何时以及如何使用CNN合集?
三个要点
✔️验证当参数数量相同时,是单一模型好还是集合模型好?
✔️在各种环境下实验并验证了基于CNN的图像分类任务。
✔️证明合奏模型的整体性能更好
More or Less: When and How to Build Convolutional Neural Network Ensembles
written by Abdul Wasay, Stratos Idreos
(Submitted on 29 Sept 2020 (modified: 26 Jan 2021))
Comments: Accepted to ICLR2021.
Subjects: ensemble learning, empirical study, machine learning systems, computer vision
首先
当你想提高深度学习模型的性能时,最简单的方法就是增加模型大小。
但到底是用参数多的单一模型好,还是用参数相对少的多个模型的集合好呢?在本文介绍的论文中,我们从训练时间、推理时间和内存使用量等不同的角度出发,讨论了我们应该使用集合模型还是单一模型的问题,尤其是对于CNNs。
技巧
从下面介绍的政策和方法出发,对集合模型和单一模型进行比较。
公正和公平排名的理论依据
作为一个集合/单个模型的比较,我们比较具有相同数量参数的架构。这里我们没有使用其他指标(训练时间、推理时间、内存使用量等)代替参数数量的原因有两个。
- 因为网络中参数的数量与其他指标成正比。
- 参数数量与使用的硬件等无关,可根据网络规范准确计算。
接下来,我们将介绍我们如何设计和进行单/集合网络架构的对比实验。
关于单体/组合结构
首先,一个单一的CNN架构由$S^{(w,d)}$表示。其中$w$是网络的宽度,$d$是深度,$|S|$是参数的数量。
我们还假设$S^{(w,d)}$属于神经网络架构的$C$类。这里,合奏网络用$E={E_1,.... 表示。...E_k}$.在这种情况下,$E_1,...,E_k。,E_k在C$和$|E_1|+...。+|E_k|=|S|$。换句话说,架构的类与单网的类相同,参数总数也相同。
同时在实验中,所有的合奏网络架构都是相同的($E_1=...)。=R_k$),且参数数量设置为相等($=|S|/k$)。在这些设置下,我们比较了单网和合网。
深度/宽度等效合计
CNN合集网络架构由两种不同的策略决定:深度相等/宽度相等。如下图所示。
简而言之,在深度等效的合集环境下,合集网络的深度与单个网络的深度$d$相同。在宽度等效的合集设置中,合集网络的宽度与单个网络的宽度$w$相同。
在这种情况下,深度等效设置中的宽度$W^{\prime}$设置为参数总数不超过$|S|$范围内的最大值。同样,宽度等效设置中的深度$d^{/prime}$设置为参数总数不超过$|S|$的范围内的最大值。这用一个数学表达式表示如下:
$w^{/prime}: k \cdot |E^{(w^{/prime},d)}_i| \leq |S^{(w,d)}| \leq k \cdot |E^{(w^{/prime}+1,d)_i}|$。
$d^{prime}: k \cdot |E^{(w,d^{/prime})}_i| \leq |S^{(w,d)}| \leq k \cdot |E^{(w,d^{/prime}+1)_i}|$。
总的来说,我们比较了(i)属于同一网络架构类$C$的单个网络$S^{(w,d)}$,(ii)$k$宽度相等的合集$S^{(w,d^{\prime})}$,和(iii)$k$深度相等的合集$S^{(w^{\prime)},d)}$进行对比实验。
实验
实验设置
数据集
实验中使用的数据集如下。
- SVHN
- CIFAR-10
- CIFAR-100
- 小小图像网
- 下采样图像网-1k
-架构
我们实验中使用的CNN架构如下。
- VGGNet
- ResNet
- DenseNet
- 广泛的ResNet
评价指数
为了比较单网和合网,我们从以下五个方面进行评价。
- 归纳精度
- 每个时代的培训时间
- 达到指定精度的时间(精度时间)。
- 推理时间
- 内存使用情况
高级设置
超参数和其他架构的细节如下。 我们使用PyTorch作为实验框架和Nvidia V100 GPU进行执行。
结果
精度比较
EST(Ensemble Switchover Threshold)的发生率。
实验结果证实了当资源超过一定阈值时,深度/宽度相等的两个合集都优于单网的现象。
在本文中,我们将其命名为EST(Ensemble Switchover Threshold)。如下图所示。 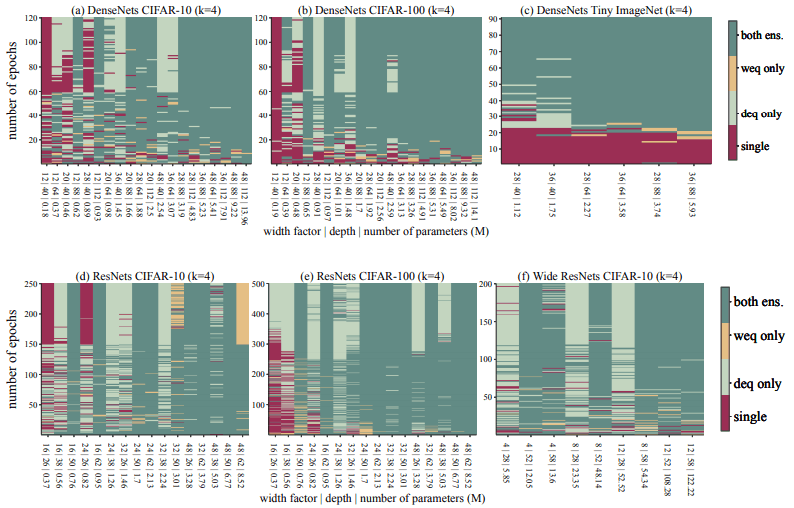
在此图中,我们可视化了单网络(single)、深度等效(deq)和宽度等效(weq)合集中哪个是主导。可以看出,当参数数量增加到一定程度时(向右),集合法成为主导。
此外,DenseNet模型的测试错误率如下。
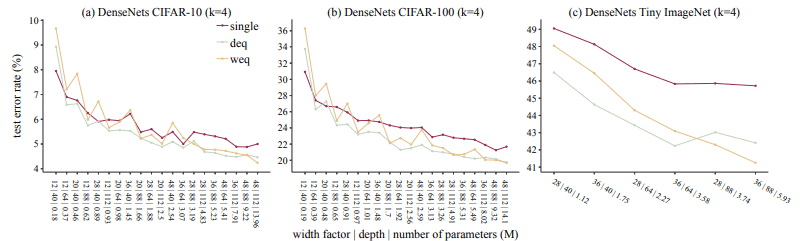
同样在这里,当参数数量稍大时,合集法总体上是占优势的。这种EST发生在资源少到中等的时候(约1M到1.5M的参数,且小于一半的训练时长)。因此,可以说,结果表明,即使在资源不大量存在的情况下,合集很可能更有用。
总的来说,这些结果表明,在非常广泛的用例中,合奏可以优于单个网络。
为了更有效的合奏
经过我们的实验,我们观察到有效使用集合模型有以下三个发现。
1.数据集越复杂,集合就越有效。
训练数据集越复杂,EST就越接近原点(纪元数和参数数都越小)。
2.在足够大的参数预算下,增加合奏网络的数量是有效的。
如下图所示,合奏网络的数量($k$)越大,EST越向右移动(需要更多的参数数量)。
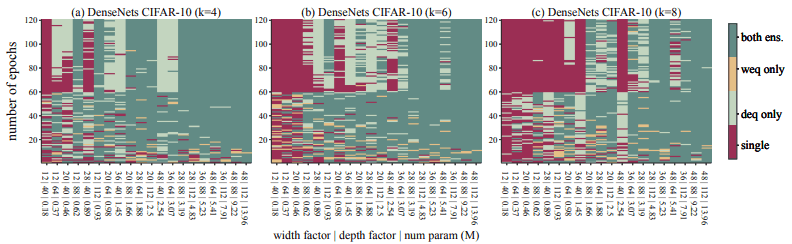
因此,如果我们要增加合奏网络的数量,还必须保证足够多的参数,否则就不能指望提高精度。
3.深度等效合集比宽度等效合集显示出更好的准确性。
对于深度/宽度等效的合集,我们发现深度等效合集的整体精度更高。这可以归因于现代CNN架构的设计是随着层的深度增加而提高精度。
时间方面的比较
训练时间比较
单个网络模型的精度所需的训练时间如下图所示。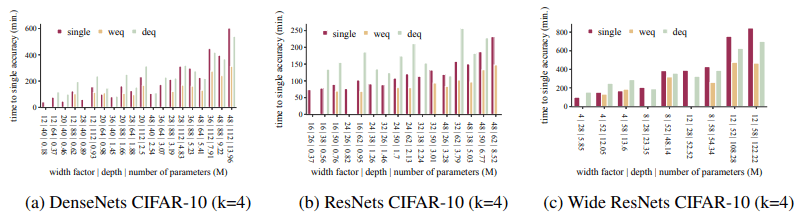
(没有柱状物表示不能达到单一网络模型的精度)。
总的来说,合奏达到单网络模型的精度要快得多(在我们的实验中是1.2到5倍)。此外,每个纪元的训练时间如下。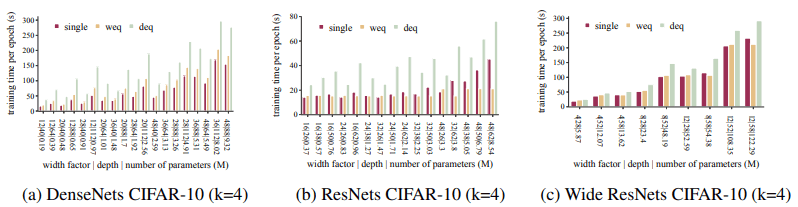
Ensembles在每个时代需要更长的时间来训练,因为他们在深度/宽度相当的情况下都会训练$k$网络。
在这种情况下,深度等效的合集与宽度等效的合集相比,每期的学习时间增加了约2倍。从收敛时间来看,合集的收敛速度比单网快。
这可以归结为合奏中的所有网络都比单个网络小。一般来说,合集所需的训练时间并不比单网多,说明合集可以用较少的训练时间达到单网的精度。
推理时间的比较
下图显示了每张图像的推理时间。 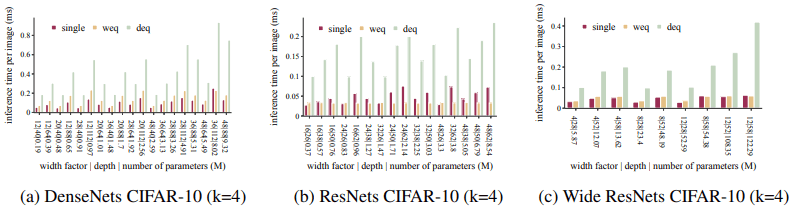
对于推理时间,我们看到的趋势与每个纪元的训练时间类似。也就是说,宽度等效的合集显示出与单个网络相当的推理速度,而深度等效的合集则慢得多。
内存使用情况比较
各项设置的内存使用情况比较如下所示。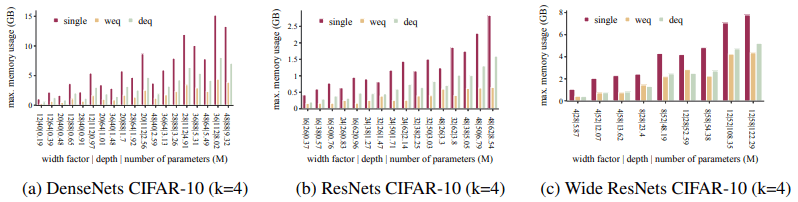
这代表了前面所说的超参数设置中GPU所需的最小内存量。这个结果是由于训练一个合集网络时所需的内存量与训练其中一个$k$网络所需的内存量相同。这种内存效率的优势是存在的,比如在内存受限的环境下,可以增加批处理量,提高训练效率。
摘要
在本文中,我们介绍了我们对是否使用合集的决策分析。
一般来说,结果表明,当参数数量相同时,合集模型比单个模型更准确,可以更快地进行训练,能够进行等价推理,并且可以显著减少所需的内存量。
虽然实验中验证的内容有一定的局限性(例如,合集中的网络必须是相同的,而且该研究并没有验证图像分类以外的其他内容),但这是一项提供了非常有意义信息的研究。



与本文相关的类别






