交叉熵是否应该用于分类任务中?
3个要点
✔️ 比较分类任务中的交叉熵损失和均方差误差。
✔️ 在各种任务上得到验证,包括自然语言处理、语音识别和计算机视觉。
✔️ 使用平方误差的模型整体表现更好
Evaluation of Neural Architectures Trained with Square Loss vs Cross-Entropy in Classification Tasks
written by Like Hui, Mikhail Belkin
(Submitted on 12 Jun 2020 (v1), last revised 4 Nov 2020 (this version, v3))
Comments: Accepted to ICLR2021.
Subjects: Machine Learning (cs.LG); Machine Learning (stat.ML)
code:
首先
分类任务中常用的损失函数是交叉熵损失(CET),而不是平均平方误差(MSE)。
这样做真的对吗?
换句话说,在分类任务中,交叉熵损失是否比MSE更有效?
在本文介绍的论文中,我们比较了自然语言处理、语音识别和计算机视觉等各种任务中的交叉熵和平方误差。结果表明,在很多情况下,使用平方误差训练的模型相当有优势,比如使用交叉熵训练的模型性能和使用交叉熵的模型一样好,甚至更好,而且方差相对于初始化的随机性很小。
实验
数据集
为了比较交叉熵和平方误差,使用了三个领域的任务:自然语言处理(NLP)、语音识别(ASR)和计算机视觉(CV)。每个实验都是在以下数据集上进行的。
NLP
- MRPC
- SST-2
- QNLI
- QQP
ASR
- TIMIT
- WSJ
- Librispeech
CV
- MNIST
- CIFAR-10
- ImageNet
建筑学
实验中采用的架构如下
NLP
ASR
CV
对于每项任务,数据集的统计结果如下所示
NLP

ASR
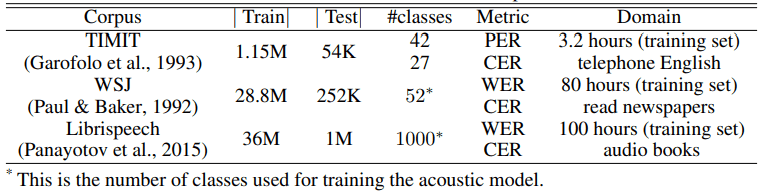
履历

实验协议
当进行交叉熵损失的训练时,当验证性能连续5个纪元没有提高时,就停止学习。当用平方损失训练时,采用以下两种方案。
- 与交叉熵损失类似,当验证性能连续5个纪元没有改善时,就会停止学习。
- 训练交叉熵损失时,训练的纪元数与纪元数相同。
后者的设计使交叉熵损失和平方损失的计算资源相同,这对交叉熵损失是一个有利的设置。此外,在下面显示的实验结果中,表示每个任务的五个不同随机初始化的实验的平均值。
实施要点
原文中给出了具体的实现细节,但最重要的几点在下文中解释。
删除softmax层
在交叉熵损失的情况下,最后有一个软max层。
当使用平方损耗时,这层会被删除。
损失重新调整
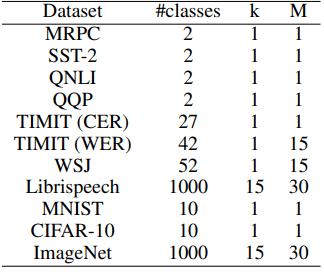
对于具有大量输出类(在我们的实验中超过42个)的数据集,我们进行损失重缩放以加快训练速度。
设$x \in R^d$为特征向量,$y \in R^C$(其中C为输出类数)为代表标签的一热向量,模型表示为$f:R^d→R^C$。
在这种情况下,通常的(对于少量的类)平方损失表示如下
$l=\frac{1}{C}((f_c(x)-1)^2+\sum^C_{i=1,i\neq c}f_i(x)^2$
另一方面,使用两个参数$(k,M)$来定义当类数较大时的损失,如下式。
$l=\frac{1}{C}(k*(f_c(x)-M)^2+\sum^C_{i=1,i\neq c}f_i(x)^2$
k=1,M=1$的情况与正常情况相同。实验中各数据集的参数和类数如下表所示。
NLP的实验结果
自然语言处理任务中交叉熵损失和平方损失的比较如下图所示。上图为准确率(ACCURACY),下图为F1得分。
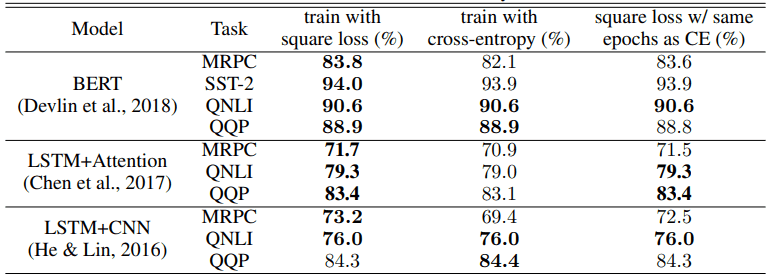
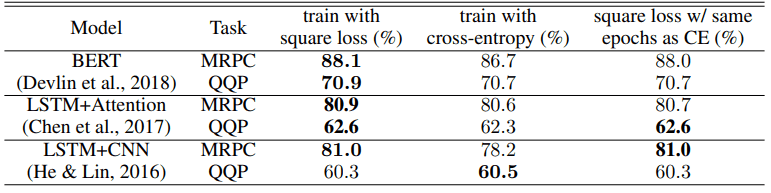
在准确率方面,在10个任务架构设置中,有9个任务架构设置的平方损失优于交叉熵,对于F1得分,在6个设置中,有5个设置的平方损失也优于交叉熵学习结果。
即使是在纪元数相同的情况下(表中最右边),对于8/10精度和5/6 F1分数的设置,平方损失也显示出更好的结果。
使用平方损失的改进取决于任务模型架构,但我们发现,除了在LSTM+CNN的情况下,平方损失提供的性能等于或优于交叉熵损失,特别是在QQP任务中。
ASR的实验结果
语音识别任务的对比结果如下。
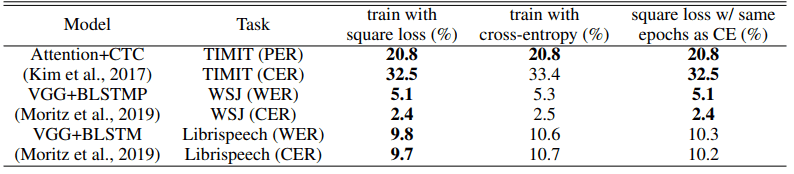
PER表示电话错误率,CER表示字符错误率,WER表示字错误率(数字越小越好)。在所有任务和模型架构设置下,平方损失与交叉熵损失相当或更好。
相对性能差异最大的是Librispeech,它在使用的数据集中数据量最大(CER为9.3%,WER为7.5%)。
对于次大的数据集WSJ,性能的提升约为4%,这意味着数据集规模越大,使用平方损失时的相对性能越高。目前还不清楚这是一个巧合,还是有一个特性,即数据集规模越大,平方损耗越好。TIMIT和WSJ的训练所需的纪元数是一样的,而Librispeech对平方损失的要求更高,但表现得更好。
CV的实验结果
计算机视觉任务的结果如下。

总的来说,平方损失往往比使用交叉熵损失时表现出相同或更低的性能。特别是,我们可以看到,当使用EfficientNet时,性能会下降。此外,对于所有三个数据集来说,训练收敛之前的纪元数几乎相同。
与NLP和ASR相比,可以说CV的平方损失并没有表现出太大的优势。
不同初始化的性能
为了评价模型初始化对随机性的鲁棒性,我们比较了用不同随机种子初始化的情况。在下图中,显示了使用平方损失和使用交叉熵损失在精度(或错误率)上的差异。
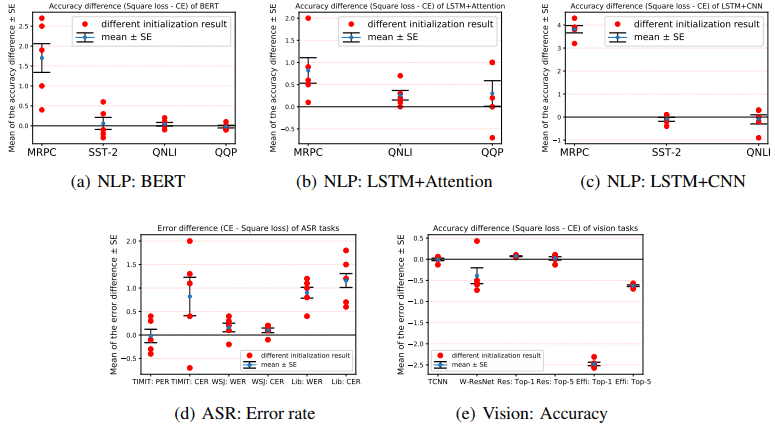
平均值用蓝色圆点表示,平均值±标准差的位置用横杠表示,试验结果用红点表示。
标准差比较的结果如下表所示。
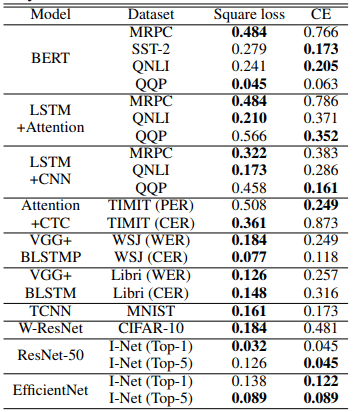
在20个设置中,方差较小的有15个设置的平方损耗。这说明使用平方损耗的情况下,受初始化的随机性影响相对较小。
学习曲线的观察
我们比较了类数少和类数多时训练的收敛速度。
类数较少时的收敛速度。
下图是QNLI数据集的学习曲线。这是一个两类分类任务,对应的类数很少。
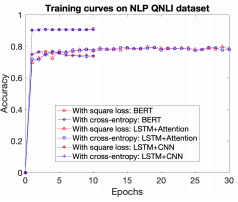
所有有平方损失的情况用红色显示,所有有交叉熵损失的情况用蓝色显示。可以看到,两种情况下的收敛速度几乎是一样的(在平方损耗的情况下,整体的精度更好)。
类数较多时的收敛速度。
接下来,作为对大量类的情况的考察,音频数据集Librespeech和视觉数据集ImageNet的学习曲线如下所示。
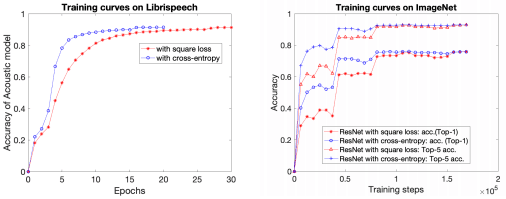
和以前一样,红色表示使用平方损失时,蓝色表示使用交叉熵损失时。在Librispeech中,使用平方损耗时,最终性能较好,但收敛速度较低。ImageNet的收敛速度也略有下降,但最终性能几乎相同。
收敛速度可能会根据任务的性质而变化,比如要解决的任务类数。
摘要
在分类任务中通常使用交叉熵损失。但是,本文的验证结果表明,在NLP、ASR和CV等各种任务中,平方损失在精度、错误率和对随机初始化的鲁棒性方面与交叉熵损失一样好,甚至比交叉熵损失更好。虽然这些结果是经验性的,但它们表明,分类任务中的平均平方误差可能与交叉熵损失一样有效或更有效。
但需要注意的是,当类数较多时,有一些结果在CV任务中的性能和收敛速度都不如交叉熵损失,所以不能说哪个总是更好。
与其在分类任务中只使用交叉熵损失作为损失函数,我们不妨考虑将平方损失作为一种选择。



与本文相关的类别






