使用ZERO-OFFLOAD,现在可以在GPU上训练大10倍的模型!
三个要点
✔️ 全新的GPU+CPU混合系统,可以在单个GPU上训练大规模模型(10x)
✔️ 高扩展性,可扩展至128+GPU,并与模型并行化整合。
✔️ 6倍速的CPUAdam优化器!
ZeRO-Offload: Democratizing Billion-Scale Model Training
written by Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, Yuxiong He
(Submitted on 18 Jan 2021)
Comments: Accepted to arXiv.
Subjects: Distributed, Parallel, and Cluster Computing (cs.DC); Machine Learning (cs.LG)



首先
自深度神经网络(DNN)模型出现以来,DNN模型的规模迅速增长,最近的GPT-3模型的参数达到了惊人的1750亿。这种规模也是GPT-3等大型机型强大的原因之一。然而,训练这些网络是困难的,也是昂贵的:要正确训练一个10B参数的模型,需要16台NVIDIA V100,成本约为5-10万。这使得许多研究人员和数据科学家对这种模型的训练成本很高。所以你可以看到,能够廉价而有效地训练DNN将是我们要克服的一个挑战。
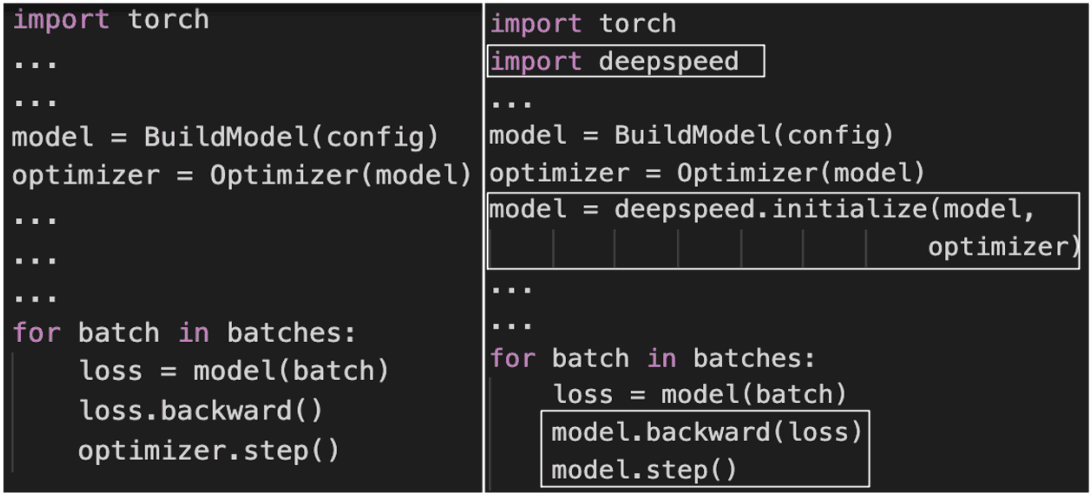 为整合ZeRO-Offload而对PyTorch代码所做的更改。
为整合ZeRO-Offload而对PyTorch代码所做的更改。
在本文中,我们介绍了ZeRO-Offload,这是一个高效、可扩展、易于使用的系统,是开源DeepSpeed PyTorch库的一部分。只需几行代码,就能在GPU上训练出多达10倍的模型。它还具有高度的可扩展性,实现了近乎线性的加速,最高可达128个GPU。此外,它还可以与模型并行化相结合,训练更大的模型。
关键概念
为了实现在GPU上训练大于内存容量的模型,已经做出了重大努力。这就需要协调模型的状态(参数、梯度、优化器状态)和残差的状态(激活、临时缓冲区、不可用的内存)进出内存。这些努力可以分为以下几类:
规模化的大规模模型训练
它指的是将一个模型在多个GPU之间进行分区,以满足内存需求。模型并行和流水线并行分别是对模型进行纵向和横向分割的技术。现代ZeRO通过消除在所有GPU上复制所有模型状态的需求,而使用通信聚合来收集训练过程中的必要信息,从而使模型并行化更加高效。
大规模模型训练的规模化
这指的是使用单个GPU来训练更大尺寸的模型。主要有三种方式。
- 如何使用低精度或混合精度的数字
- 如何通过从检查点重新计算来换取计算的内存?
- 这种方法使用CPU的内存。
ZeRO-Offload是基于第三种方法。
ZeRO-Offload的特点
介绍ZeRO-Offload的功能和工作原理。
独特的最佳卸载策略
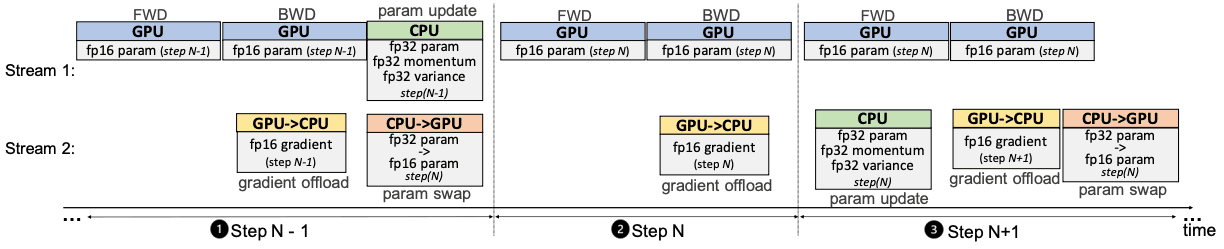
ZeRO-Offload通过将部分模型状态卸载到CPU(但不处理剩余状态)来扩展训练内存。这样做的挑战是CPU计算速度的减慢和GPU-CPU通信的开销。为了克服这些挑战,Zero-Offload将学习模型化为如下图,划分为GPU和CPU Zero-Offload能够在以下约束条件下实现给定CPU-GPU对的最优解:CPU的不成为瓶颈,CPU的负载远小于GPU,减少CPU与GPU之间的通信量,最大限度地节省内存。
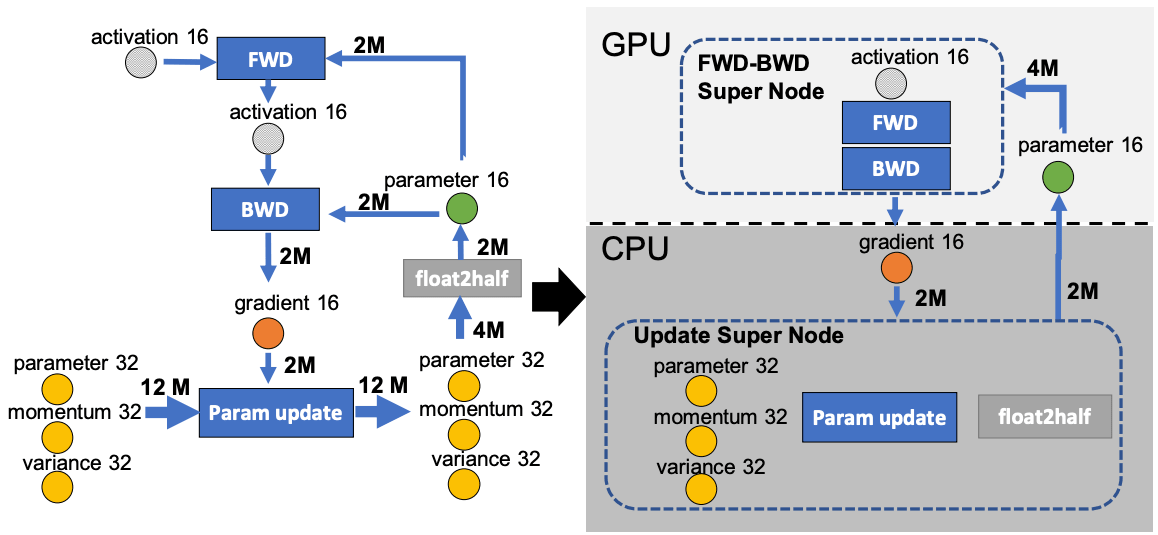 前向passe和后向passe的时间复杂度为O(model_sizeexBatch_size),在GPU上执行,称为FWD-BWD超节点。由于我们希望将时间复杂度O(model_size)的权重更新和规范计算保持在CPU上,所以我们称它为更新超节点。
前向passe和后向passe的时间复杂度为O(model_sizeexBatch_size),在GPU上执行,称为FWD-BWD超节点。由于我们希望将时间复杂度O(model_size)的权重更新和规范计算保持在CPU上,所以我们称它为更新超节点。
fp16参数存储在GPU上,fp16梯度、fp32动量、方差、参数存储在CPU上。这样就形成了一个四节点系统:FWD-BWD超节点、Update超节点、gradient16(g16)和参数16(p16)节点。
单GPU调度
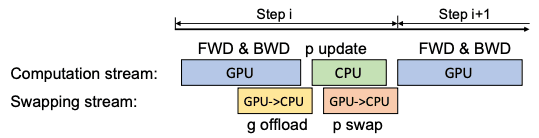 前向传递之后是损失计算和后向传递,不需要与CPU进行任何通信。计算出的梯度会立即传输到CPU,所以不需要太多的内存来存储在GPU上。梯度转移和反向传播可以重叠,进一步降低通信成本:在CPU上执行FP32参数权重更新后,将该过程复制到FP16中的GPU参数,并重复执行。
前向传递之后是损失计算和后向传递,不需要与CPU进行任何通信。计算出的梯度会立即传输到CPU,所以不需要太多的内存来存储在GPU上。梯度转移和反向传播可以重叠,进一步降低通信成本:在CPU上执行FP32参数权重更新后,将该过程复制到FP16中的GPU参数,并重复执行。
多GPU调度
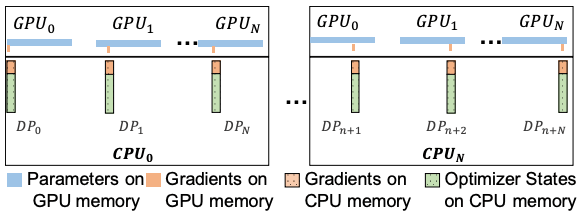 ZeRO-Offload是为了配合ZeRO支持多个GPU而设计的。具体来说,它允许你在GPU之间分割梯度。和ZeRO-2,它分割了优化器的状态。每个GPU都会保存一份参数,但需要更新一部分参数。因此,我们只保留该部分参数的梯度和优化器状态,在正向传递后,每个GPU以迷你批次更新指定的参数(每个GPU得到的迷你批次不同)。然后,来自所有GPU的更新参数将被收集、合并,并使用全收集通信的集合重新分配。
ZeRO-Offload是为了配合ZeRO支持多个GPU而设计的。具体来说,它允许你在GPU之间分割梯度。和ZeRO-2,它分割了优化器的状态。每个GPU都会保存一份参数,但需要更新一部分参数。因此,我们只保留该部分参数的梯度和优化器状态,在正向传递后,每个GPU以迷你批次更新指定的参数(每个GPU得到的迷你批次不同)。然后,来自所有GPU的更新参数将被收集、合并,并使用全收集通信的集合重新分配。
优化的CPU执行
我们还通过在CPU上并行处理数据,提出了一个快速的CPU Adam优化器。优化后的Adam使用SIMD向量指令进行硬件并行化,使用Loop unrolling进行指令级并行化,使用OMP多线程来利用多个内核和线程。
 尽管对Adam进行了优化,但当批次规模较小时,CPU上的计算负载可能会接近GPU上的负载。在这种情况下,我们使用单步延迟参数更新(DPU)将GPU和CPU重叠一步;由于梯度的突然变化,DPU跳过了初始的N-1步。这使得我们可以同时运行GPU和CPU。我们发现,经过几十次迭代后使用DPU并不会显著影响模型的准确性。
尽管对Adam进行了优化,但当批次规模较小时,CPU上的计算负载可能会接近GPU上的负载。在这种情况下,我们使用单步延迟参数更新(DPU)将GPU和CPU重叠一步;由于梯度的突然变化,DPU跳过了初始的N-1步。这使得我们可以同时运行GPU和CPU。我们发现,经过几十次迭代后使用DPU并不会显著影响模型的准确性。
实验和评估

ZeRO-Offload在训练吞吐量和最大模型大小方面明显优于Pytorch、Megator、Zero-2和L2L。此外,DPU被证明在小批量为8的情况下,可以提高每个GPU的吞吐量。
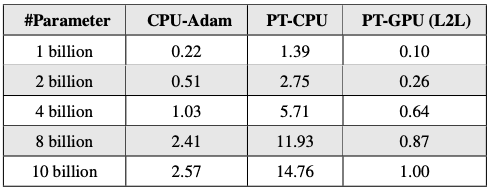
用于PyTorch(PT)和CPU的Adam延迟--亚当
CPU-Adam 与 CPU 上默认的 PyTorch Adam 实现相比,性能显著提升(最高可提升 6 倍);PyTorch-GPU Adam 速度更快,但会消耗一些 GPU 内存作为回报(这是一种不可取的权衡)。
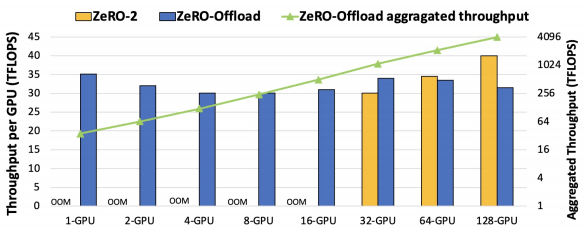
在10B参数GPT-2中,ZeRO-Offload和ZeRO-2之间的学习吞吐量。
ZeRO-Offload即使在GPU数量增加(最多128个GPU)的情况下也能保持每GPU的吞吐量。此外,还证实了即使GPU数量增加,ZeRO-2的性能也优于ZeRO-Offload。
摘要
我想ZeRO-Offload的辉煌无需多言,因为实验结果不言而喻。本文装载了高效训练深度神经网络的巧妙想法。这样一来,它让全世界数以千计的热心研究人员有机会训练具有数十亿参数的模型。该系统是开源的,并包含在DeepSpeed库中,因此可以很容易地集成到您的项目中。我建议你翻阅一下原文件,了解一下这个系统的更多信息。这里是DeepSpeed的GitHub仓库。



与本文相关的类别






