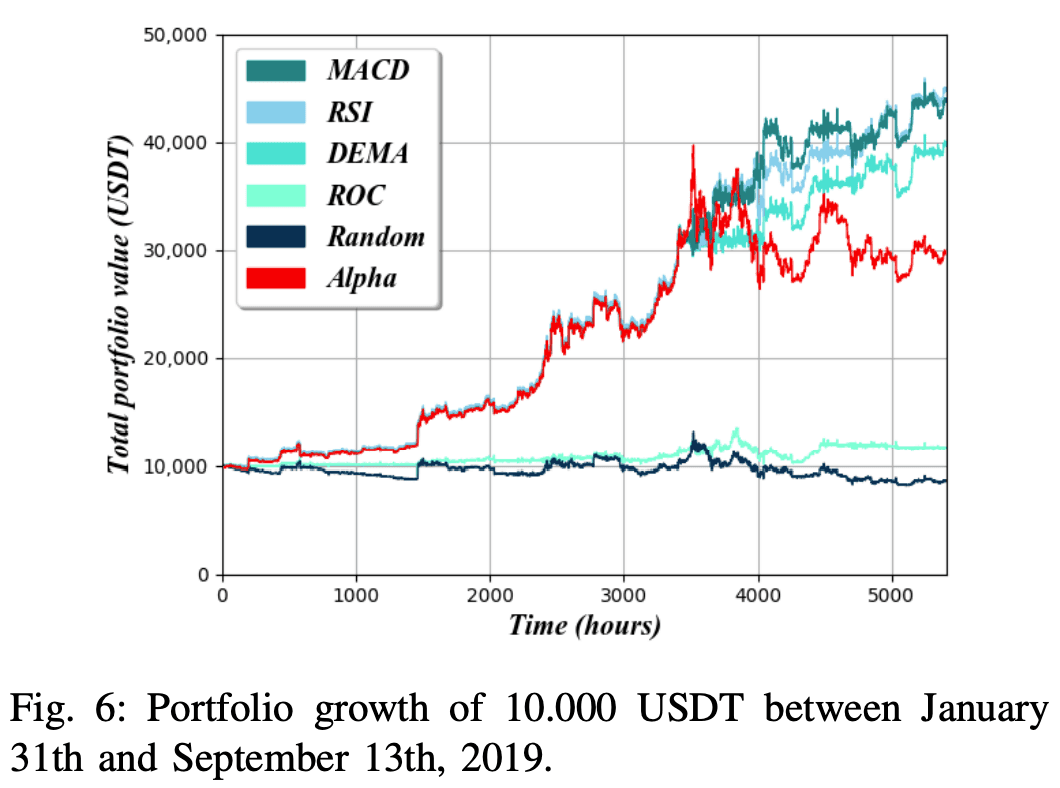
人工智能是在大约90%的数据集上训练的和它被用来预测其余10%的数据。每个策略都是独立测试的,每个策略都收到一个包含10.000美元的初始投资组合,然后使用2019年1月31日至9月13日约5.400小时的股票市场数据进行交易。通过在t = 0时简单地将10.000美元兑换成BTC并没有进一步的交易活动,产生了一个阿尔法基线。
为了取得更稳定的结果,对交易代理人进行了一些限制。主要是,他们在任何时候最多只能交易其总投资组合的25%。另外此外如果基于交易量的预期价值增长低于交易费(设定为0.1%),将不进行交易。
图6显示,在比特币的历史数据中,RSI策略取得了最高的投资组合价值,MACD策略紧随其后,DEMA策略表现稍差。然而,这三种策略都保持了稳定的投资组合价值,赶上甚至超过了阿尔法的基线,ROC策略的表现几乎和随机漫步一样好,都勉强维持在阿尔法基线价值的三分之一。ROC策略的表现与随机漫步相似,两者都勉强维持在Alpha基线的三分之一。
人工智能在某些战略中的表现可以超过阿尔法的基线,但收益是否值得冒险是个问题。
回答这个问题的一个方法是计算夏普比率。这意味着,当与无风险资产相比夏普比率是一个衡量的标准,它是指夏普比率是衡量投资者为其承担的风险获得多少回报的指标。夏普比率为夏普比率所考虑的资产的收益率减去无风险资产的收益率和夏普比率的计算方法是用无风险资产的回报率减去所考虑资产的回报率,再除以所考虑资产的回报率的标准差。
图7显示了在回测期的最后7个月(假设的),即2019年2月13日至9月13日,对六种交易策略中的每一种进行测量的月度夏普比率。回报率R的计算方法是超额回报与每个月开始的比率。关于无风险收益率Rf的确定,每月的美国国库券(T-Bills)是合适的无风险资产,因为该投资组合是以美元计算的。
在回测期间,T-Bills的无风险利率约为2%,如美国财政部网站所示。考虑到这些数字,夏普比率为1或更高,通常被认为是一项好的投资,而夏普比率为2或更高,则被认为是一项优秀的投资。
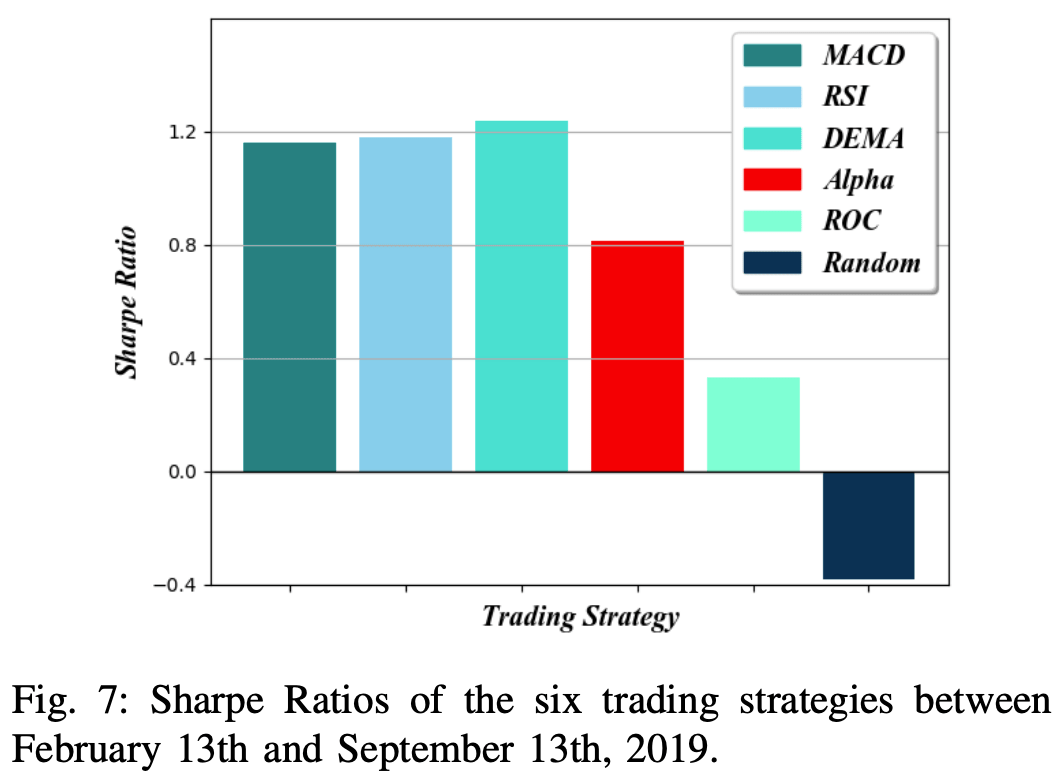
图表显示,RSI和MACD策略实现了最高的投资组合价值,但DEMA策略保持了最高的夏普比率。RSI和MACD策略的高收益(R)以及每个月的无风险利率(Rf)对所有策略都是一样的,这表明RSI和MACD策略取得了最高的夏普比率。
随机漫步策略同时遭受了巨大的损失和高波动性,导致夏普比率低于负值;而ROC策略遭受了类似的损失,但由于低水平的波动性,能够保持正的夏普比率,而ROC策略遭受了类似的损失,但由于低水平的波动性,能够保持正的夏普比率。ROC策略遭受了类似的损失,但由于波动水平低,能够保持正的夏普比率。
摘要
TSKCV结果表明,该网络能够预测新的资产价值,在四个输出通道中的误差约为0.4%。每个策略都成功地在整个历史数据集中以不同的速度保持稳定的投资组合价值,但都比随机策略表现得更好。尽管RCURRENCY已经在比特币上进行了测试,但它的设计已经适应于其他数字资产也是如此。然而,没有一个策略能正确预测到资产价值的大幅突然下跌。然而,这是现有的基于人工智能的解决方案的一个共同问题,未来的研究可以阐明更多的输入数据是否可以提高他们有效预测此类事件的能力。



与本文相关的类别
.JPG)





