
扩散政策:机器人扩散模型!当机器人也能做披萨
三个要点
✔️ 利用扩散模型制定模仿学习
✔️ 与传统方法相比,可应对多模态和离散情况,并稳定学习效果
✔️ 在模拟和实际实验中,成功率平均提高了 46.9%。
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
written by Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, Shuran Song
(Submitted on 7 Mar 2023 (v1), last revised 1 Jun 2023 (this version, v4))
Comments: Project website: this https URL
Subjects: Robotics (cs.RO)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
在机器人学习领域开展了多种类型的研究,其中最活跃的研究方法之一是模仿学习。模仿学习是一种从专家(如实际操作机器人的人类)获得的数据中学习策略的方法。与其他方法相比,模仿学习具有很多优点,比如不需要强化学习中的奖励设计,而且如果使用实际机器人的演示数据,也不会出现仿真问题。本文介绍了模仿学习的最新方法研究,与传统方法相比,这些方法的性能有了显著提高。
原始论文的作者有一个网站,在那里你可以看到机器人的动作和所用方法的图片。
现有研究和问题
基于模仿学习的方法难以解决以下两个问题
不连续性和多重模式
下图显示了机械臂分离黄色和蓝色积木并将其放入各自目标的任务。
离散性指的是需要离散地切换行动序列的情况,在这种情况下,离散性对应于每次都要切换目标的任务特征。多模式指的是有多种实现目标的方法。在这项任务中,要移动的方块可以是蓝色或黄色的,实现目标的过程可能有多种。

隐性政策及其问题
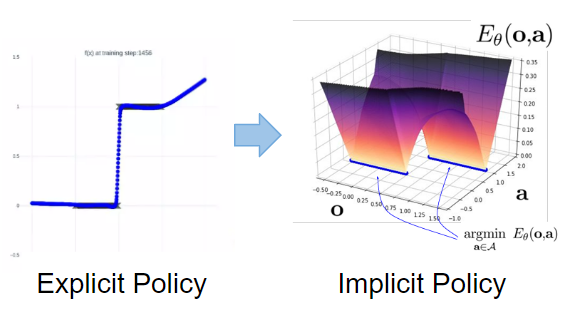
隐式策略是解决这一问题的方法。以前的方法被称为显式策略,由于策略 $\boldsymbol{a} = F_{\theta}(\boldsymbol{o})$和观察与行动之间的关系是用连续函数表示的,因此无法处理上述两个问题。
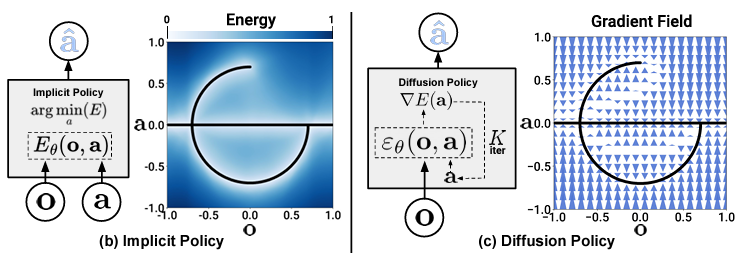
相反,隐式策略定义了一个基于能量的模型(EBM),$\boldsymbol{a}=\underset{\boldsymbol{a}}{\mathrm{argmin}} \hspace{2pt}E_{\theta}(\boldsymbol{o}, \boldsymbol{a})$。如下图所示,"显式策略"(Explicit Policy)试图用一个连续的模型去接近一个人给出的轨迹,而 "隐式策略"(Implicit Policy)则决定采取最小化 EBM 的行动,并且能够处理离散性和多模态问题。如下图所示,隐式策略能够应对离散性和多模态性。
然而,"隐式策略 "也面临着一个挑战:学习并不稳定。确定行动的概率表示为 $p_{\theta}(\boldsymbol{a}|\boldsymbol{o}) = \dfrac{e^{-E_{\theta}(\boldsymbol{o}, \boldsymbol{a})}}{z(\boldsymbol{o}, \theta)}$,其中 $z(\boldsymbol{o}, \theta)$是损失函数。损失函数表示为 $L_{infoNCE}=-\mathrm{log}\left(\dfrac{e^{-E_{\theta}(\boldsymbol{o}, \boldsymbol{a})}}{e^{-E_{\theta}(\boldsymbol{o}, \boldsymbol{a})} + \color{red}{\sum_{j=1}^{N_{neg}}} e^{-E_{\theta}(\boldsymbol{o}, \tilde{\boldsymbol{a}}^j)}}\right)$ 的计算方法如下。
然而,$z(\boldsymbol{o}, \theta)$是一个采样近似值,这对学习来说是一个不稳定因素。
更多详情,请参阅本文!
建议方法
提出 "扩散政策 "是为了应对这些离散性和多模态性,并稳定学习。
传播政策
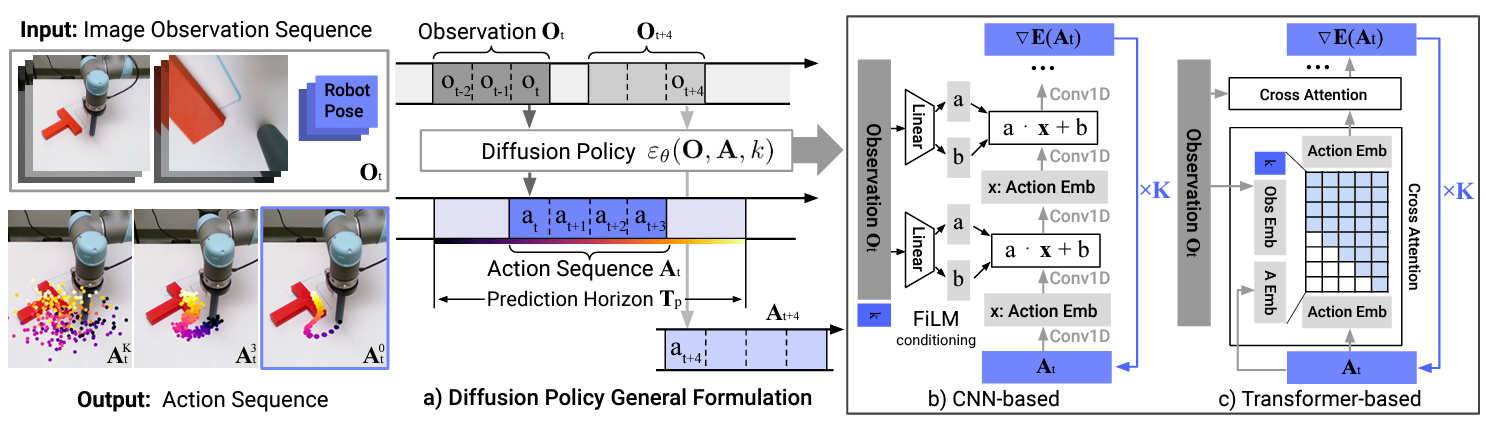
利用 Difusion 模型,其计算公式如下
![]()
基于扩散过程,$\boldsymbol{A}_t^K$ 被分散,然后去除噪声。最后生成机器人的行动轨迹 $\boldsymbol{A}_t^0$(下图左侧)。该系统是一个预测闭环系统,其流程是每隔一定时间获取一个观测序列,然后生成一个动作序列。这有助于实现平滑的控制序列和对干扰的鲁棒性(下图中心)。动作生成架构已通过 CNN 和 Transformer 验证(下图右侧)。
数学背景
它解释了为什么 "扩散政策 "公式能有效地处理离散性和多模态性,并稳定学习。
首先,在扩散过程中学习噪声的过程可被视为等同于估计分数的过程。(更多详情,请参见此处)
)%7D_%7B%5Ctext%7B%E3%82%B9%E3%82%B3%E3%82%A2%7D%7D%20%2B%20%5Cunderbrace%7B%5Csqrt%7B%5Cepsilon%7D%7D_%7B%5Ctext%7B%E3%83%8E%E3%82%A4%E3%82%BA%7D%7D%20%5Cboldsymbol%7Bz%7D_t%24&f=c&r=300&m=p&b=f&k=f)
然后,在当前问题设置中考虑这个分数,它可以表示为隐式策略中出现的行动生成概率的对数概率的导数 $\nabla_{\boldsymbol{a}} \mathrm{log} \hspace{2pt} p(\boldsymbol{a}|\boldsymbol{o})$ 。此时,得分可以表示为
而必须由样本逼近的项可以计算出来,这样就不需要计算这些项,从而稳定了学习效果。
下图显示了 "隐含政策 "与 "扩散政策 "之间的对应关系,后者考虑的是类似于 "隐含政策 "的梯度场。
特殊性
考虑到数学背景,检查是否确实获得了所需的特性。
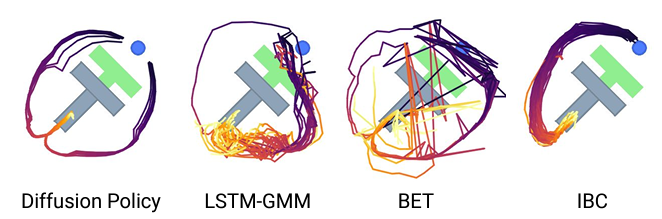
下图显示了机械臂将 T 型块移动到目标位置和方向的轨迹。在这种情况下,机器人可以从左侧或右侧向 T 型块移动,因此有两种可能的解决方案,但只有扩散策略能够为左右两侧生成相同的轨迹,这证明了它处理多模态问题的能力。
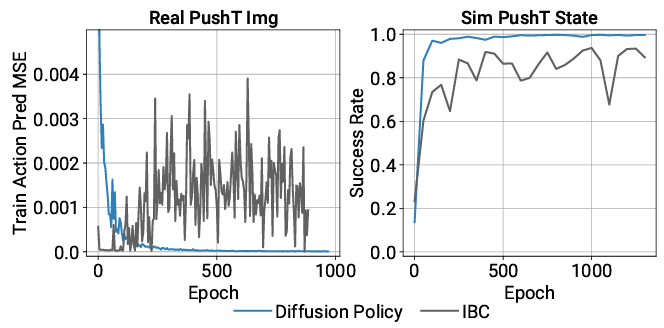
下图显示了推 T 型块任务学习过程中的动作预测误差和任务成功率,其中 IBC(隐含策略)在学习过程中不稳定,而扩散策略在学习过程中稳定,显示了不使用样本近似的优势。不使用样本近似法的优势是什么?
试验
我们使用扩散策略进行了模拟和实际实验。在这里,操作是指机器人爪子的位置和速度指令,观察是指嵌入机器人的关节信息和图像信息。您可以通过本网站的视频更好地了解它。
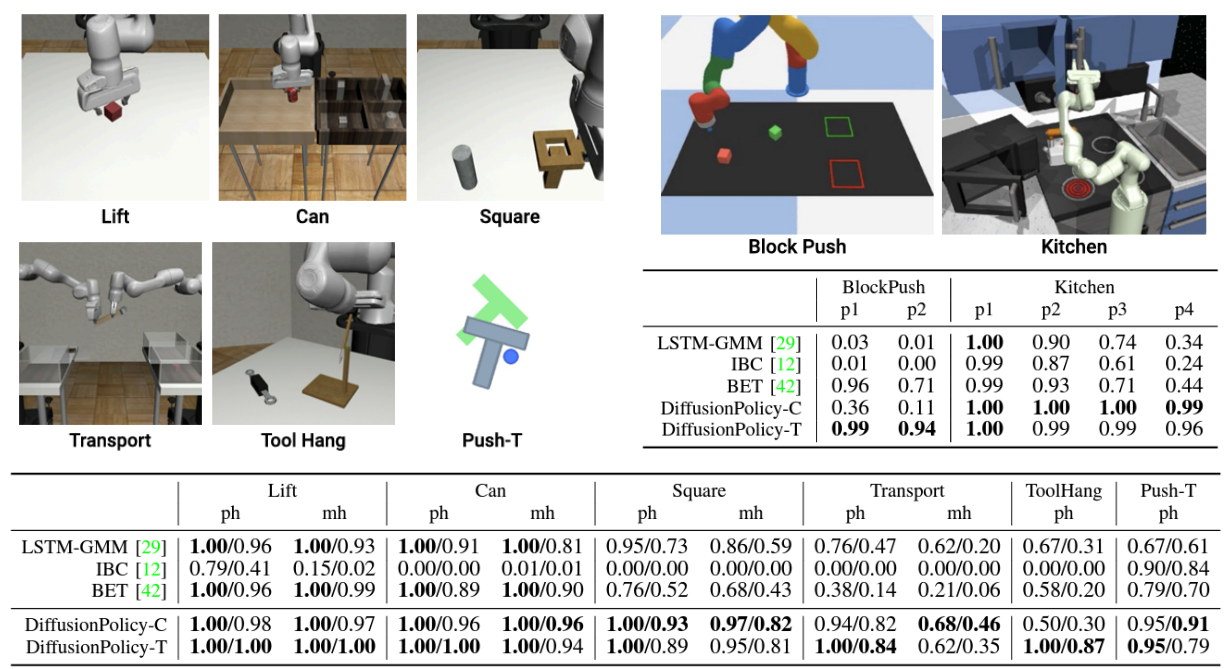
模拟实验
在各种模拟环境和任务中与传统方法进行了比较。任务和结果示例如下。传统方法的结果表明,每个学习过程都采用了性能最好的方法,但扩散策略在所有任务中的表现都明显优于传统方法,成功率平均提高了 46.9%。
野外实验
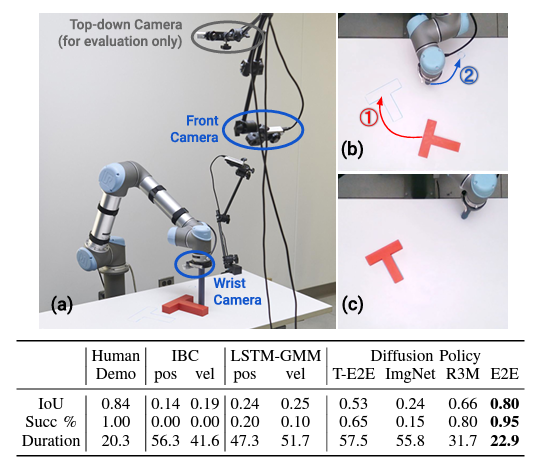
在此介绍我们正在进行的两项实验。
在将 T 型连接块移动到目标位置和方向的任务中,成功率达到 95%,远远超过传统方法(见下图)。视频显示,该策略非常稳健,即使摄像头被人挡住,也不会有任何轻微移动,而且即使移动了区块,也能立即修正到目标位置和方向。
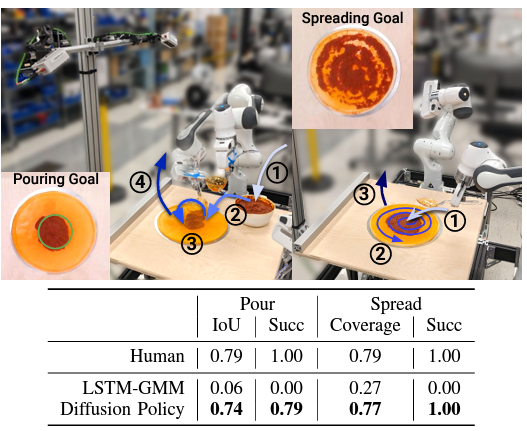
它甚至可以尝试制作披萨。在这种非刚性和流动性任务中,扩散策略表现出了与人类类似的性能。传统方法的成功率接近 0%,无法将一系列动作演示数据分离成离散的动作序列(左①-④),而 Diffusion Policy 能够分离动作序列,并取得很高的成功率。
摘要
本研究提出了使用扩散模型的扩散政策,以解决显式政策的离散性和多模态性问题以及隐式政策的不稳定学习问题。其数学背景也已存在,并已证实前述问题确实得到了解决。此外,还进行了从模拟到实际条件的各种实验,结果明显优于以往的研究。
我个人认为,除了 "隐含策略 "学习稳定化的数学方面之外,扩散模型的高表现力也是取得如此成绩的原因之一。我觉得我们正在接近一个像科幻小说一样的世界,我曾以为这只是一个梦想,我期待着它在未来的进一步发展。



与本文相关的类别

![[PIDM] 物理正则化扩散模型](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/September2024/pidm-520x300.png)
![[LDDGAN]用于最快推理的扩散模型](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/September2024/lddgan-520x300.png)

![[MusicLDM] 低剽窃风险的文本到](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/January2024/musicldm-520x300.png)
![AudioLDM]使用潜在扩散的文本到音](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/January2024/audioldm-520x300.png)
![[CoDi]可处理几乎所有模式的任意扩散](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/December2023/composable_diffusion-520x300.png)