
提出了一个新的任务,称为Deep Imbalanced Regression (DIR),这是作者面临的一个真实世界的问题
三个要点
✔️ 提出了一个新的任务,叫做Deep Imbalanced Regression(DIR)
✔️ 提出了一种新的方法,称为LDS和FDS
✔️ 构建了5个新的DIR数据集
Delving into Deep Imbalanced Regression
written by Yuzhe Yang, Kaiwen Zha, Ying-Cong Chen, Hao Wang, Dina Katabi
(Submitted on 18 Feb 2021 (v1), last revised 13 May 2021 (this version, v2))
Comments: Accepted by ICML 2021.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
code:
本文所使用的图片要么来自论文件,要么是参照论文件制作的。
简介
现实世界的数据往往显示出不平衡的分布,对某一特定目标的观察明显较少。在利用这种不平衡的数据进行学习方面,已经有很多工作。在这种情况下,大多数研究都假设有明确界限的类别。也就是说,大多数现有的处理不平衡数据/长尾分布的方法只针对目标是不同类别的离散值的分类问题而设计。然而,在现实世界中,有许多任务的目标是连续的。
作者提出了一种针对连续值和不平衡数据/长尾分布中此类目标的学习方法,并构建了五个新的基准DIR数据集,涵盖计算机视觉、自然语言处理和医学问题中的不平衡回归任务。 然后介绍了主要的贡献。
- 我们提出了一个新的任务,叫做深度不平衡回归(简称DIR),我们把它定义为从具有连续目标的不平衡数据中学习,可以推广到整个目标范围。
- 为了解决从具有连续目标的不平衡数据中学习的问题,我们提出了两种新的不平衡回归方法:标签分布平滑法(LDS)和特征分布平滑法(FDS)。我们建议
- 建立五个新的DIR数据集,涵盖计算机视觉、自然语言处理和医学,以促进未来对不平衡数据的研究。
数据不平衡在现实世界中无处不在,每个类别都有长尾的偏态分布,而不是理想的均匀分布,而且在某些目标值上的观测值明显较少。 这给模型带来了重大挑战,有人认为这种非均匀性问题阻碍了机器学习在现实世界的应用。
到目前为止,学习技术大致可以分为数据库和基于模型的方法。 基于数据的解决方案包括对少数群体类别进行超额取样,对多数群体进行欠额取样。基于模型的方法涉及使用特定的相关学习技术,如损失函数的重新加权或转移和元学习。然而,现有的从不平衡数据中学习的方法主要是处理离散的目标值,如上所述。
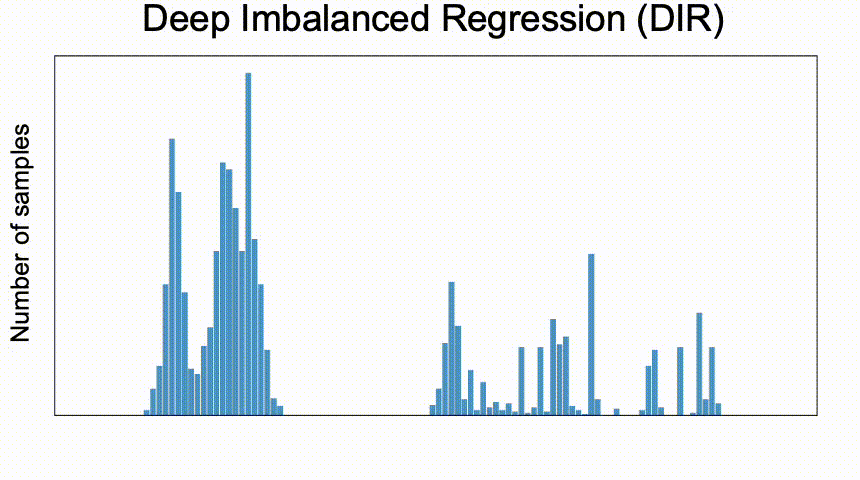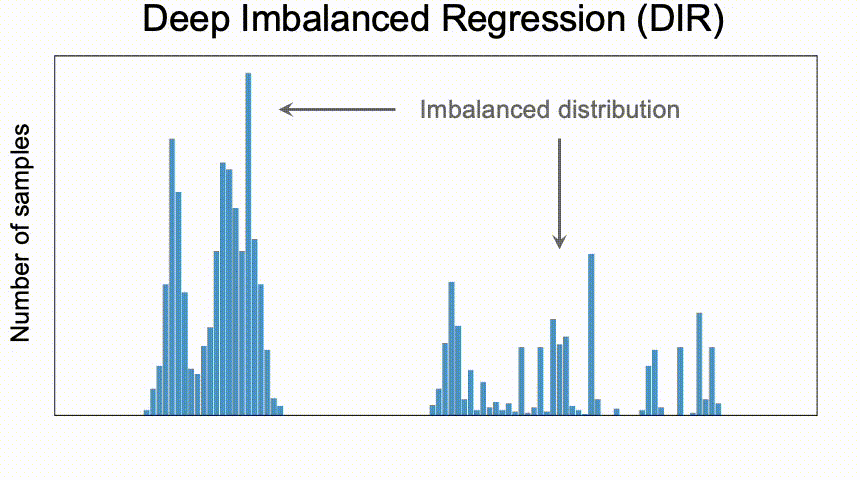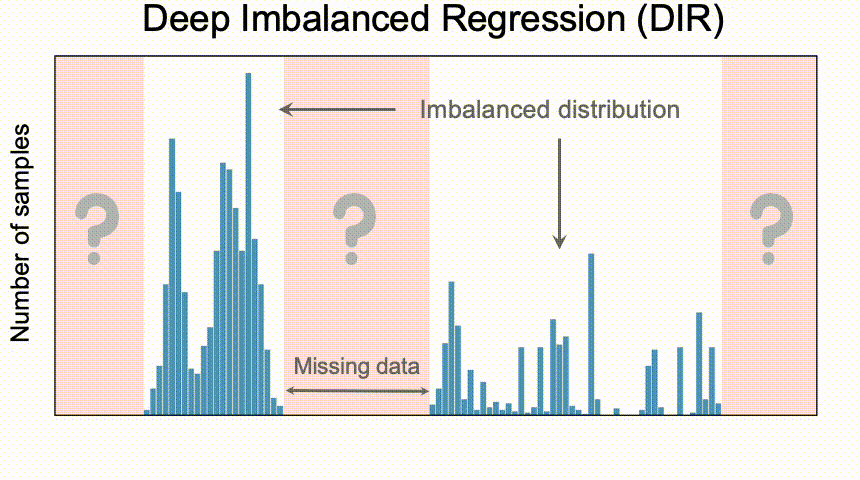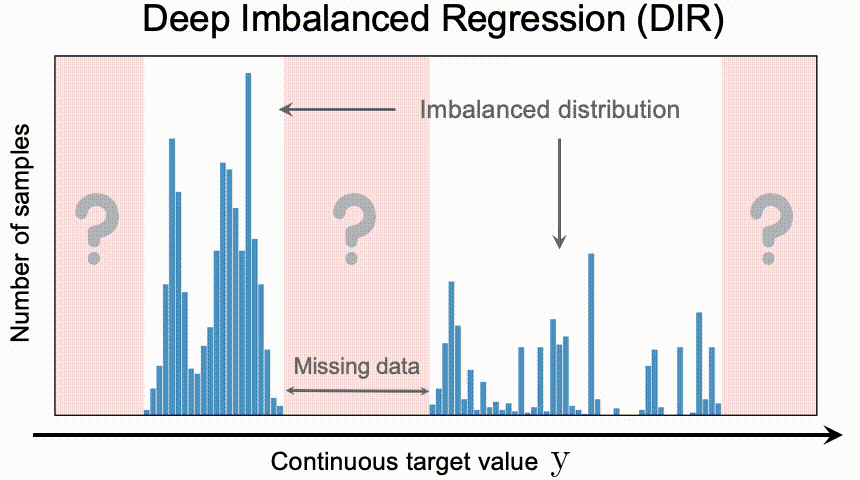
例如,从脸部估计年龄如何?年龄是一个连续值,我们希望它在目标范围内有很大的偏差。这就是为什么我们可以期待婴儿和老年人的训练数据更少。
深度不平衡回归:DIR
深度不平衡回归(DIR)旨在从具有连续目标值的不平衡数据中学习,处理某些区域的潜在缺失数据,并使最终模型能够泛化到全部目标值。
困难和挑战
值得注意的是,与不平衡分类问题相比,DIR带来了一系列全新的挑战,包括
- 考虑到一组连续的目标值,类别之间没有硬性界限。因此,传统的方法,如重新取样和重新加权,不能直接应用。
- 就目标之间的距离而言,连续标签是有意义的。这些目标直接告诉我们哪些数据比较接近,哪些比较远。这个有意义的距离也进一步指导我们应该如何理解这个连续区间的数据的不平衡程度。
- 与分类问题不同,在DIR中可能根本没有目标值的数据。 因此,有必要对目标值进行外推或内插。
综上所述,上述问题表明,与传统的问题设置相比,DIR带来了新的困难和挑战。那么,我们应该如何进行DIR? 在接下来的两节中,我们将讨论标签分布平滑(LDS)和特征分布平滑(FDS),分别利用标签和特征空间中相邻目标的相似性来改进模型。(LDS)和特征分布平滑(FDS),分别。
建议的方法
标签分布平滑化(LDS
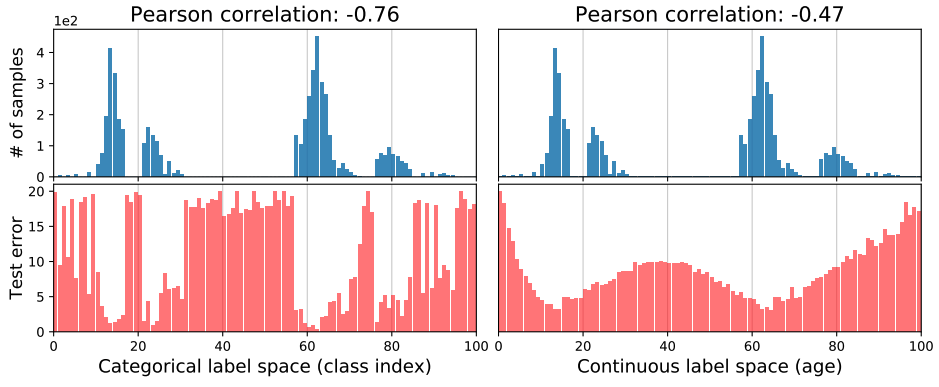
为了说明在数据不平衡的情况下,分类和回归问题之间的区别,我们提出了一个简单的例子,使用两个不同的数据集,CIFAR-10(100级分类数据集)和IMDB-WIKI(用于从人类外表估计年龄的大型图像数据集)。(一个大型图像数据集,用于从人的外表估计年龄)。) 这两个数据集本质上是非常不同的标签空间:CIFAR-100是一个分类标签空间,即它的值是类别索引;IMDB-WIKI是一个连续标签空间,即它的值是年龄。 为了确保两个数据集有相同的标签范围,IMDB-WIKI的年龄范围被限制在0-99岁。 此外,为了模拟数据的不平衡性,两个数据集都被采样,使标签的密度分布完全相同,如下图所示(蓝条)。这些数据集原本是完全不同的,但我们只是匹配了标签的密度分布。
然后,我们在两个数据集上训练ResNet-50模型,并绘制测试误差分布图(红条)。从图的左边,我们可以看到,错误分布与标签密度分布相关联。具体来说,作为类指数的函数,测试误差与类别标签空间中的标签密度分布显示出高度的负相关(-0.76)。这种现象很容易从以下事实中预料到:拥有大量样本的班级比拥有少量样本的班级学习效果更好。
然而,有趣的是,如图右侧所示,IMDB-WIKI在连续标签空间显示出非常不同的错误分布,尽管标签密度分布与CIFAR-100相同。特别是,误差分布更加平滑,与标签密度分布的相关性更小(-0.47)。这个例子似乎很有趣,因为直接或间接地,所有的不平衡学习方法都是通过补偿经验标签密度分布中的不平衡而工作的。这对类的不平衡很有效,但对于连续的标签,经验密度不能准确反映神经网络看到的不平衡。因此,在连续标签空间中,基于经验标签密度对数据中的不平衡进行纠正是不准确的。
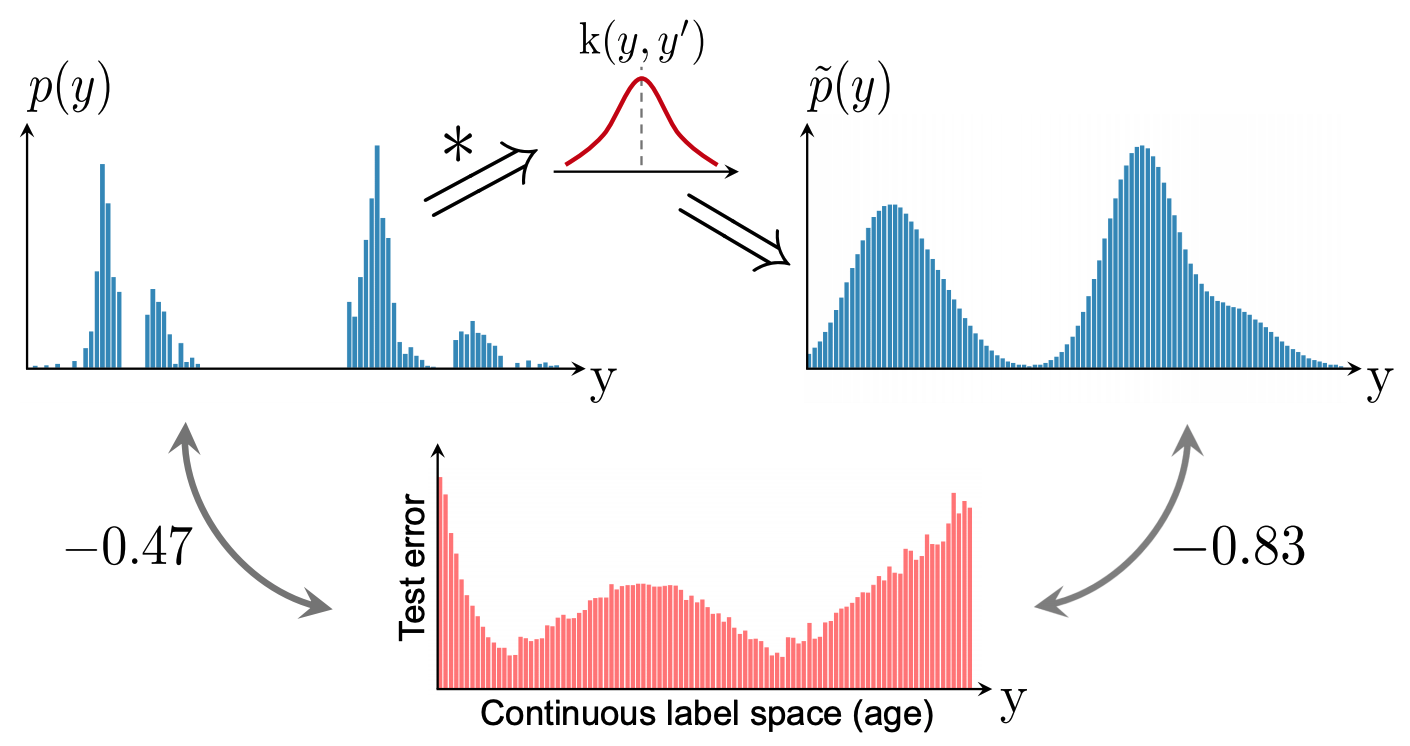
基于这些结果,提出了标签分布平滑法(LDS)来估计对连续标签情况有效的标签密度分布。本文的方法是利用统计学习领域中的核密度估计的思想来估计预期密度。具体来说,给定一个连续的经验标签密度分布,LDS使用一个对称的内核分布函数k与经验密度分布进行卷积,得到
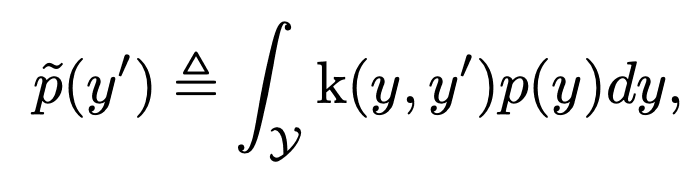
我们可以确认,有效标签密度分布与LDS计算的误差分布之间的皮尔逊相关系数为-0.83,这是一个良好的相关性。 这意味着LDS可以用来创建不平衡的标签分布,对回归问题产生实际影响。
特征分布平滑(FDS)。
下面是FDS的概览图。
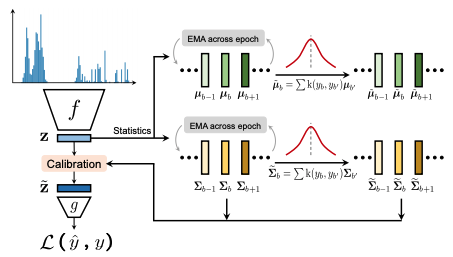
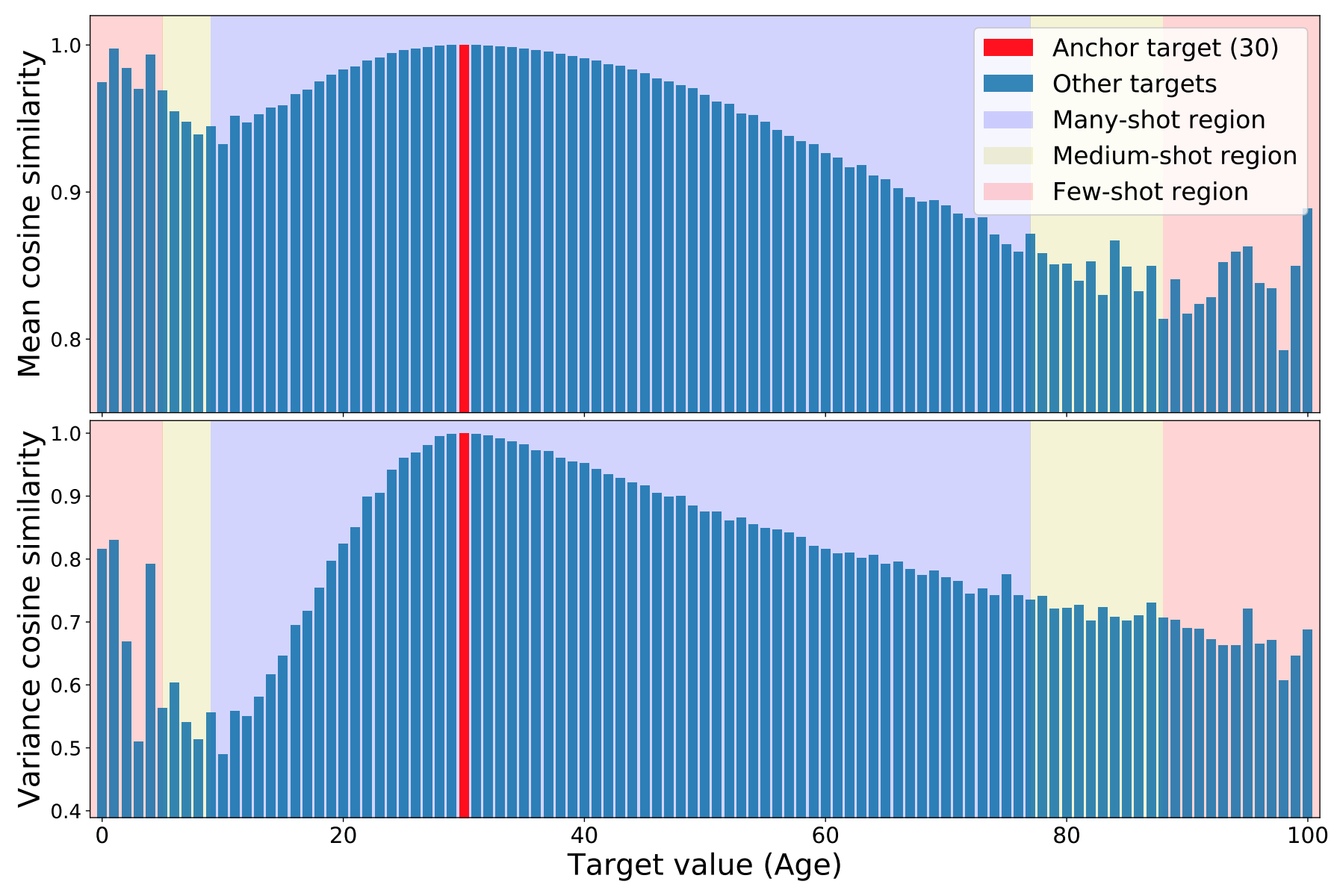
这种FDS的动机是,目标空间的连续性应该在相应的特征空间产生连续性的直觉。换句话说,如果模型工作正常且数据平衡,那么与附近目标相对应的特征的统计量应该是相互接近的。为了说明数据不平衡是如何影响DIR特征的,我们将使用一个在IMDB-WIKI数据集的图像上训练出来的模型,根据一个人的外表推断他的年龄。我们计算每个数据集的特征统计(平均值和方差),我们将其表示为{$µ_b,σ_b$}。为了直观地了解特征的相似性,我们选择某些数据并计算该特征与所有其他数据的余弦相似度。
结果显示在下图中,对于30个具有不同数据密度的区域,用紫色、黄色和粉红色表示。图中显示,30左右的特征的统计数字非常相似。特别是,25岁至35岁之间所有特征的平均值和方差的余弦相似度都在30岁时的数值的百分之几之内。因此,该图证实了这样的直觉:当有足够的数据时,或者对于一组连续的目标,特征统计是相似的。
有趣的是,图中还显示了数据样本量非常小的地区的问题,如0至6岁的年龄段(粉红色)。请注意,这个范围的平均值和方差值显示出与30岁的人意外地高度相似。事实上,令人震惊的是,30岁的特征统计数字与1岁比17岁更相似。这种不应有的相似性是由于数据的不平衡造成的。
总之,以年龄为例,近的年龄应该是相似的,远的年龄应该是不相似的!但事实是,数据是有偏见的,以至于发生了奇怪的事情。
它在FDS特征空间中进行分布平滑,在附近的目标之间移动特征统计。FDS是通过首先估计每个统计量来进行的,用协方差代替方差,以便也反映出Z中各种特征元素之间的关系,但不失为一种通用的方法。FDS是通过首先估计每个统计量来进行的,用协方差代替方差,以便在不丧失一般性的情况下也反映出Z中各种特征元素之间的关系。
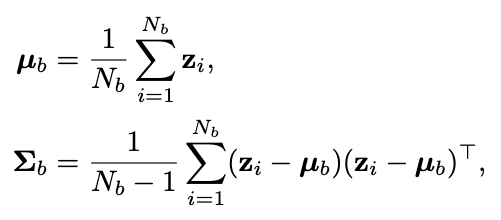
$N_b$是第2个样本数。考虑到一个特征的统计数据,我们再次采用对称核k($y_b$,$y_b'$)来平滑该特征在相关数据上的均值和协方差分布。这就产生了一个平滑的统计量版本。
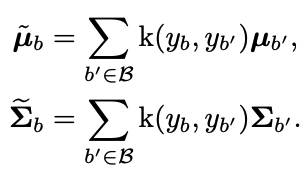
同时使用一般的和平滑的统计,然后我们根据标准的标准白化和重新着色程序对每个输入样本的特征表示进行校准。
FDS通过在最终的地物图之后插入地物校准层而被整合到模型中。为了训练模型,我们对每个历时的运行统计数据采用动量更新,相应地,平滑的统计数据在不同的历时中被更新,但在每个训练历时中是固定的。FDS可以与任何模型整合,就像以前的工作一样,以改善标签不平衡的情况。事实上,该文件表明,将该方法与其他改善不平衡问题的方法相结合,可以持续地提高性能。
DIR数据集,一个基准
在数据集DIR中,我们有五个基准:计算机视觉、自然语言处理和医疗保健。图中显示了这些数据集的标签密度分布和它们的不平衡程度。(关于数据的更多细节,请参考原始出版物)
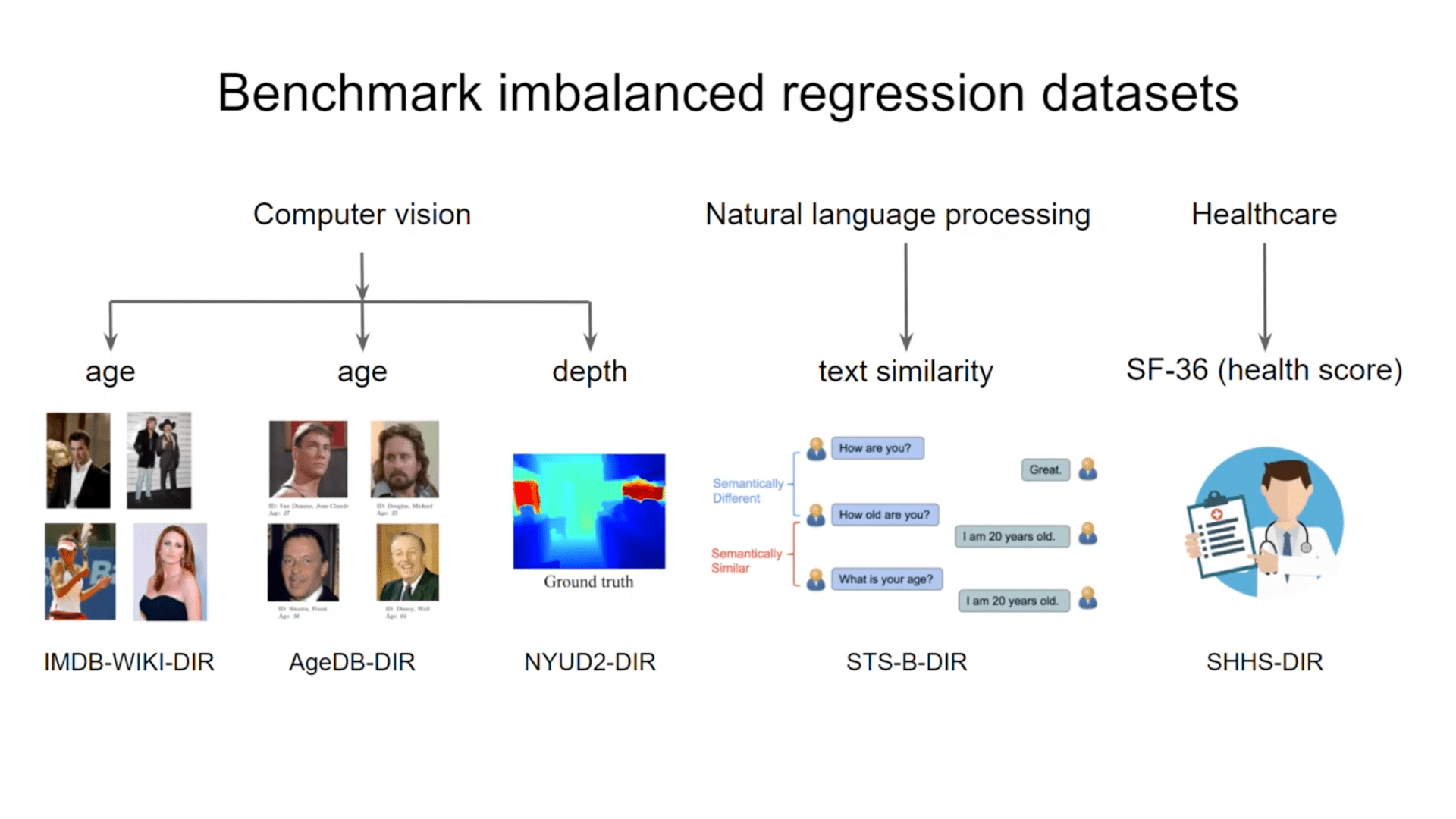

- IMDB-WIKI-DIR
IMDB-WIKI-DIR是由IMDB-WIKI数据集建立的,它包含了523.0K张人脸图像和它们相应的年龄。 - AgeDB-DIR
AgeDB-DIR是由AgeDB数据集建立的。 - STS-B-DIR
STS-B-DIR是由语义文本相似性基准构建的,这是一个由新闻标题、视频和图像说明以及从自然语言推理数据中提取的句子对组成的集合。 - NYUD2-DIR
NYUD2-DIR是由纽约大学深度数据集V2构建的。 - SHHS-DIR
SHHS数据集包含2651名受试者的整夜多导睡眠图(PSG),PSG信号包括EEG、ECG和呼吸信号(气流、腹部和胸部)。该数据集包括每个受试者的36项短表健康研究(SF-36),从中提取一般健康评分。
实验结果
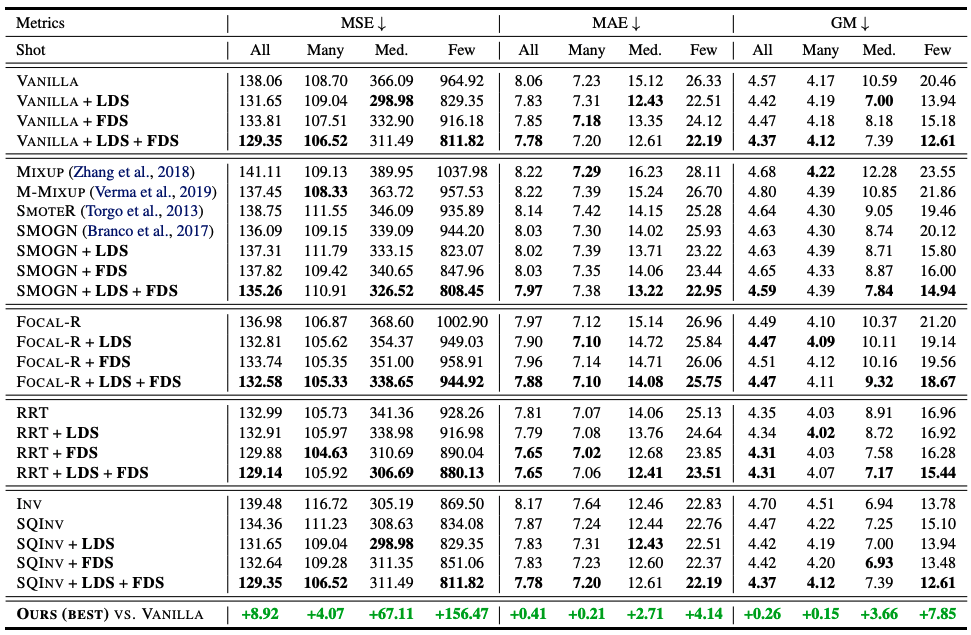
这里只显示了IMDB-WIKI-DIR的结果,这被描述为主要结果。所有结果的细节可以在原始出版物中找到。下面我们比较不同方法的结果,并将每个LDS、FDS以及LDS和FDS的组合应用于基线方法。 最后,我们报告了LDS+FDS在香草模型上的性能改进。 如表所示,无论使用哪种学习方法,LDS和FDS的表现都非常好,都有百分之几十的改进。
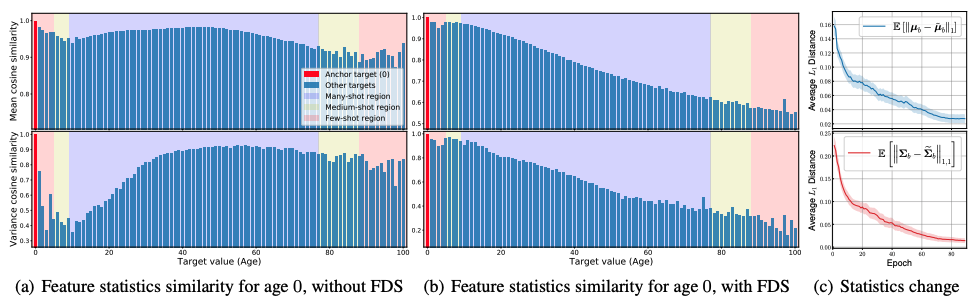
考虑因素
对FDS发挥作用的原因进行了更详细的分析。 首先是分析FDS如何影响网络的学习过程。 我们展示了基龄0的特征统计的相似性图。 可以看出,目标区间(0岁)的小样本量导致了特征统计的大偏差。例如,0岁的统计值对于40至80岁的区间也应该是类似的。
另一方面,当加入FDS后,统计数据得到了更好的校准,只有周围的区域有很高的相似度,随着目标值的增加,相似度也在下降。此外,在训练过程中,直观地看到运行统计和平滑统计之间的$L_1$距离是很有趣的:平均$L_1$距离随着训练的进行而减少,并收敛为0。这表明,在没有平滑化的情况下,该模型学会了产生更准确的特征,并最终在推理过程中给出了良好的结果,即没有使用平滑化模块。
摘要
对DIR进行了系统的研究,并相应地提出了简单有效的新方法,即LDS和FDS,以解决具有连续目标的不平衡数据的学习问题,并建立了五个新的基准,以促进未来对不平衡数据的回归研究。该文件对问题进行了非常直观的分析和解释。
事实上,本文的作者正在运行一个与医疗保健人工智能有关的独立项目。作者根据他们对连续值和非常稀疏和有偏见的标签分布的经验来定义问题,最后提出LDS和FDS。事实证明,与基线模型相比,性能可以明显提高,验证了其在现实世界任务中的有效性和实用性,并希望将该方法扩展到学术数据集之外。
然而,由于使用对称核作为未来的挑战,存在着超参数化的问题,最佳参数可能因任务而异。适当的值需要根据特定任务的标签空间来确定。然而,我认为这篇论文是为这个问题定义的一个很好的起点。



与本文相关的类别





