如何将人工智能用于经济和金融市场的预测?介绍基于网络拓扑的企业性能预测!
3个要点
✔️关于企业破产风险和业绩预测的论文
✔️基于产品相似性,使用网络的拓扑特征。
✔️与财务信息结合使用,以提高准确性。
Topology of products similarity network for market forecasting
written by Jingfang Fan, Keren Cohen, Louis M. Shekhtman, Sibo LiuJun MengYoram LouzounShlomo Havlin
(Submitted on 28 Aug 2019)
Comments: Applied Network Science volume 4, Article number: 69 (2019)
Subjects: Machine Learning (cs.LG); Machine Learning (stat.ML)
首先
本文将就经济预测中的一个主要问题:金融市场风险的检测和预测进行介绍。
这是一篇有点老的论文,发布于2019年,技术本身并不新,但这是我们在AI-Scholar这里没有怎么涉及的领域,所以我想在这里介绍一下。
我相信有很多从事人工智能工作的人,对股票和经济预测感兴趣,但我想这可以让你了解人工智能在金融和经济预测领域的应用氛围,以及使用什么样的数据。
关于网络科学
事实证明,网络科学是研究许多现实世界系统的有用工具,因为它已被用来预测许多自然和技术现象,如传染病的流行、城市发展的预测、极端气候的预测以及科学家影响力的变化。
网络科学方法也被应用于金融领域(如描述金融系统的不稳定性,研究金融网络结构与风险传染导致的失败之间的关系)。
对构建的网络进行分析,将考察各种指标
- 地方特色
- 基本上统计了子图的频次。
- 如:度、小规模动机、聚类系数等。
- 分层指数
- 如果网络按照某种等级机制进行排序,基本上可以衡量一个节点在网络中的位置。
- 中心性指数
- 每个网络特征都反映了不同企业产品相似性之间的不同类型的对应关系。
- 如:近似中心化、K核、K壳等。
在过去的几年里,也有人努力将网络和机器学习结合起来,预测一类节点和整个网络。在如何从网络中生成特征方面也有一些有趣的想法,比如node2vec(下面的例子:细节省略)。
- 网络邻接矩阵的特征向量。
- DeepWalk
- 基于光谱的卷积
- node2vec
- 诸如此类
在这里,特征生成的一个重要角度是使用更复杂的拓扑特征,而不是简单地使用图作为相似度测量。虽然许多现有的方法都忽略了图的拓扑特征,但我们最近已经发现来自图的拓扑特征可以提供非常好的节点和边的特征,对于分类问题非常有用。作者还提出用基于拓扑结构的方法来预测公司的业绩。
建议的方法
现在我们将开始解释所提出的方法。作者提出了一种结合文本分析、网络理论和基于拓扑结构的机器学习的方法。
这一过程的具体步骤是:首先,对证监会From 10-K表上市公司的产品说明进行文本分析,构建公司之间的产品相似性网络。他们将企业视为网络中的节点,企业产品之间的相似性用网络的链接(强度)来表示。然后,他们利用构建的网络的拓扑特征,通过机器学习来预测企业的业绩和破产风险。
我们先来解释一下他们使用的是什么样的数据。
数据:产品相似度数据
作为数据,美国证券交易委员会(SEC)编制的名为From 10-K表的公司年报很有用。本文利用各企业之间发布的产品说明,通过进行文本分析计算产品相似度。
具体来说,首先在From 10-K表格中提取每年产品描述中使用的独特词汇列表,并建立每年的数据库。接下来,我们从每个公司的产品描述中提取文本,构建一个二进制的N维向量,总结该词的使用情况(如果该词被使用,则为1,否则为0)。这就像为每个公司创建一个弓。将这种方式得到的向量进行归一化处理,取企业间的余弦相似度计算相似度。在这项研究中,他们使用了18年的数据(从1996年到2013年)。
传统上,传统的行业分类,如SIC代码被用作参考,但随着时间的推移,这种情况并没有改变,在实践中,分配并不准确,因为公司可以有各种属于不同部门的产品分部。说到这里,作者也认为,所提出的相似性指数具有优越性。
数据:外部财务数据
除了产品相似性,还介绍了构建金融变量的数据。
例如,从证券价格研究中心(CRSP)下载标普500指数的每日收盘价,可以用来衡量整体市场动态。为了控制观察到的企业特征的范围,他们还使用几个企业特定变量来确定企业规模。具体来说:Fama和French等人的研究。如以下建议企业规模被定义为以下指数之和我们假设企业规模为市值之和。
- 账面与市场比率
- 账面市价比是指账面价值与市价净资产的比率,可以用来评价公司的发展机会。
- 杠杆
- 衡量资本结构的指标,定义为长期债务和其他债务(流动负债)与长期债务、流动负债中的债务和股东权益之和的比率。
- 利润率
- 界定为未扣除特殊项目前的总资产延迟的利润。
- 前一年的回报
- 过去一年的股票回报率
- 投资
- 总资产同比增长
- 流动性
- 衡量公司的流动性
- 奥特曼Z-score
- 违约风险指数
关于如何获得每项指标的详细情况,可以在本文的参考文献中找到。数据也可从Compustat数据库下载(http:/www.compustat.com)。
构建产品相似性网络
现在开始解释一下实际的网络建设。对于每一年,根据上述产品相似度构建一个加权的非定向网络。节点对应于每个公司,链接对应于节点之间的相似度,并有其相似度$w$。如果链接的相似度大于一个阈值(这里是10^{-4}$),允许对链接进行拉伸。
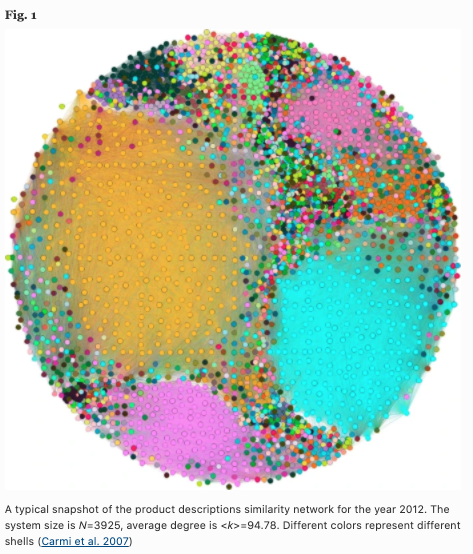
因此,下图显示了2012版产品的相似度网络。现在节点数为3925个,平均度数为94.78。请注意,颜色代表特定的外壳。
创建网络的拓扑特征
网络的拓扑测量已经被用来预测公司未来的利润和破产概率。基于Rosen等人和Naaman等人的方法,作者计算出一个代表每个节点的拓扑特征集的向量,从而产生一个拓扑网络属性向量(NAV)NAV中使用了以下特征。
- 程度
- 中心性
- 衡量一个节点的中心性,如果它在许多其他节点之间形成桥梁,则被认为是重要的。
- 正中率
- 这也是衡量一个节点的中心性,从除自己以外的所有节点到自己的最短路径长度之和越小越大。
- 距离分布矩
- 用Dijkstra算法计算每个节点到所有其他节点的距离分布,并取该分布的一阶和二阶矩。
- 流动
- 定义为该节点与所有其他节点之间的定向与非定向距离之比。
- 网络图案
- 用Itzchack算法的扩展计算出的连接的小子图的模式(扩展到非直接图)。
- 对于每个节点,计算该节点参与的主题频率。
- K型芯
- 只包含k度或更大的顶点的最大子图。
网络分析
现在我们将介绍作者进行的一些分析结果,以证实所提出的方法所得到的网络的特性。
公司之间的联系强度趋势
考虑每一年网络的链路强度w的概率密度函数$p(w)$。下图是六年的结果,我们可以看到,每年的趋势都是一样的,遵循近似指数分布。
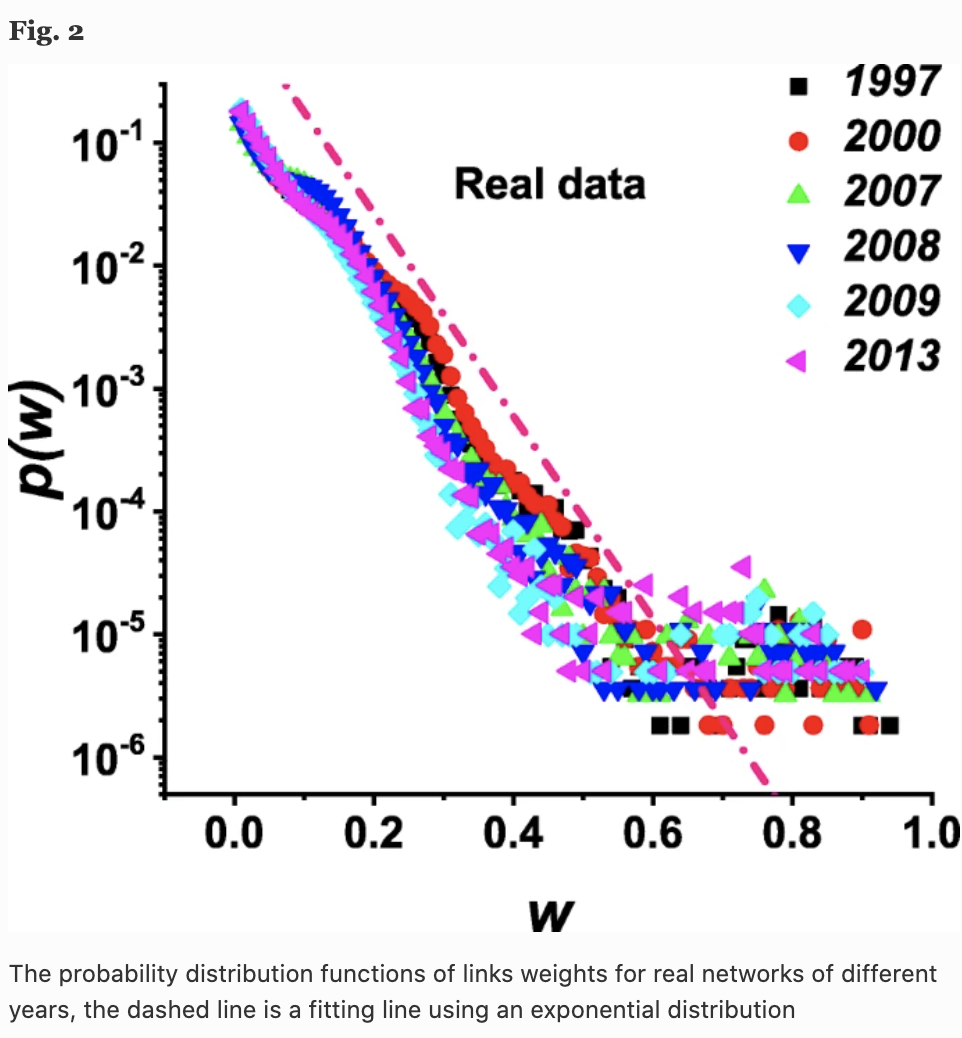
需要注意的是,产品相似度的值可能反映了产品的市场协同效应或并购竞争,较高的$w$可能意味着两家公司具有高度的竞争关系或合作关系。
节点的加权顺序
我们计算加权顺序,定义如下
$$s_i = \sum_{j = 1}^N a_{ij}w_{ij}$$
其中$a_{ij}$是邻接矩阵,$s_i$是节点$i$的强度,用其连接的总权重来量化。在产品相似性网络中,这应该反映出公司$i$在网络中的重要性或影响力。在下图中,我们可以看到度数为$k$的节点的强度$s(k)$随着$k$的值增加,根据$s \sim k^{\beta}$。
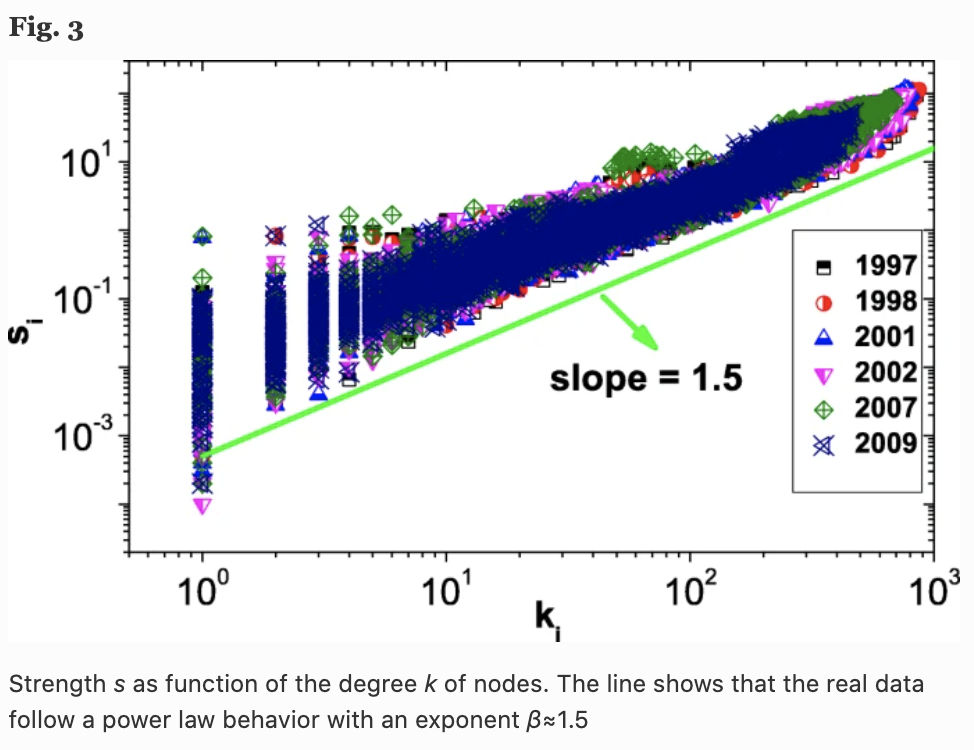
事实上,我们也可以看到,这个幂律$beta$的值约为1.5,也就是说,一个节点的强度比它的度数增长得更快。这意味着连接度较高的节点(公司)的边缘权重往往具有较高的数值。
集群系数
在加权网络的情况下,节点$i$的簇系数被定义为子图中边的权重的几何平均值,具体如下所示。计算出每个节点的聚类系数,并进一步分析找出各年各网络的平均聚类系数。
$$c_i = \frac{1}{k_i(k_i - 1)} \sum_{j,k} (\hat{w_{i,j}}\hat{w_{i,k}}\hat{w_{j,k}})^{\frac{1}{3}}$$
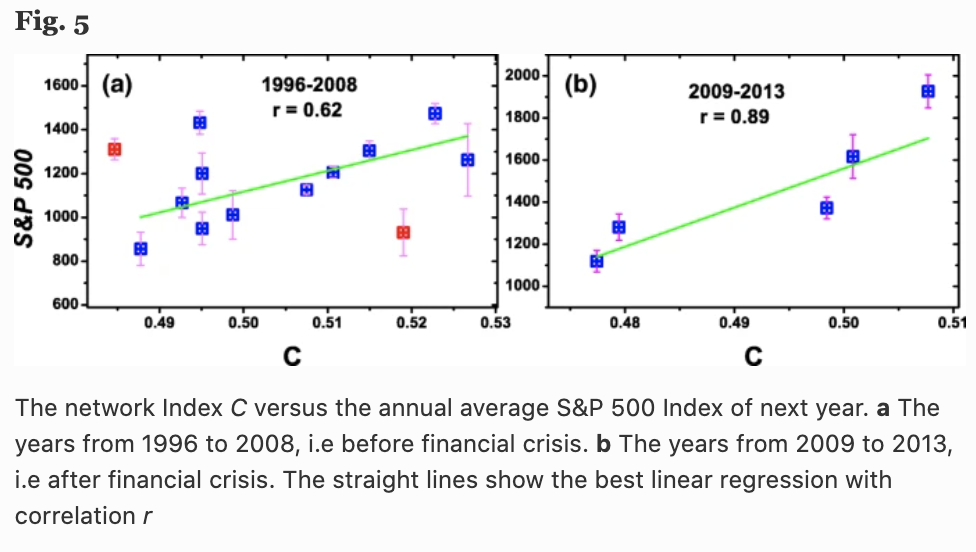
下图中,(a)显示了平均聚类系数$C=\frac{1}{N} \sum_{i=1}^N c_i$随时间(年)的变化,(b)显示了标准普尔500指数。有趣的是,我们可以看到,平均聚类系数$C$(提前一年)与标准普尔500指数的行为之间有很高的相关性(图5)。
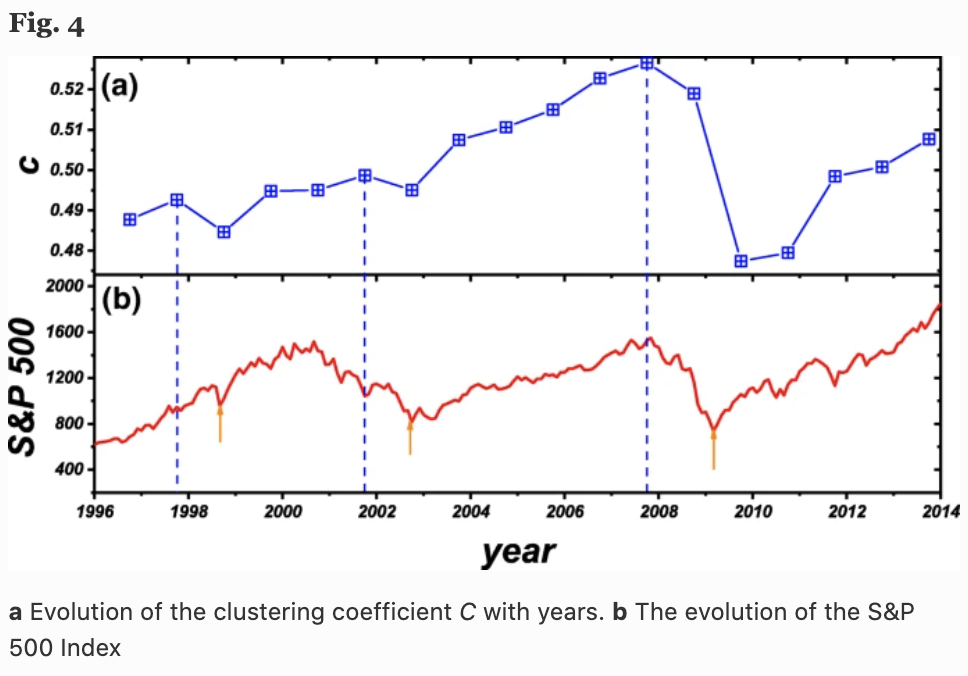
这里在图4中,我们看到了三个局部的$C$最大值(蓝色虚线)和三个局部的标普500最小值(红色箭线),它们代表了三次金融危机(亚洲金融危机、网络泡沫、雷曼冲击等)。$C$的局部最大值总是在标准普尔500指数的最低点前一年。这意味着,网络的平均聚类系数$C$可以帮助预测下一年的股市收益。
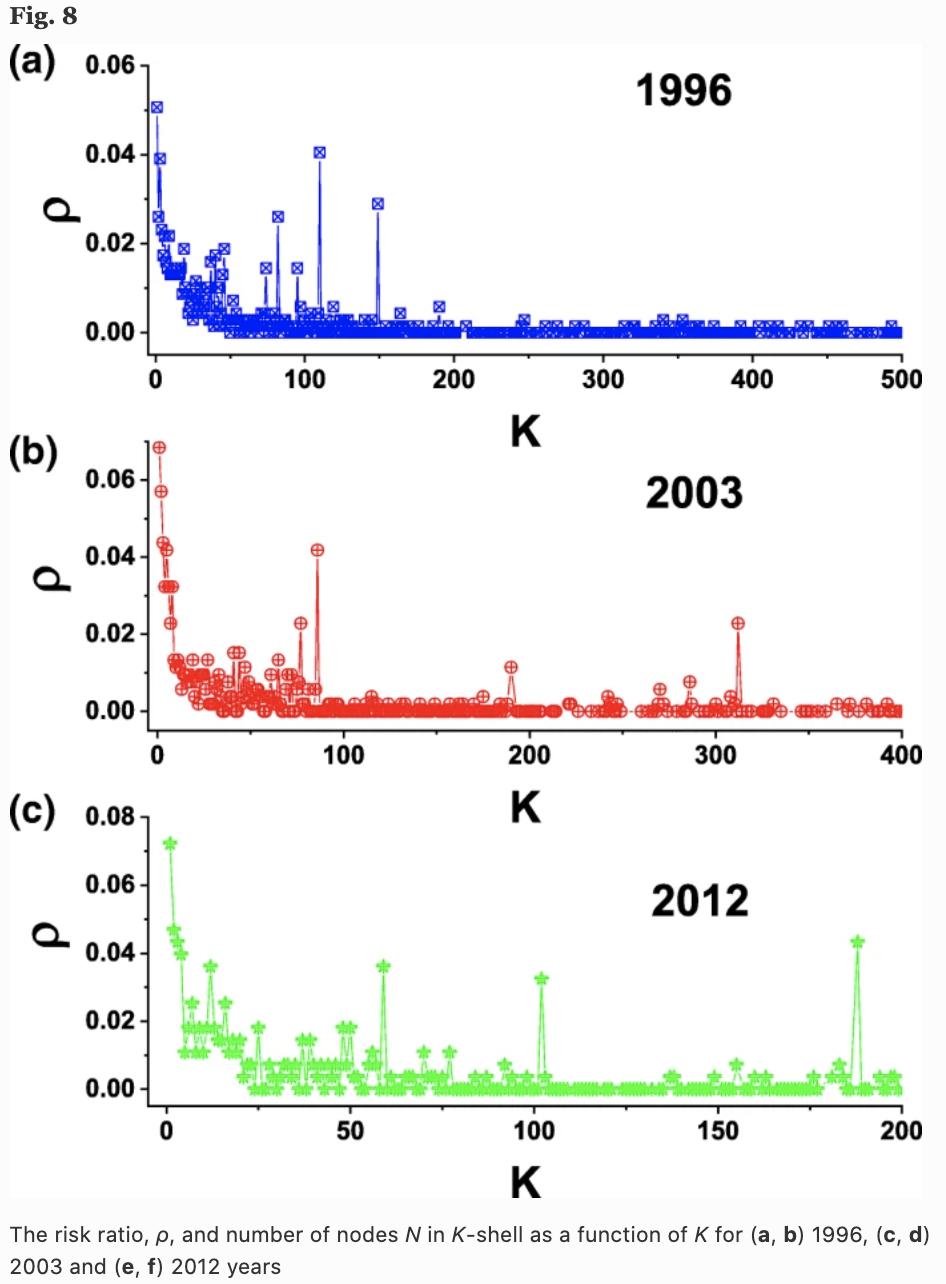
k-shell结构分析
为了显示网络拓扑特征的重要性,他们还分析了k-shell结构。下图显示了1996年、2003年和2013年这三年中,每次序顺序序壳公司次年消失的比率$p$。可以看出,属于外阶的企业破产风险较高(虽然这可能是自然的,因为畅销的产品是由很多企业生产的)。
实验
至此,对网络的特点介绍完毕。接下来,我们使用构建的网络与网络的拓扑特征,并实际训练和验证其性能。现在利用构建的网络的拓扑特征来训练和验证其性能。
实验设置
在某一年的网络中,70%的节点被分成训练数据集,其余30%的节点被分成测试集。对每个节点计算净资产收益率,并进一步标注公司在下一年度是否破产(以及合并或私有化),以及下一年度是否在收益率前5%(Top)以内。在随机森林中训练这些标签,并测试它们是否比随机情况更好(AUC:0.5)。
实验结果
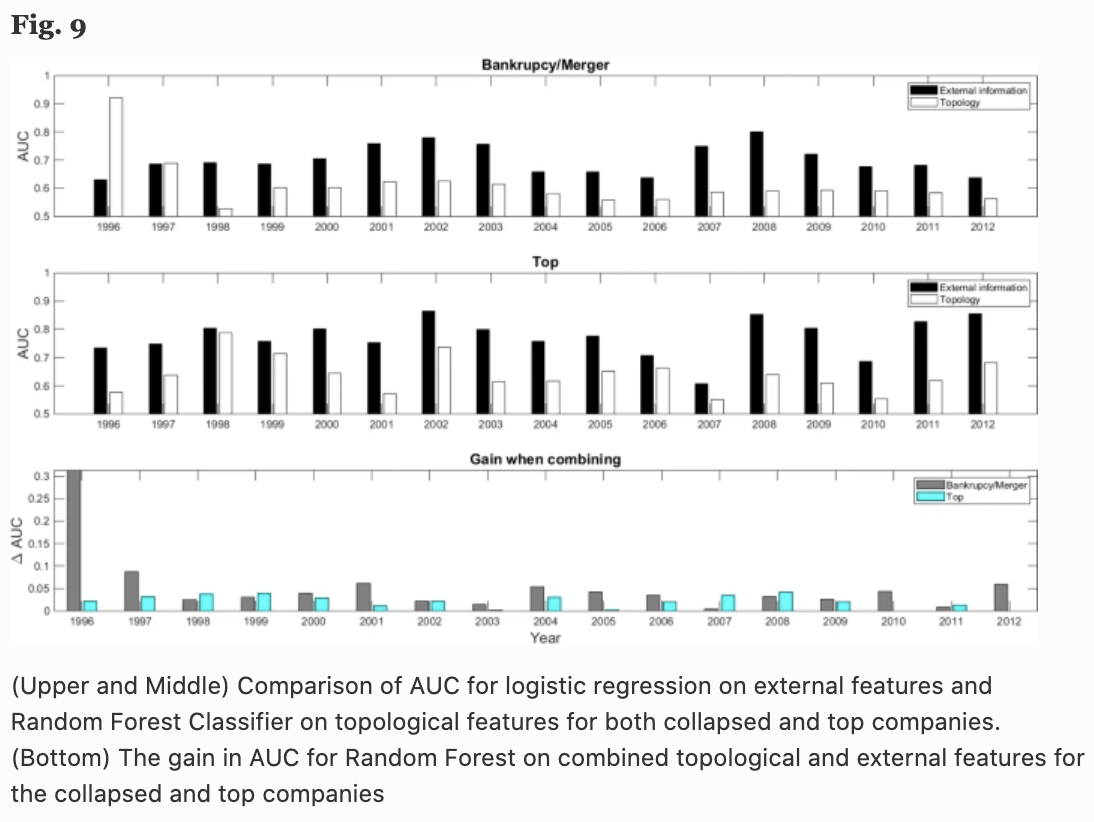
图9的上图显示了破产和合并的AUC,中图显示了破产和合并的AUC。预测下一年收益率是否在前5%以内的AUC。可以看到,在所有17年的测量中,所提出的网络的拓扑信息都优于随机预测(AUC:0.5)。
为了便于比较,我还包括了基于标准财务指标(公司规模、盈利能力、上年回报率、投资、流动性、杠杆率、账面市值比和Altman Z-score)的逻辑回归的AUC(黑条)。条形图)。)
从这些结果来看,似乎是个不好的结果,但单凭产品相似度网络,是不如上述财务指标的预测的。但从图9的下半部分可以看出,当上述财务指标与产品相似性网络的拓扑特征相结合时,AUC有所提高,几乎所有年份和类别的准确率都有显著提高。换句话说,结果表明,作者提出的网络拓扑信息可以在预测未来破产和收益方面发挥重要作用,并可以补充传统的使用逻辑回归的方法。
还尝试将破产和合并作为单独的类别进行分类,因为即使在同一节点(公司)消失的情况下,它们也有不同的含义(图10),尽管在图9中对破产、合并和私有化使用了相同的标签。
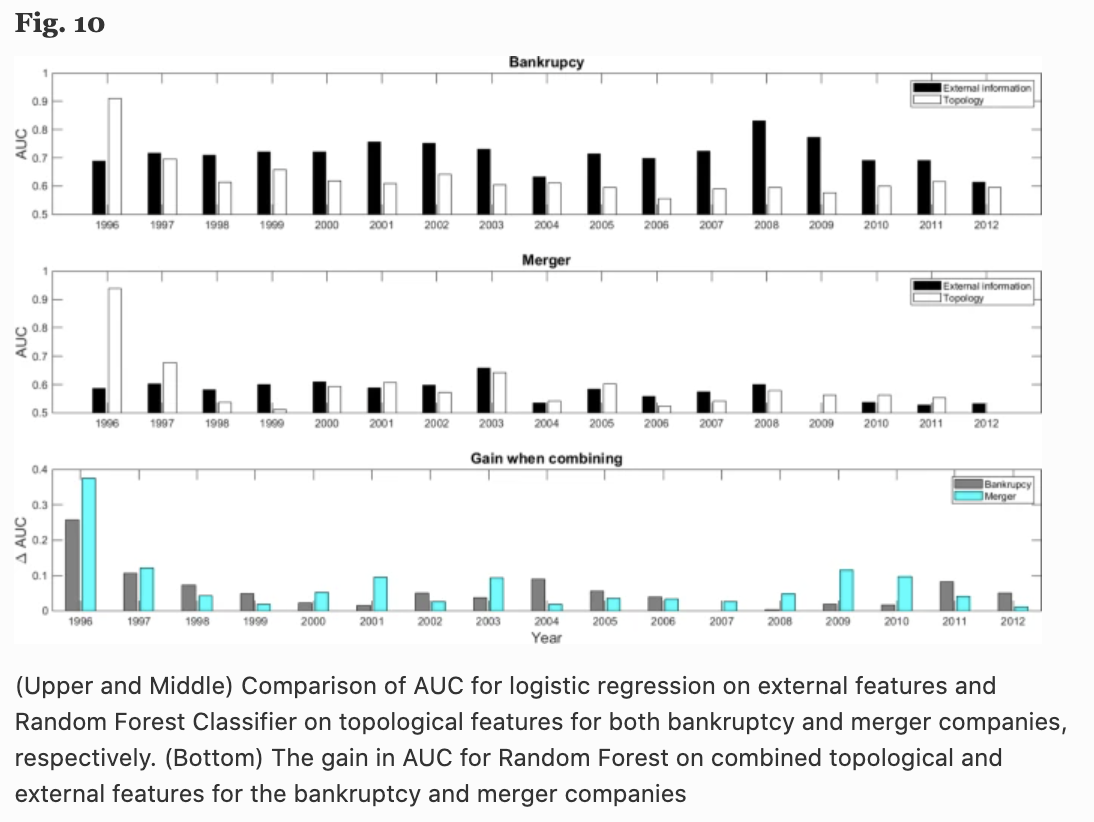 结果表明,在破产的情况下,财务信息等公司内部信息很重要,而在合并的情况下,拓扑和财务信息都很重要。但是,可以看到,在这两种情况下结合拓扑信息可以得到更好的结果。
结果表明,在破产的情况下,财务信息等公司内部信息很重要,而在合并的情况下,拓扑和财务信息都很重要。但是,可以看到,在这两种情况下结合拓扑信息可以得到更好的结果。
这些结果表明,由产品相似性构建的网络的拓扑特征对预测公司未来的业绩是有用的。
摘要
我介绍一些在经济和股票预测领域正在使用的有趣方法。这一次,它是文本分析、网络科学和机器学习的结合。方法,但也有其他方法。这个领域就像一门混搭的武术,涉及到各种各样的数据和方法,我觉得把NLP、CV、深度学习、强化学习等更先进的方法结合起来,可以提出更多有趣的想法。有很多方法,根据想法而定。我认为这是一个非常有趣的话题。
如果有什么有趣的方法,我再试着介绍一下。



与本文相关的类别






