
基于GAN的图像生成方法,彻底改变了注释数据集的生成。
三个要点
✔️ DatasetGAN是一个生成详细注释图像的工具。
✔️ 人类只需要给极少量的图像(16张图像)分配详细的注释,就可以生成无限多的注释数据集。
✔️ 对生成的图像进行半监督学习,取得了与完全监督学习相当的性能。
DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort
written by Yuxuan Zhang, Huan Ling, Jun Gao, Kangxue Yin, Jean-Francois Lafleche, Adela Barriuso, Antonio Torralba, Sanja Fidler
(Submitted on 13 Apr 2021 (v1), last revised 20 Apr 2021 (this version, v2))
Comments: Accepted to CVPR 2021 as an Oral paper
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍。
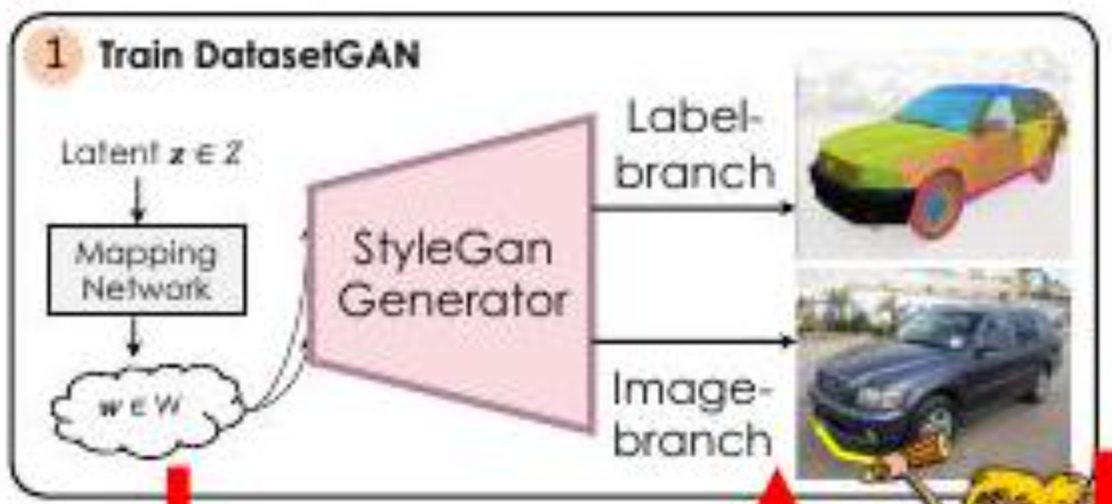
本文的核心内容在导言中提出。如上图所示,StyleGAN生成了分割的图像和正常的图像(汽车)。本文的论点是,这允许 "生成无限数量的注释图像,然后可以用来对这些数据集进行分类、识别等"。
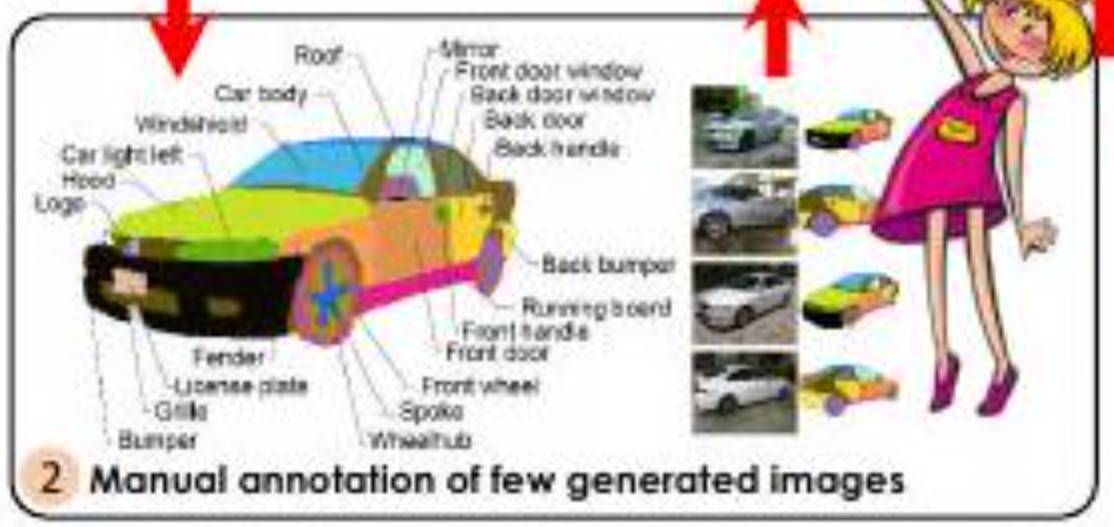
此外,只需要少量的人工注释。在本文中,只对16幅图像进行了注释,并成功生成了注释图像。
此外,如上图所示,注释是详细的。注释被分配给汽车的每个部分(前灯、泵车、格栅等)。分配这样详细(高质量)的注释需要时间和人力(即金钱)。本文重申了节省时间、人力和金钱的好处。
没有或很少注释的常见解决方案
如何使用数据综合
使用3DCG创建注释图像(数据集)的研究和用生成对抗网络(GAN)生成数据集的研究是已知的。此外,本研究也使用了GANs,但以前的研究假设有一个大型的标记数据集。
半监督学习
当使用分割网络时,这个网络可以被认为是注释的生成器。该网络通过少量的监督(手动注释)来学习更好的分割。然后,这可以被用于未注释的图像,以获得伪标签(伪分割)。
它与本文类似,生成了一个分割图像,但主要区别在于源图像。在以前的研究中,必须准备一个未标记的源图像,而在本研究中,甚至该图像也已生成。
对比性学习
对比学习是一种无监督的学习方法,用于学习一对图像是否相似。例如,一个图像被分成两部分,然后被视为一对。由于原始图像是相同的,这对图像被认为是在同一类别中。反之,由两张随机选择的图像组成的一对被认为是属于不同的类别。在对比学习中,图像特征是通过学习成对的图像是否属于同一类别而获得的。
对比度学习可以通过进一步微调(微调)图像段(斑块)或用注释图像来应用于分割任务。
本研究的拟议方法。
什么是StyleGAN?

在本文中,StyleGAN被用来生成图像及其分割图像(=注释图像)。为了便于理解,首先对StyleGAN进行描述。
GANs通过让两个模型相互竞争来完成一项特定的任务(在这里是指图像生成):这两个模型分别是生成图像的模型(生成器)和检测图像是否生成的模型(判别器)。通过让这两个人竞争,生成器将产生更真实的图像,即不能被检测为生成的图像。
一个由正态分布产生的随机数组成的向量(潜变量)被输入到发生器。在本文中,这被写成$z\in Z$。这个向量被反复转换,最后的结果是一个代表图像数据的张量。
潜变量$z$通过被输入到一个称为映射函数的网络(CNN或MLP)进行转换。这个转换后的向量被称为中间潜变量$w$。更确切地说,发生器的输入是$w$,随后的上采样过程被称为发生器。
将向量(张量)上采样到所需的大小,用$S$来表示。
到目前为止,这只是对生成器的一个概述;在StyleGAN中,还有$k$的方式可以将$z$转化为$w$。由此产生的$k$向量$w_{1}, w_{2}, w_{3}, 穴位, w_{k}$被称为Style。因此,从$k$风格中产生了$S_{1}, S_{2}, S_{3}, \dots, S_{k}$的上采样张量。
该方法的关键点
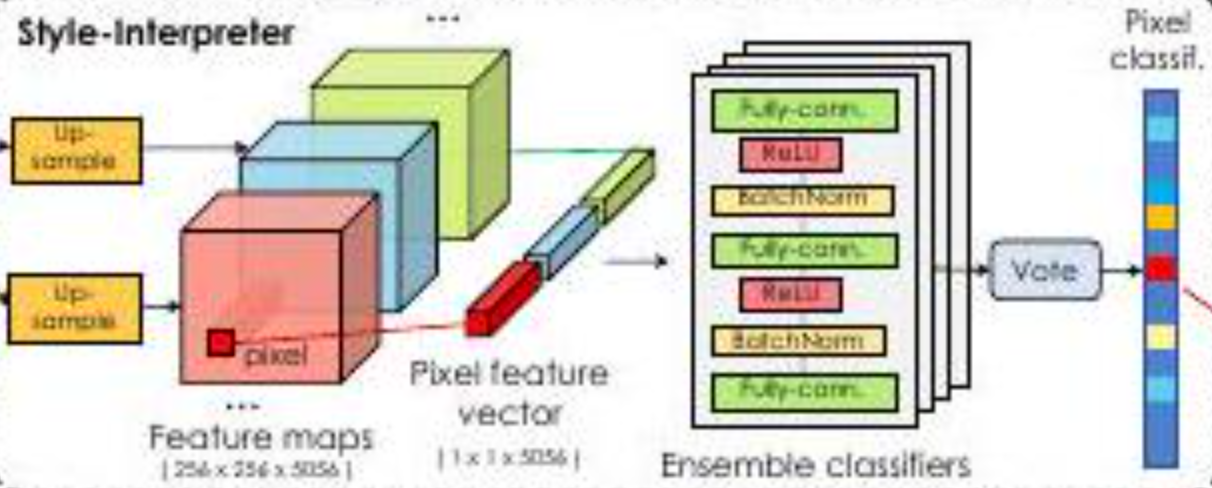
该论文指出,"潜变量被视为图形(GRAPHICS),StyleGAN被视为渲染引擎"。换句话说,作者认为,潜变量定义了 "那里有什么样的物体",而StyleGAN定义了 "它看起来像什么"。另外,简单地把潜伏变量看作是主体,把StyleGAN看作是相机,可能会更容易。
因此,作者认为由此产生的$S_{1}, S_{2}, S_{3}, 穴位, S_{k}$有(或应该有)控制物体如何被看到的维度。
然后$S_{1}, S_{2}, S_{3}, \dots, S_{k}$在深度方向上连接起来,得到一个三维张量(图中特征图部分)。然后,聚焦于一个特定的像素,得到一个深度方向的向量。这被称为像素特征向量,用$S_{i,*}$表示。这意味着对应于每个像素的部分(=像素特征向量)被提前从未来将成为图像的特征图中提取出来。
然后,像素特征向量被输入MLP,它由三层组成。然后,它通过与实际生成的图像进行比较,学习哪个像素的特征向量对应于哪个像素。通过这种方式,它学会了哪个像素对应于哪个类别,并为整个图像生成了一个分割图像。
图像生成中的损失函数。
分割失败特别明显的是噪音(一个类别的像素与另一个类别的像素混合在一起,没有创建由特定类别组成的分区)。
为了评估这种标记失败,引入了Jensen-Shannon(JS)发散(以下简称$D_{JS}$)。
$$D_{JS}(P|Q)=\alpha D_{K L}(P|M)+\alpha D_{K L}(Q|M), $$
$$M = Α(P+Q),$$
$$D_{KL}(P\|Q)=-\sum_{x\in X} P(x)\log\frac{Q(x)}{P(x)}, $$
$$P_{(x)}=p(X=x),$$
$$Q_{(x)}=p(X=x\mid a)$$。
$D_{KL}$是Kullback-Leibler分歧(KL信息含量),它评估了概率分布的相似性。$D_{JS}$是其改进版。在本文中,JS发散被用来评估合成图像的不确定性。
 上图是由DATASETGAN合成的图像的一个例子。它显示了合成图像及其分割的高质量(尽管事实上,人的额头上没有皱纹,猫的身体上也有未分割的部分。(老师的数据并没有这样做)。
上图是由DATASETGAN合成的图像的一个例子。它显示了合成图像及其分割的高质量(尽管事实上,人的额头上没有皱纹,猫的身体上也有未分割的部分。(老师的数据并没有这样做)。
与人类注释的比较。
这一次,与一位有经验的注释者(使用LabelMe)进行了比较。生成的图像包括卧室、汽车、人头(脸)、鸟和猫。
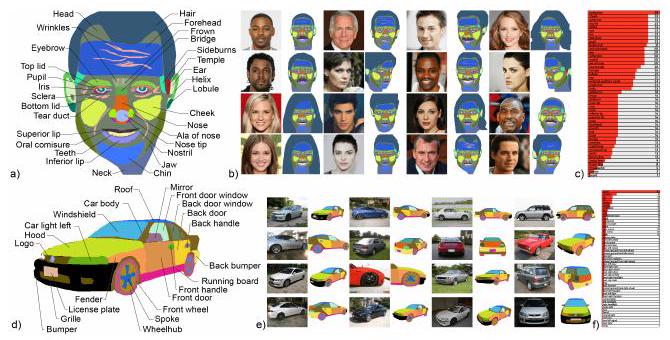
部位学是一种树状结构,显示物体各部分之间的关系。例如,在人脸的情况下,"鼻子 "是 "头 "的一个分支,"鼻尖 "和 "鼻孔 "从 "头 "中产生。上图是一个可视化的部分自治的例子。
每个类别的伙伴都是手工定义的,并尽可能详细。在头部的情况下,平均有58个部分被注解。试图对这些部件进行手工注释,每件需要大约20分钟。然而,使用这种方法,DatasetGAN每件只需要大约9秒。
用简单的算术方法,手动注释1万张图片大约需要4个月(134天):如果你每天注释8个小时,你将需要一年多的时间。使用DatasetGAN,这只需要25小时。
更令人惊讶的是,Style-Interpretor的训练实际上只用了16张头像、16张汽车、30张鸟、30张猫和40张卧室的图片就完成了。如果我们限制自己只对人脸进行注释,我们现在可以在大约5个小时的注释工作中产生一个无限的数据集(反过来说,这就是它所基于的StyleGAN的训练模型的好坏)。

生成了鸟、猫和卧室的图像。与人头相比,类的数量很少,但注释本身更困难,所花的时间也比人头长。
对生成的图像进行评估
使用的模型。
分割是在一个叫做Deeplab-V3的模型上进行的,这是一个以ResNet151为骨干的分割网络;ResNet151已经在ImageNet上训练过,此外,整个Deeplab-V3是在DatasetGAN生成的图像上训练的。
用于比较的模型。
比较......过渡期的学习。
作为比较,我们使用了已经用MS-COCO训练过的Deeplab-V3。在这个模型中,只有最后一层用人脸、猫、鸟等的数据进行调整(微调)。在这种情况下,训练数据是由人类注释的。
半监督学习的比较。
对于半监督学习,参考文献[41]中的模型(Semi-Supervised Semantic Segmentation with High-and Low-level Consistency)被用来比较。参考文献[41]也报告了一个基于GAN的分割任务,并提出了一种通过使用两个GAN来减少分割噪音的方法。
ImageNet的预训练权重被用于该模型。该模型使用人类标注的教师数据和StyleGAN训练的相同的未标注数据(不是DatasetGAN合成的图像,而是DatasetGAN中Style-Interpretor用于预训练的图像)进行训练。(这些不是由DatasetGAN合成的图像,而是由DatasetGAN中的Style-Interpretor用来进行预训练的图像)。
完全监督的学习
在几个数据集上对Deeplab-V3进行完全监督的训练。
结果。
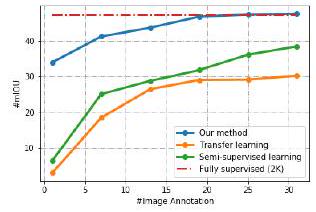
上图显示了使用名为ADE-Car12的汽车图像数据集的结果。横轴是用于训练的图像数量(以千计),纵轴是平均IOU。
红色虚线是完全监督学习,蓝色是本文提出的方法。绿色的是半监督学习,橙色的是过渡学习,这表明它比提出的方法的表现要好于比较的半监督学习和过渡学习。
更有趣的是,当用超过20,000张卡片进行训练时,其性能可与完全监督学习相媲美。

该表显示了不同数据集的结果。在任何情况下,都可以看出,所提出的方法优于其他方法。
结论。
本文介绍了用于数据集生成的DatasetGAN。
DasetGAN表明,通过使用StyleGAN特征图,可以从少量的人工注释中学习到有效的分割任务。这使得大型注释数据集可以被合成。
事实证明,在DatasetGAN中用合成图像进行训练,比一般的过渡学习和不使用合成图像的半监督学习模型的表现更好。此外,几个测试数据集显示,当用DatasetGAN增加训练数据的数量时,其性能可与完全监督学习媲美。



与本文相关的类别






![OmniGen] 只需一个生成模型就能完](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/September2024/omnigen-520x300.png)